Plan What You Can, Learn What You Must: Interleaving Planning and Learning for Multi-Robot Manipulation
Yorai Shaoul
February 11, 2026
Thesis Committee
- Maxim Likhachev, Co-Chair
- Jiaoyang Li, Co-Chair
- Andrea Bajcsy, CMU
- Yilun Du, Harvard University




The Inevitability of Multi-Arm Systems
- Plethora of applications, spanning
- Welding
- E-commerce package handling
- Cooking
- Bio-lab automation
- Construction
- Assembly
- Cleaning
- ...
- Falling hardware costs
YouTube: DanielLaBelle


Lead to a Future of Autonomous Collaborative and Cooperative Manipulation


Lead to a Future of Autonomous Collaborative and Cooperative Manipulation
We want to enable systems with
- Multiple robots
- Shared or parallel objectives
- Shared workspace
- Contact-rich interactions
- Variable team sizes and planning
horizons

The Two Dominant Paradigms
Planning
Learning

\mathcal{I}
a
Mobile Aloha
The Two Dominant Paradigms
Planning
-
Advantages:
- Scales with robots and task horizon
-
Theoretically guarantees "generalization"
-
Disadvantages:
- Requires explicit models
- Resolution depends on discretization
Learning
-
Disadvantages:
- Data hungry
-
Poor out of distribution performance
-
Advantages:
- No explicit models--only data
- Naturally produce fine motions
\mathcal{I}
a
The Two Dominant Paradigms
Planning
Learning
\mathcal{I}
a
-
PerAct [Shridhar 2022]
-
VLP [Du 2025]
-
DG-MAMP [Parimi 2025]
-
MOSAIC [Mishani 2026]
-
RT-1 [Brohan 2022]
-
Diffuser [Janner 2022]
-
Diffusion Policy [Chi 2023]
-
RT-2 [Zitkovich 2023]
-
ACT [Zhao 2023]
-
UMI [Chi 2024]
-
MPD [Carvalho 2024]
-
\(\pi_0\) [Physical Intelligence 2024]
-
DP3 [Ze 2024]
-
\(\pi_{0.5}\) [Physical Intelligence 2025]
- Gemini Robotics [2025]
- Gemini Robotics 1.5 [2025]
\vdots

-
A* [Hart 1968]
-
D* [Stentz 1994]
-
PRM [Kavraki 1996]
-
RRT [LaValle 1998]
-
RRT-Connect [Kuffner 2000]
-
D* Lite [Koenig 2002]
-
CHOMP [Ratliff 2009]
-
RRT* [Karaman 2011]
-
STOMP [Kalakrishnan 2011]
-
TrajOpt [Schulman 2014]
-
CBS [Sharon 2015]
-
dRRT* [Shome 2019]
-
MAPF-LNS [Li 2022]
\vdots
For multi-robot systems,
much less work has been done at the boundary between planning and learning.
Thesis Hypothesis
We can enable multi-arm manipulation if we
plan what we can model, and learn what we cannot.
To capitalize on the complementary strengths, establish algorithms that:
- Plan to solve structured subproblems
-
Learn only what is necessary
- When objectives are implicit or models are missing
Thesis Roadmap
Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation
Plan what we can, and learn what we must.
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
Multi-Robot-Arm Motion Planning
Based on
- "Accelerating Search-Based Planning for Multi-Robot Manipulation by Leveraging Online-Generated Experiences,"
Shaoul*, Mishani*, Likhachev, and Li, ICAPS 2024 - "Unconstraining multi-robot manipulation: Enabling arbitrary constraints in ecbs with bounded sub-optimality,"
Shaoul*, Veerapaneni*, Likhachev, and Li, SoCS 2024



Multi-Robot-Arm Motion Planning
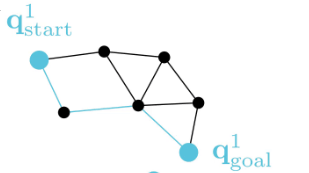
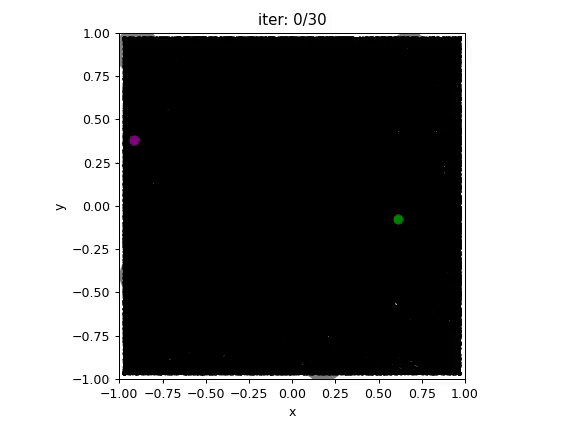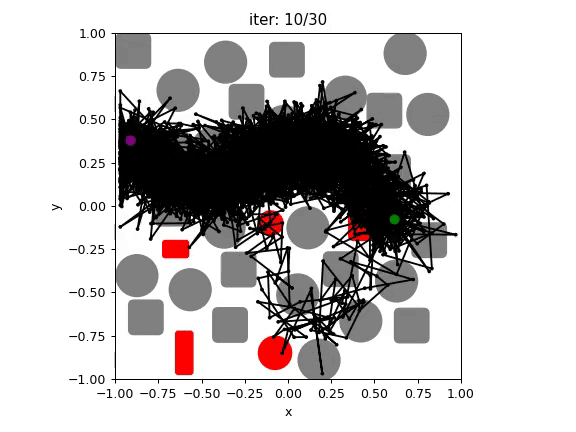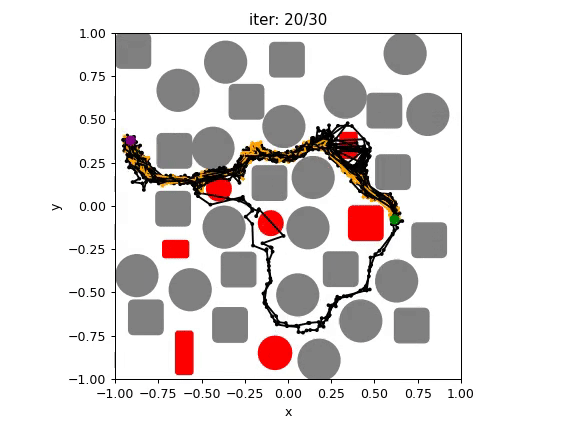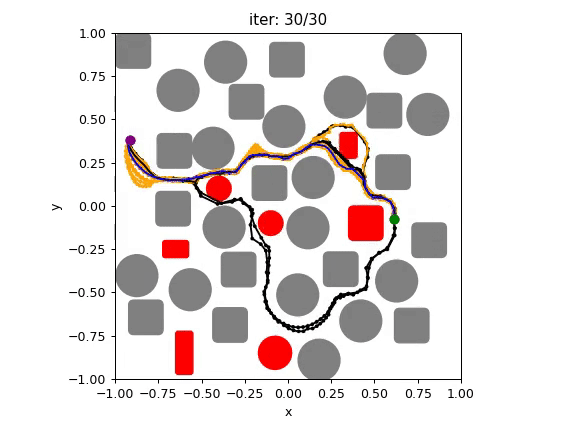
Our goal: find a collision-free solution for all arms that minimizes an objective (sum of costs).
Multi-Robot-Arm Motion Planning (M-RAMP)
The common approach: directly apply your favorite popular motion planner!
4-Robot Bin-Picking
8-Robot Shelf Rearrangement
Sampling in high dimensions
(56 DoF for 8 arms) is hard!
Kuffner, J.J. and LaValle, S.M. RRT-connect: An efficient approach to single-query path planning. ICRA 2000.
Kavraki, L.E., Svestka, P., Latombe, J.C. and Overmars, M.H. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. T-RO 2002.


Multi-Agent Path Finding algorithms are known for their scalability, can they help?
Backgound: Multi-Agent Path Finding (MAPF)
Recently, exciting work MAPF, a simplified abstract planning problem, has shown impressive results.

Check out the work at
!
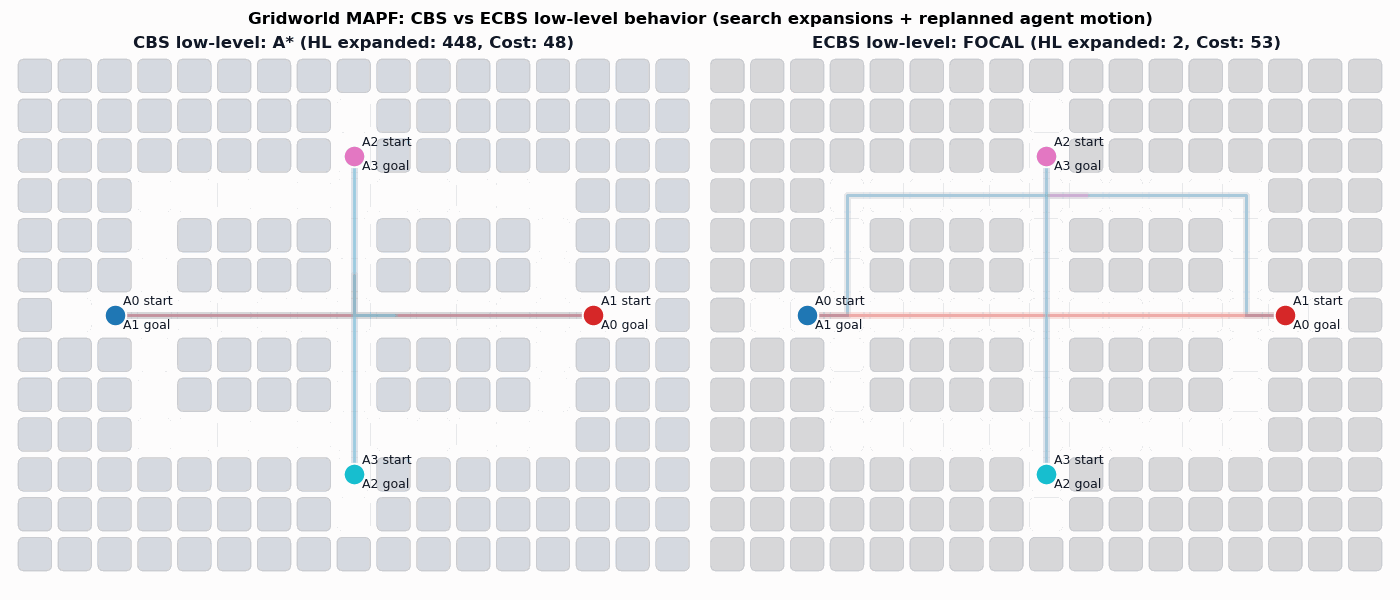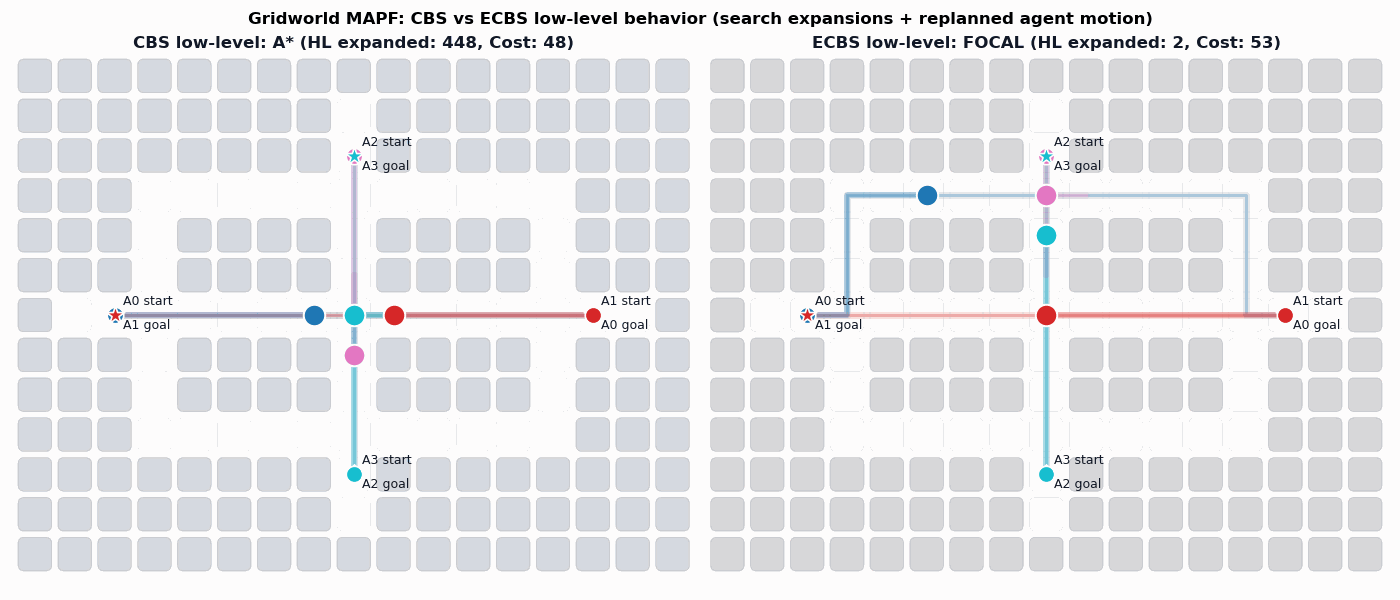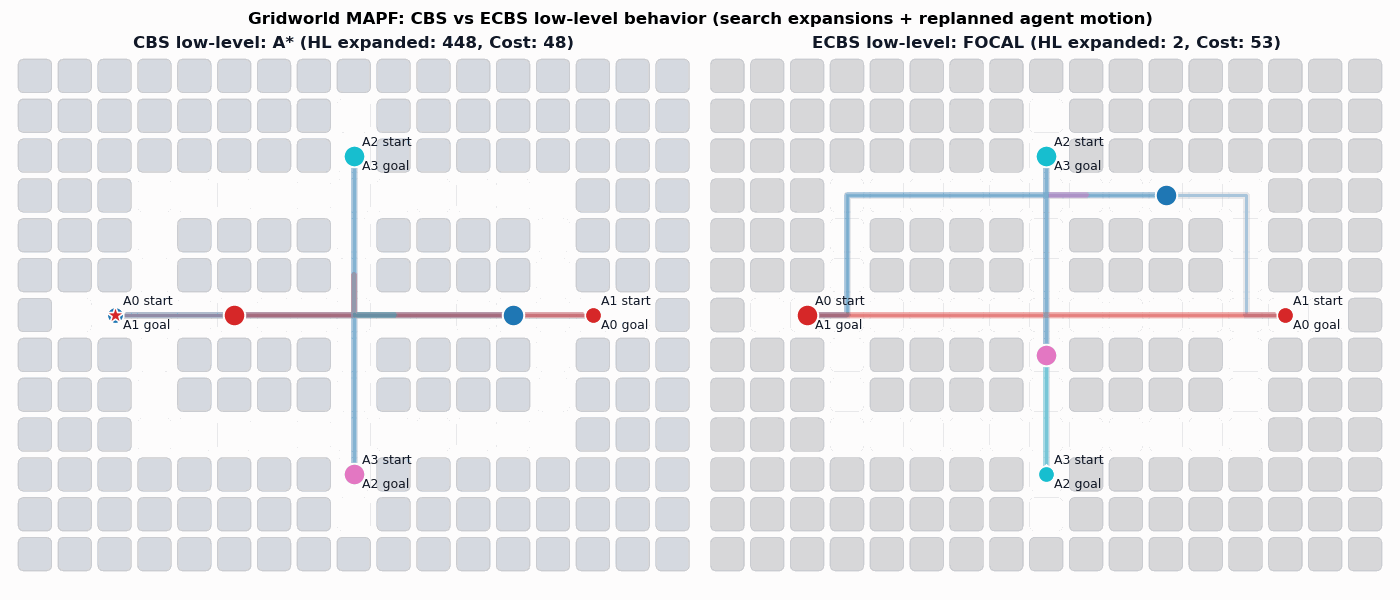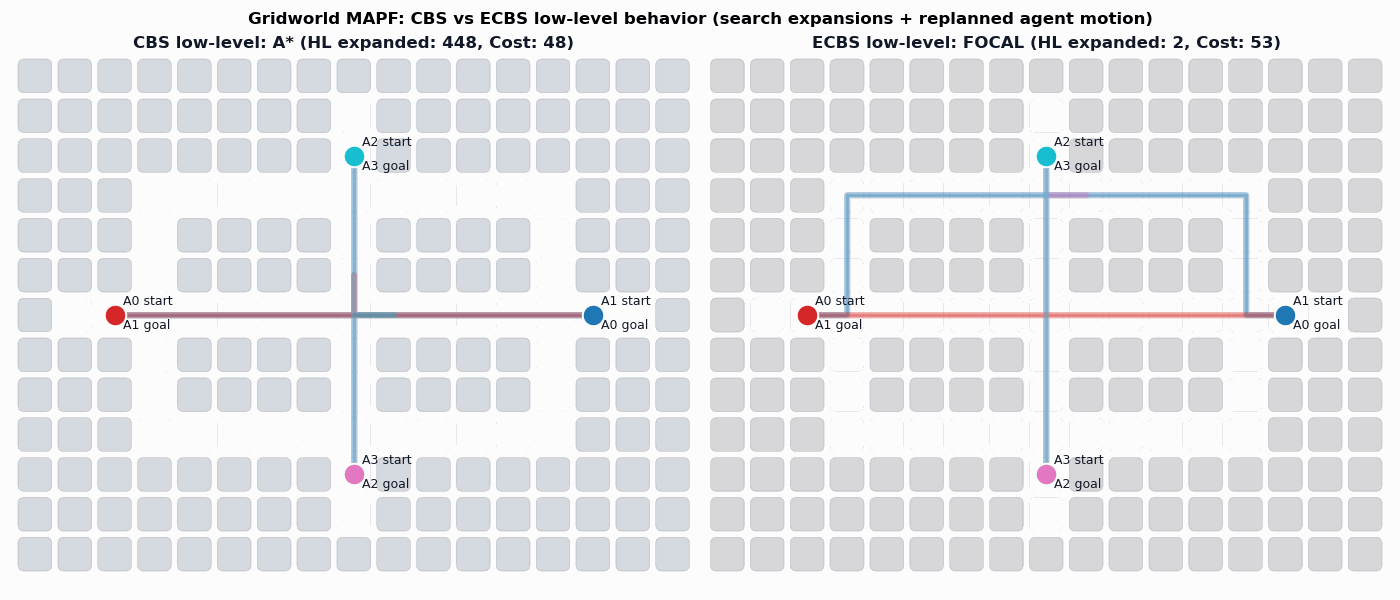
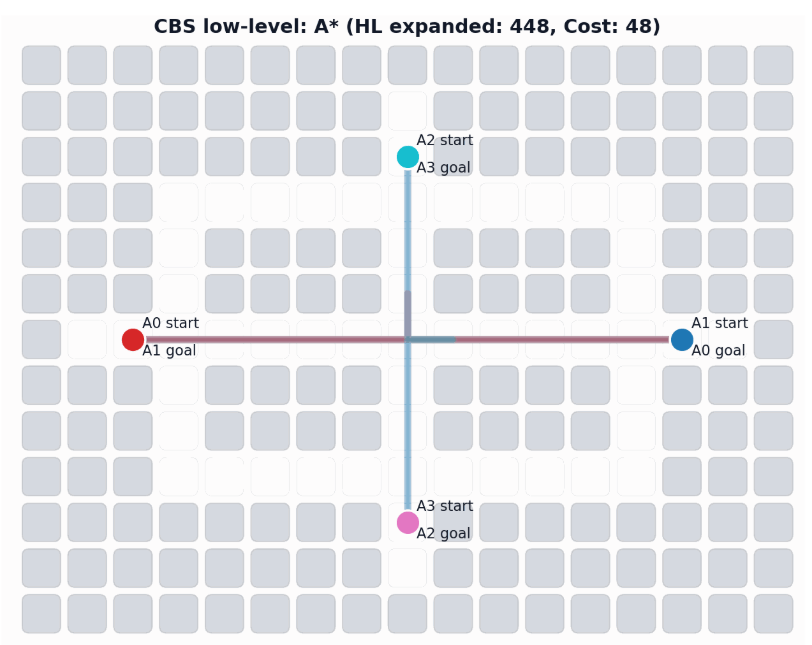
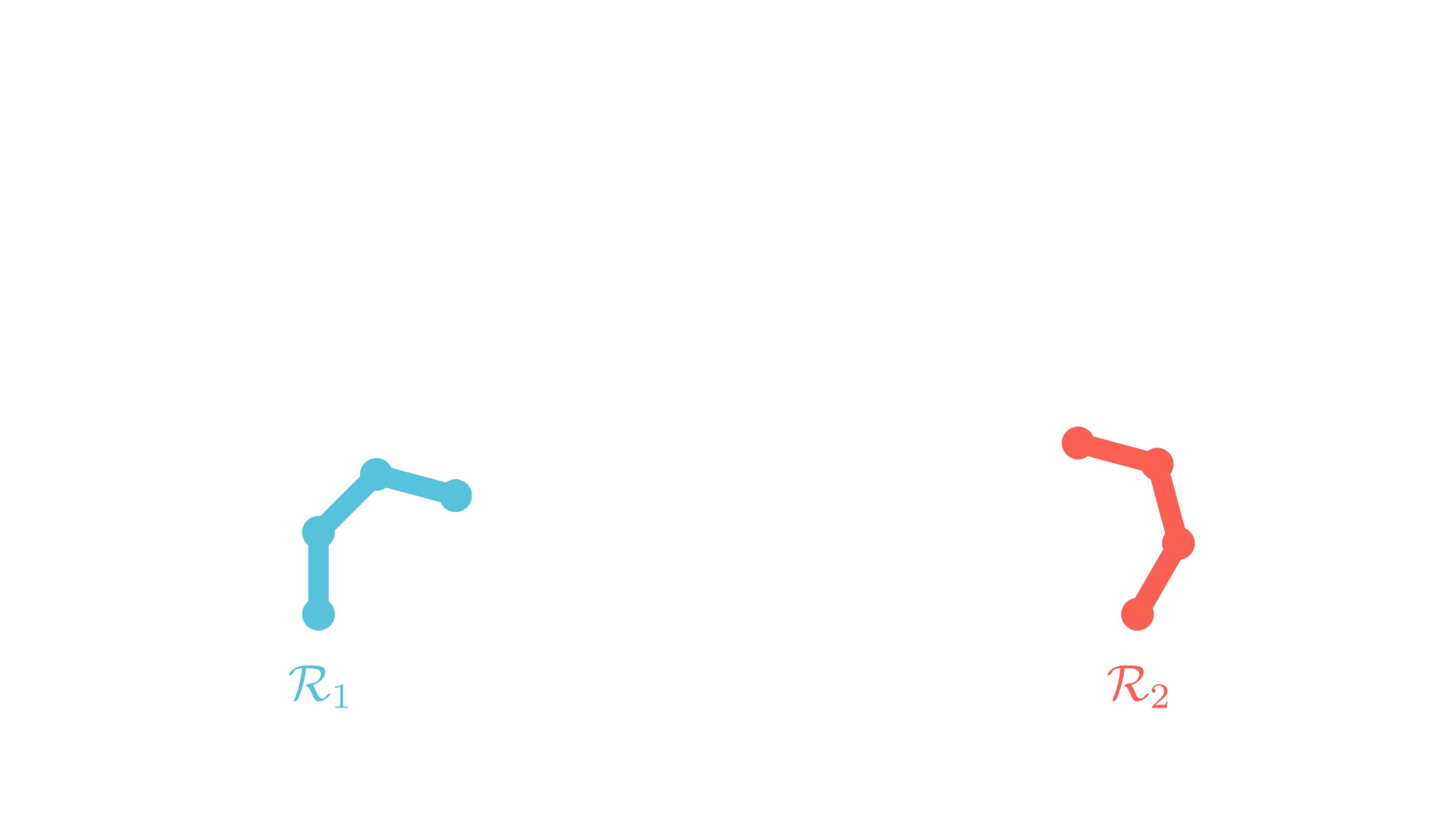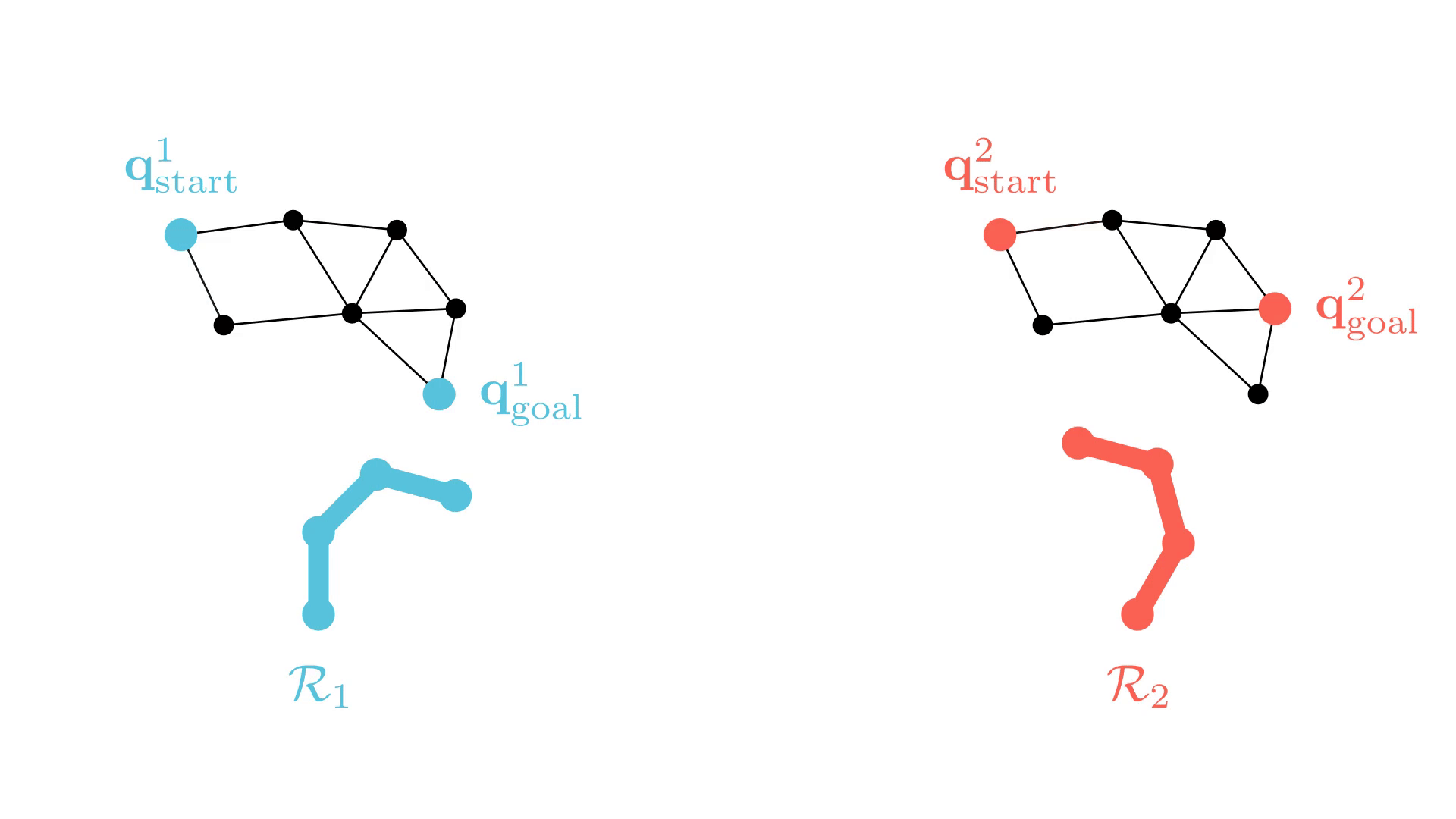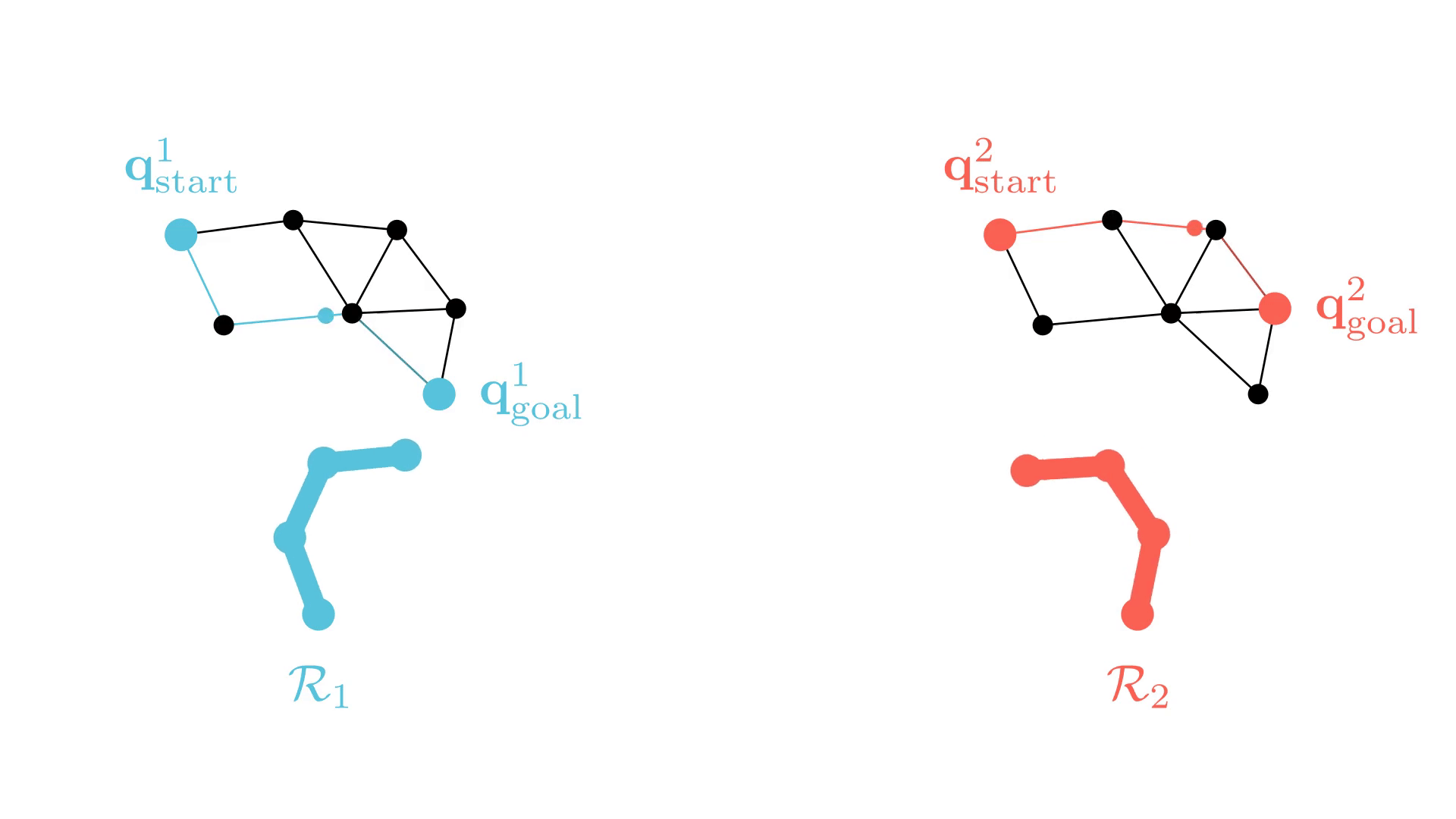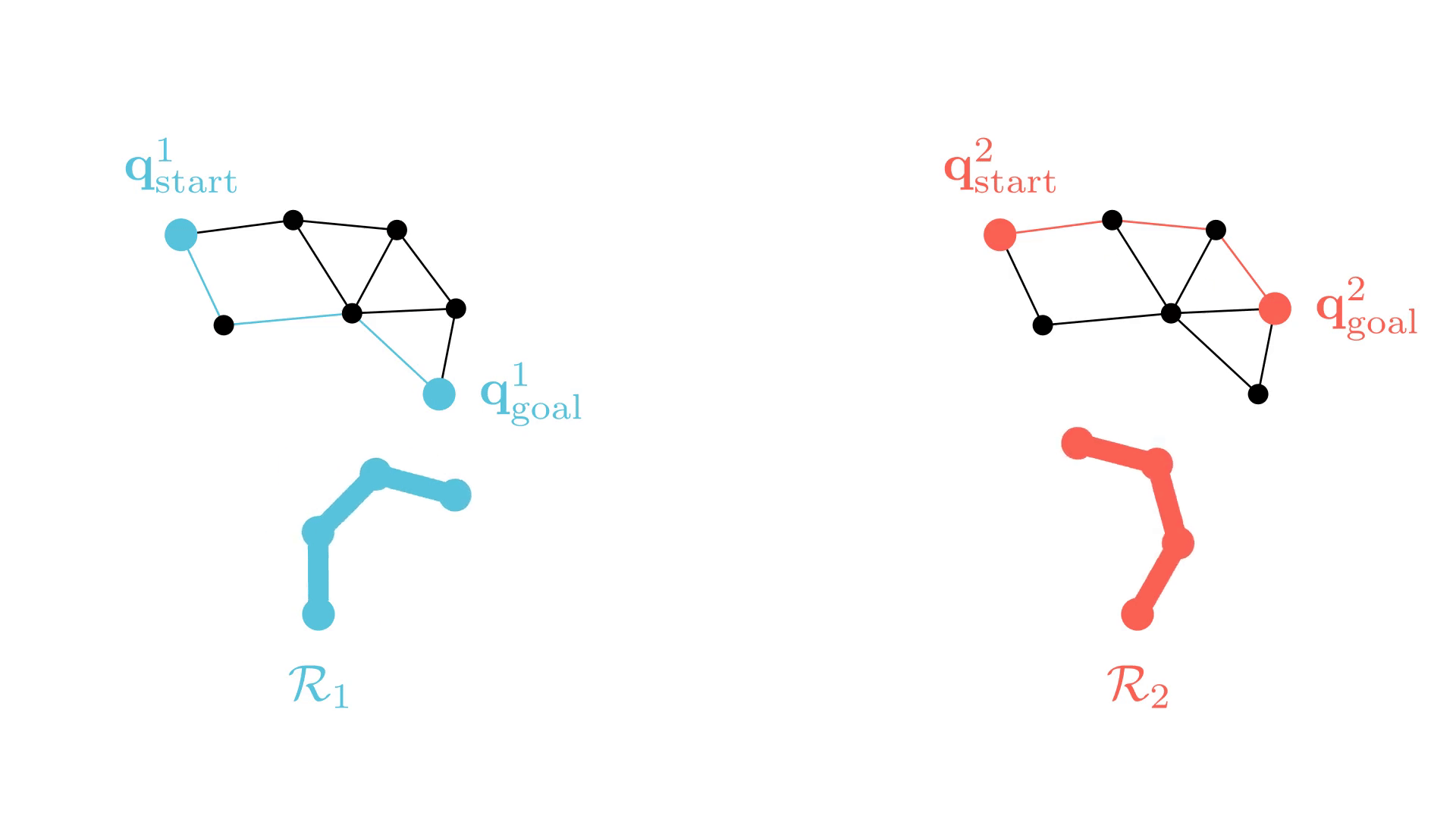
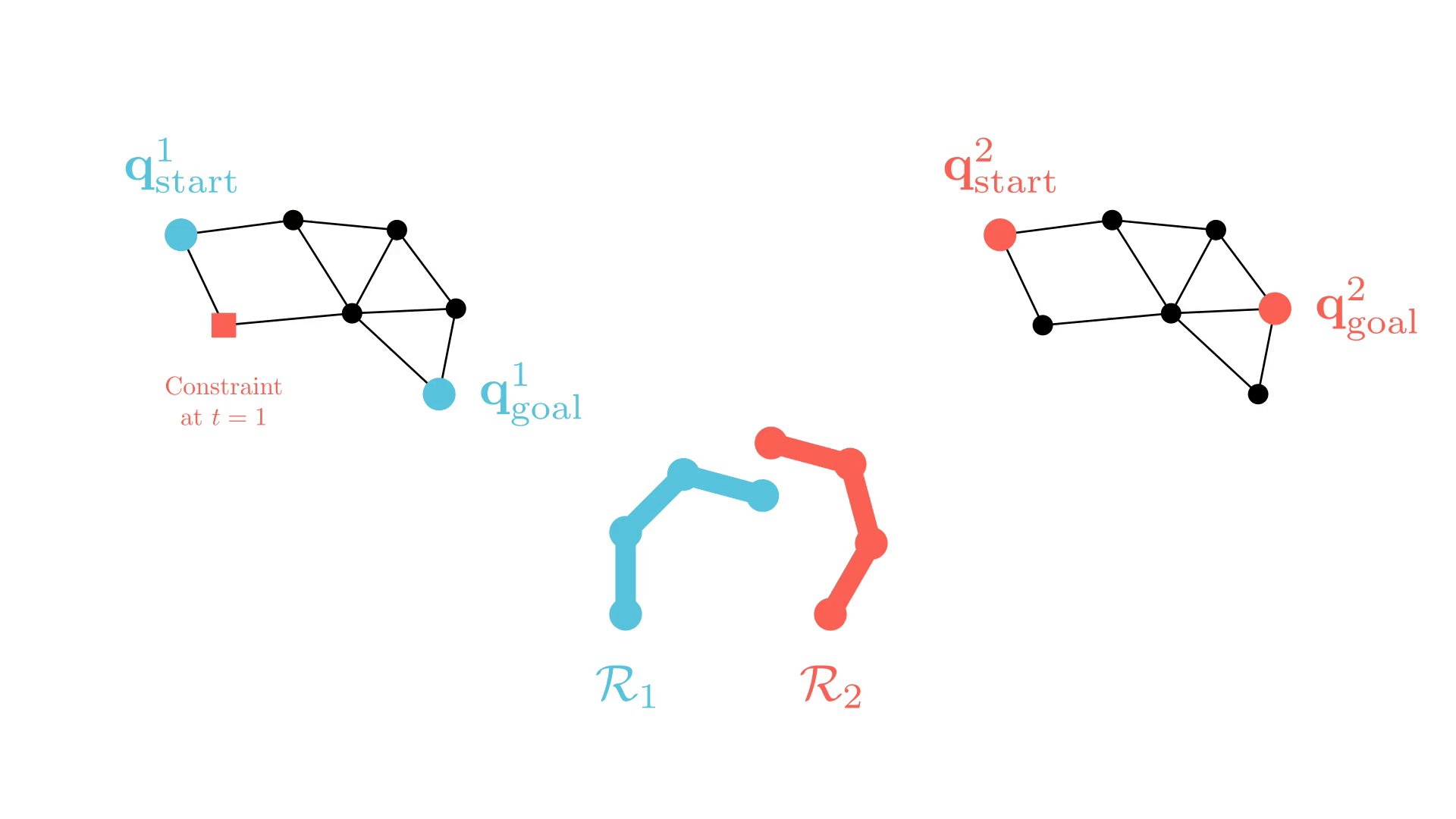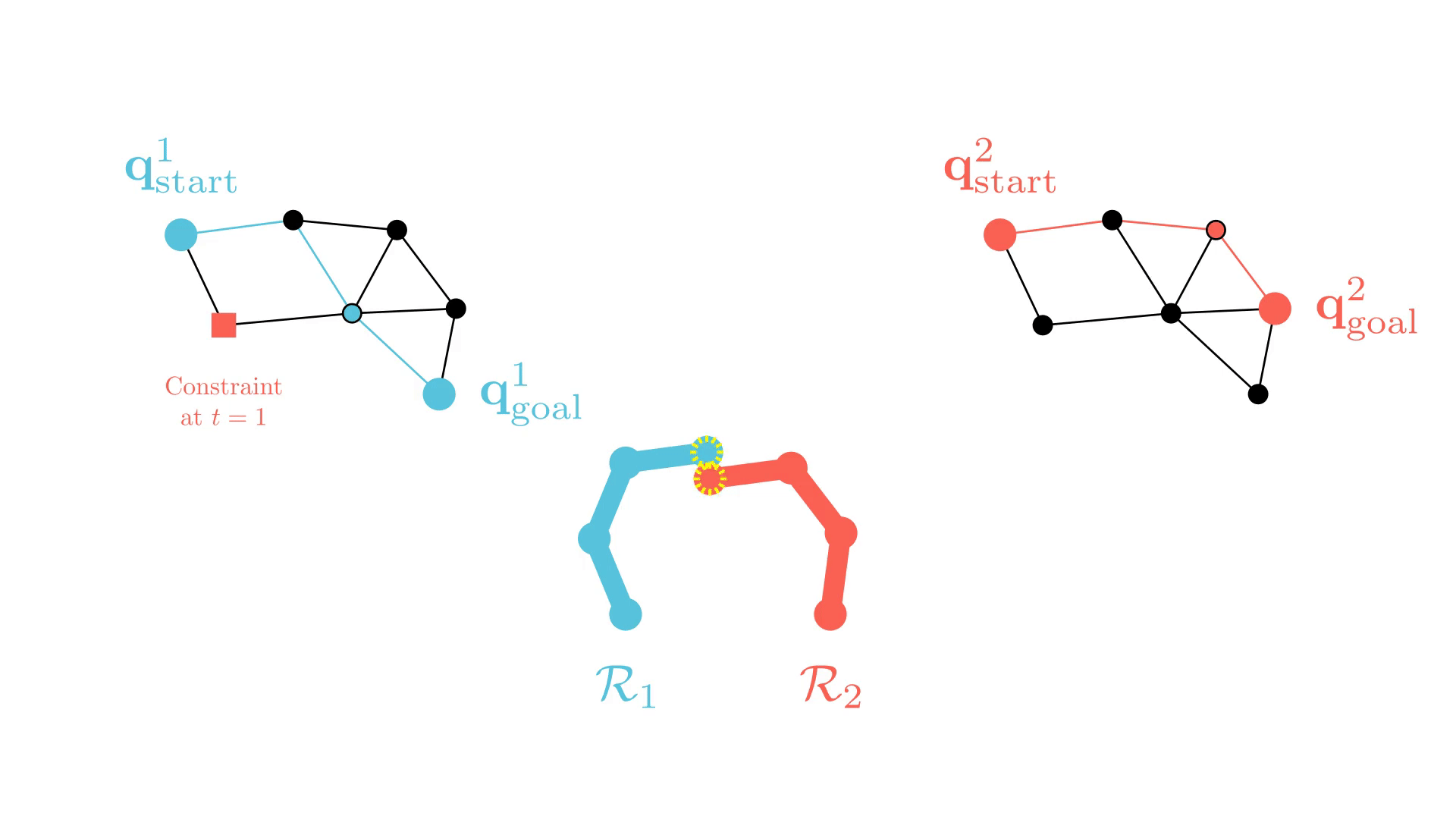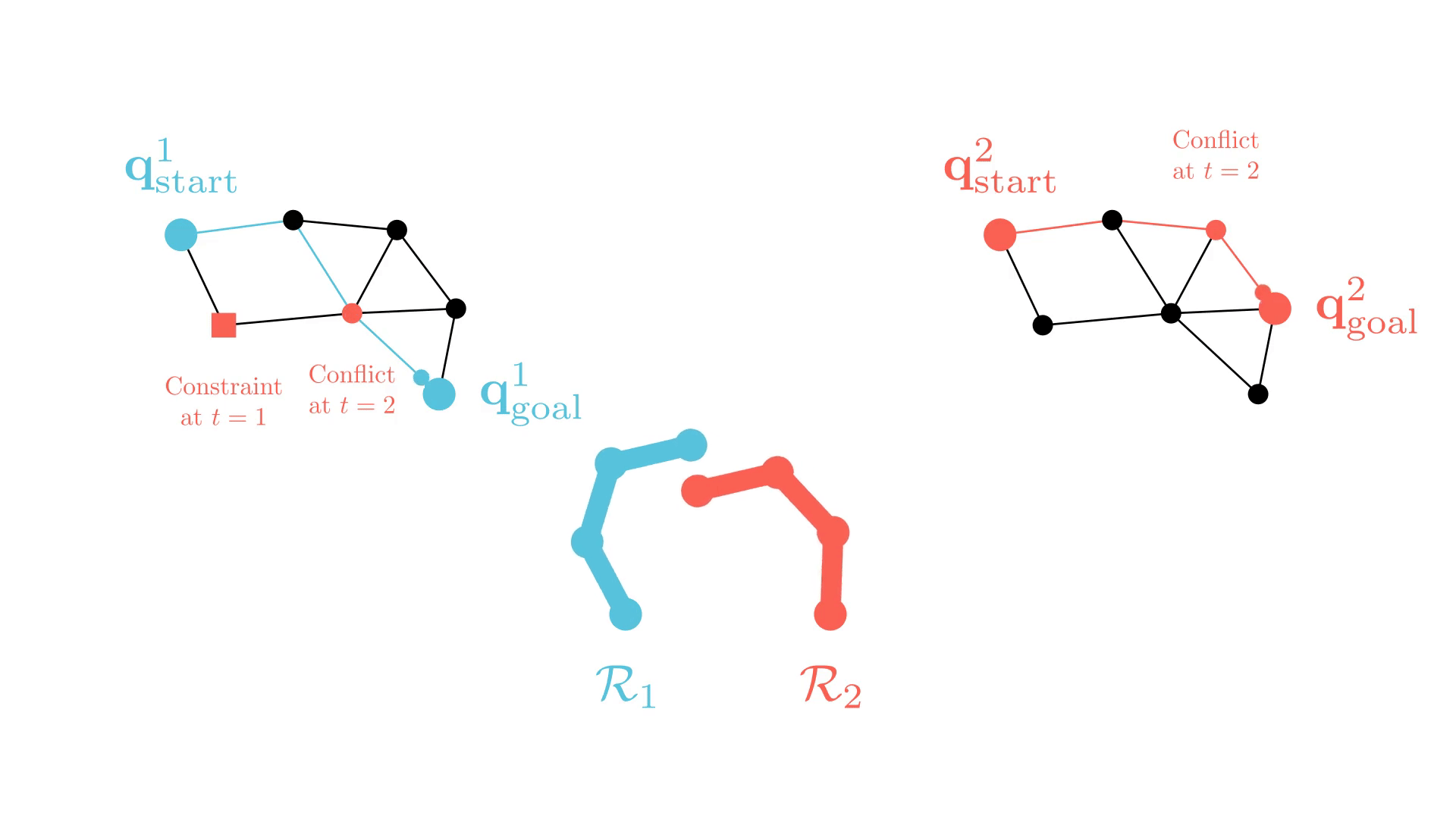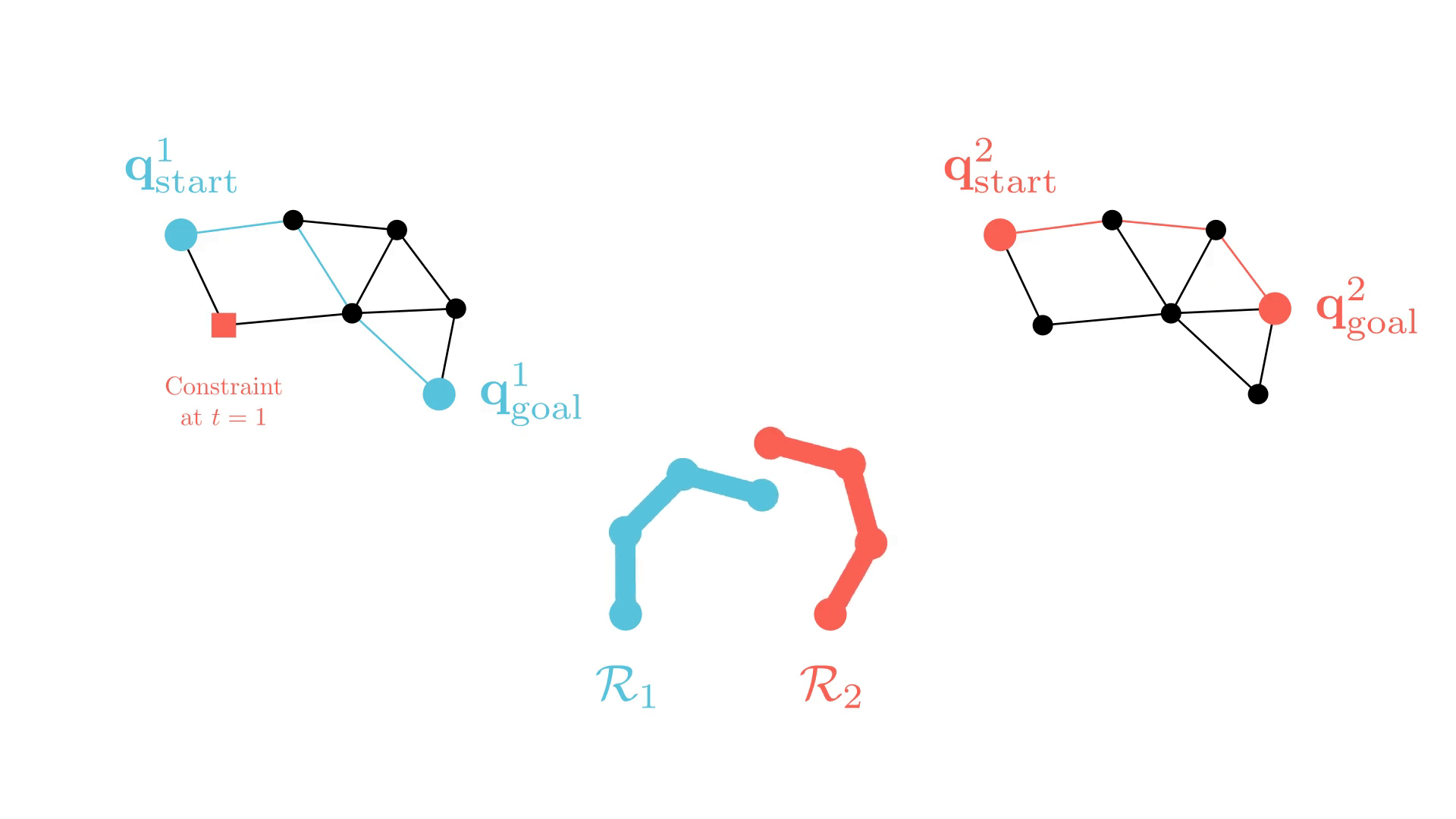
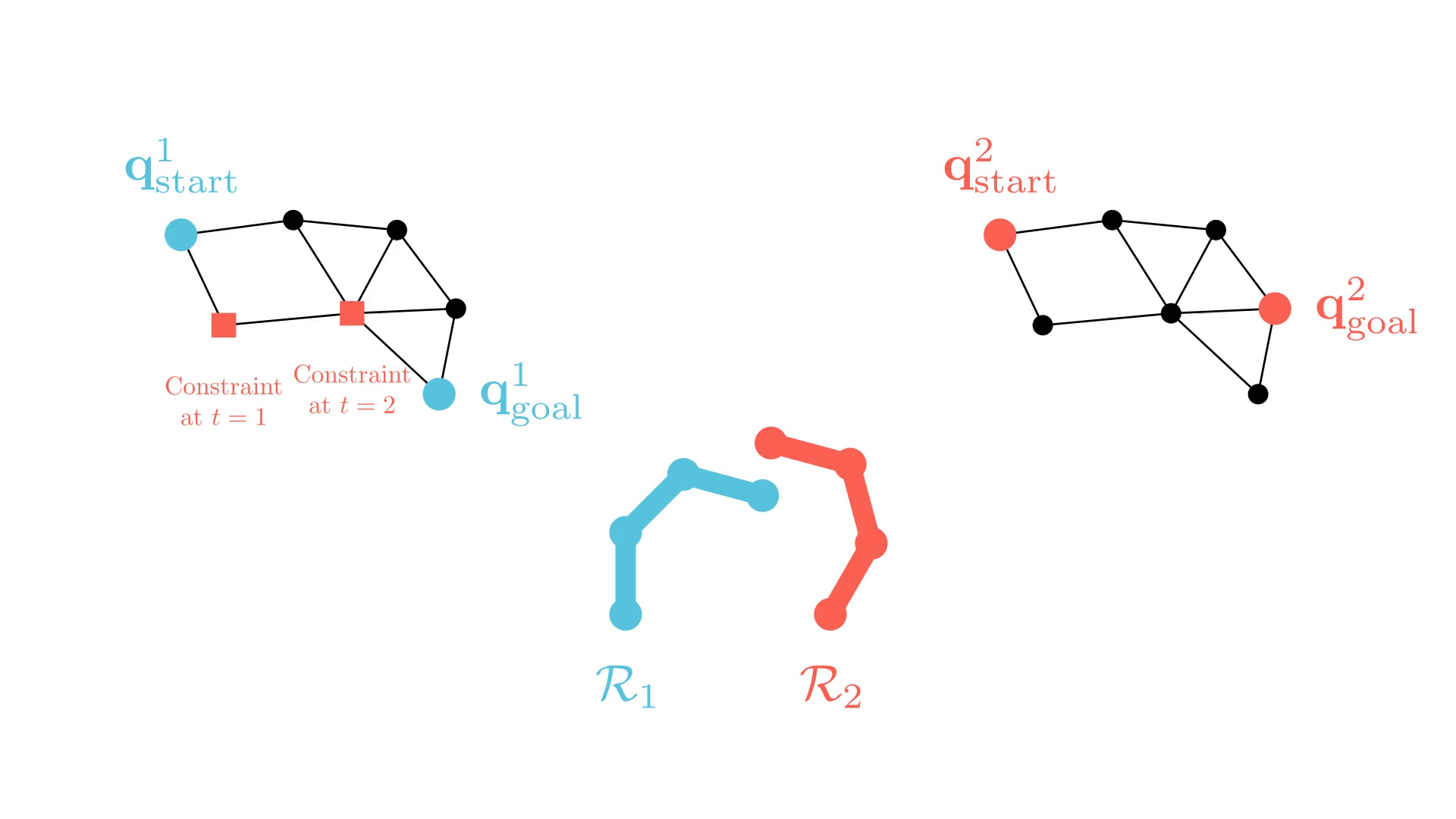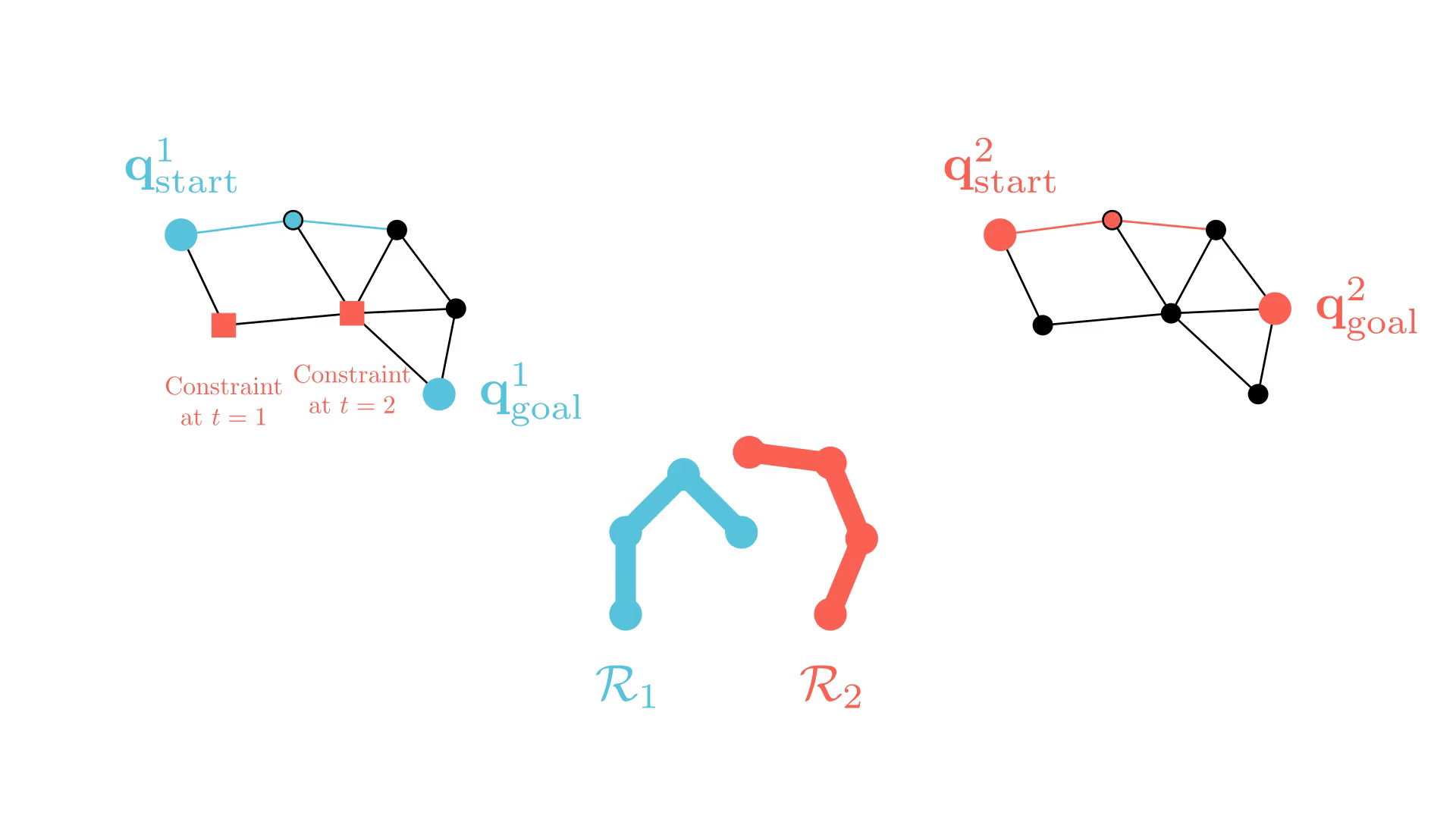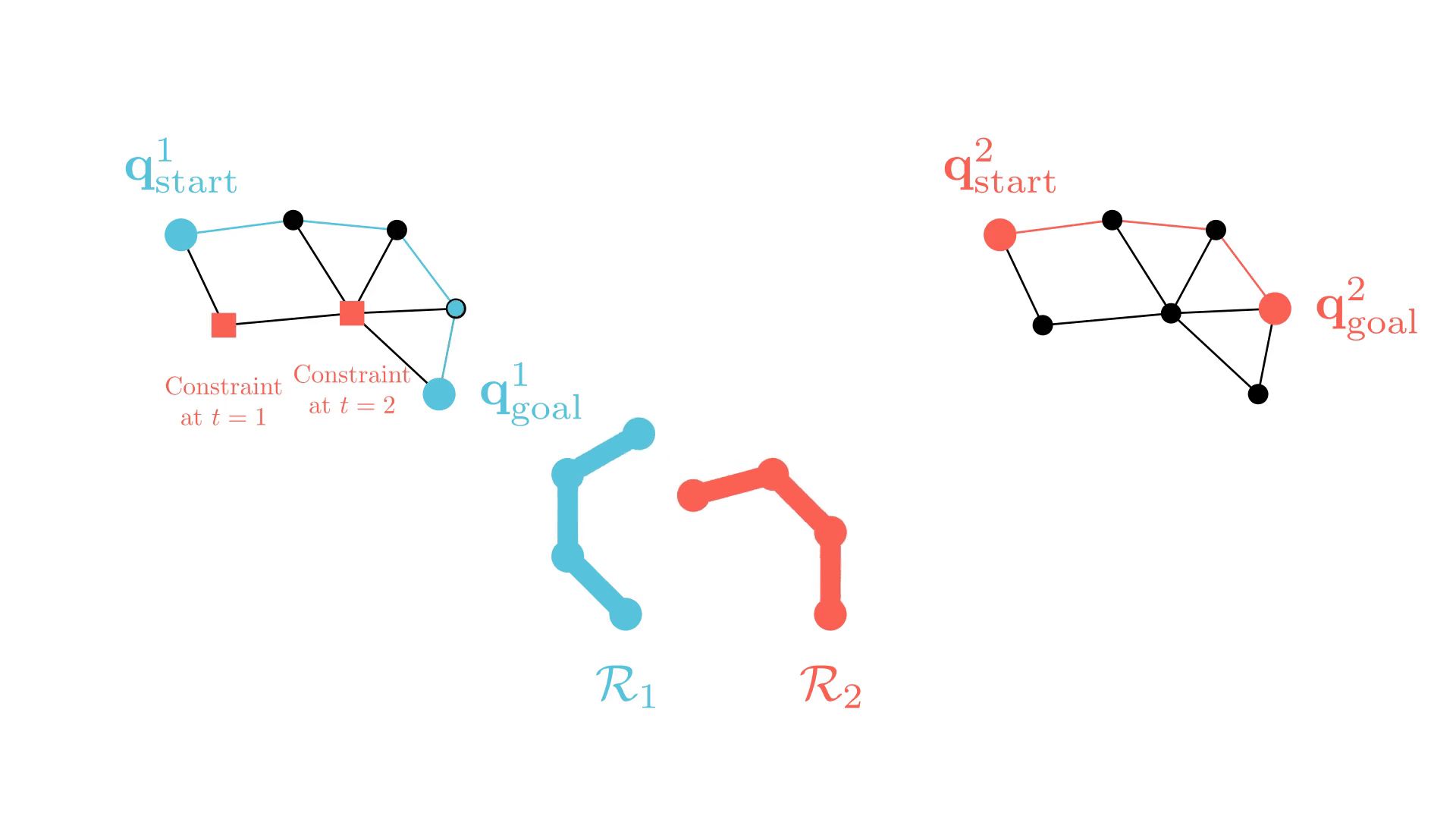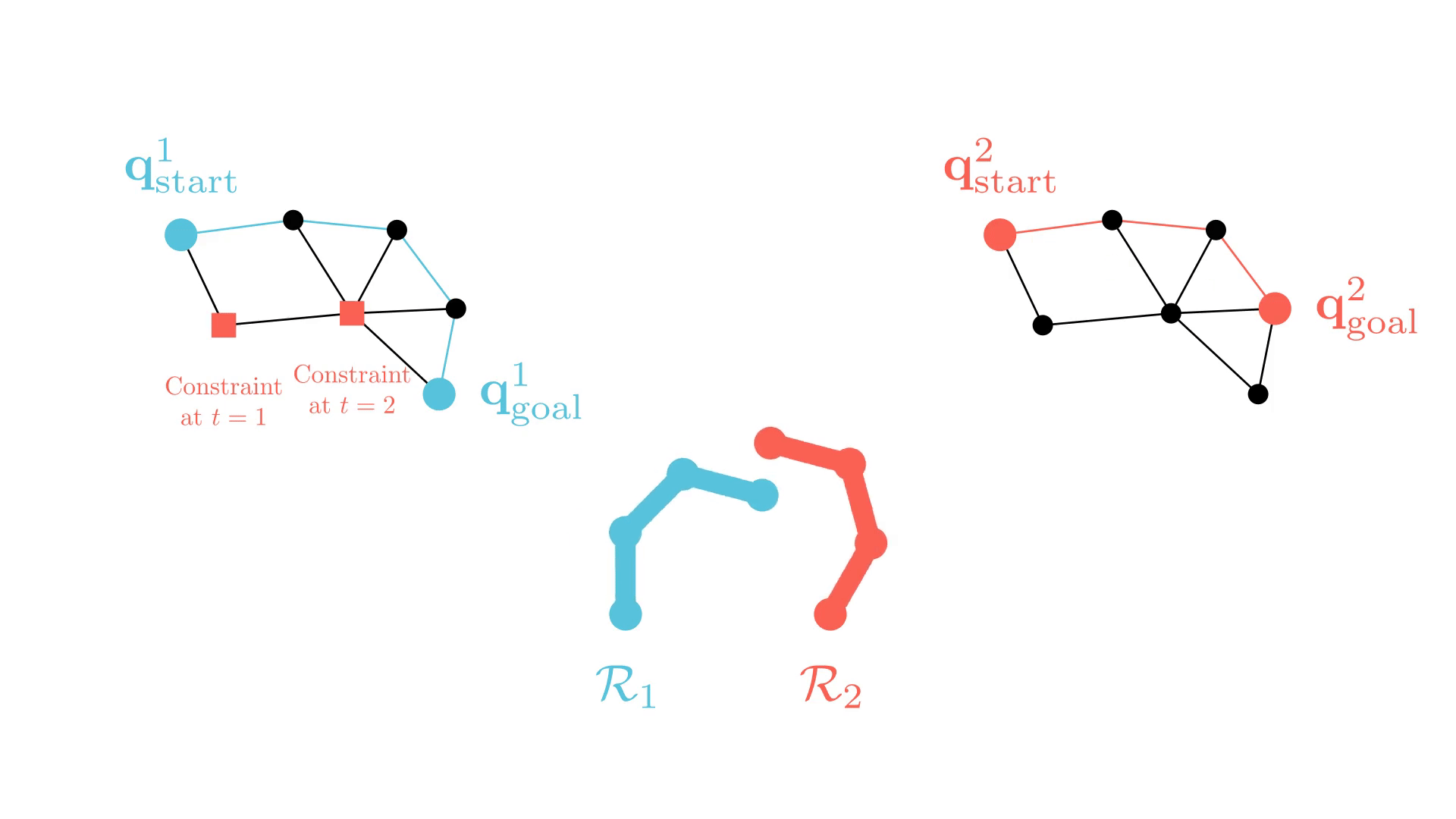
Background: Conflict-Based Search (CBS)
In particular, the CBS framework has been especially influential.
t=4
t=4

t=4
-
Plan for all agents individually.
-
Find collisions (conflicts) between their current paths.
-
Impose a single constraint on each participating agent and replan.
-
Repeat.
Sharon, G., Stern, R., Felner, A. and Sturtevant, N.R. Conflict-based search for optimal multi-agent pathfinding. Artificial Intelligence, 2015.
In particular, the CBS framework has been especially influential.
t=4
t=4
t=4
t=4
t=4
t=4

t=4

t=4
This framework guarantees completeness and optimality for MAPF.
-
Plan for all agents individually.
-
Find collisions (conflicts) between their current paths.
-
Impose a single constraint on each participating agent and replan.
-
Repeat.
Background: Conflict-Based Search (CBS)
Enhanced Conflict-Based Search (ECBS)
A relevant improvement to CBS is ECBS. Here solution quality can be traded for computational efficiency (i.e., finding solutions more quickly).
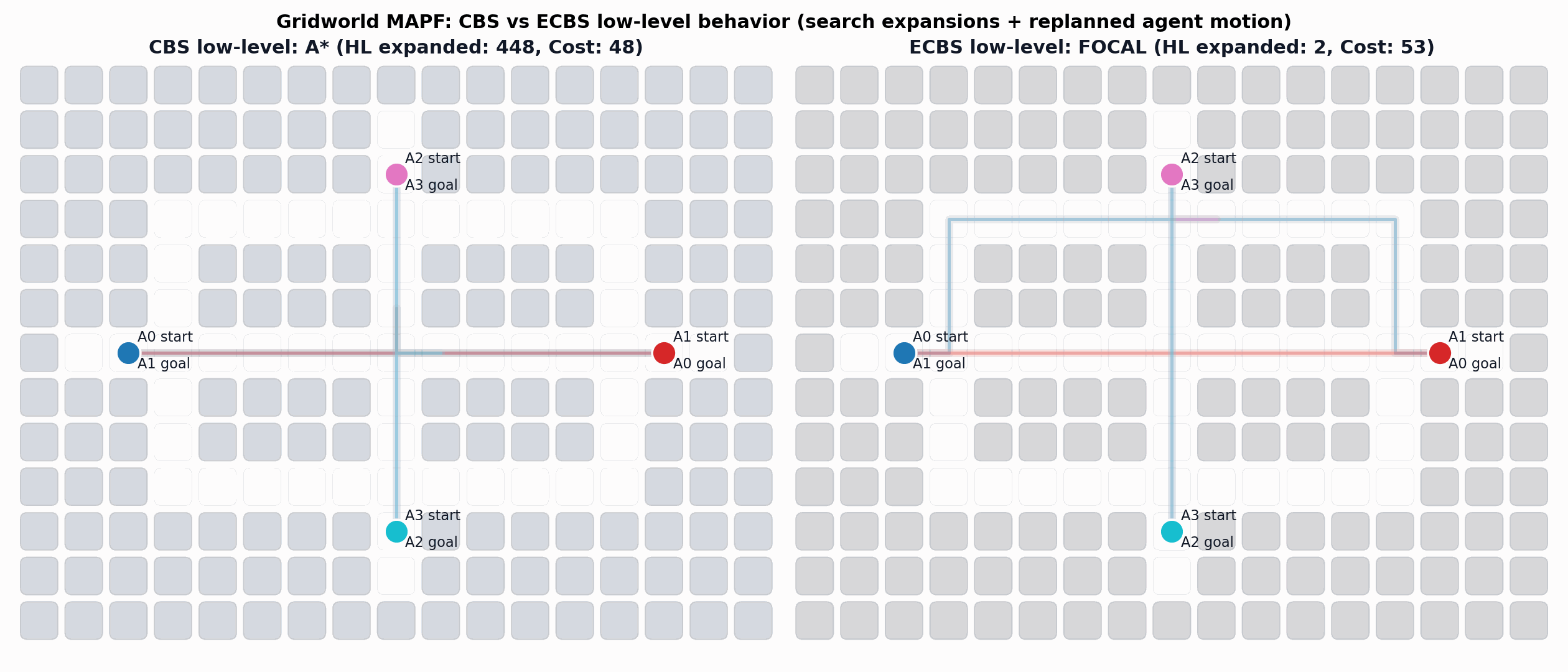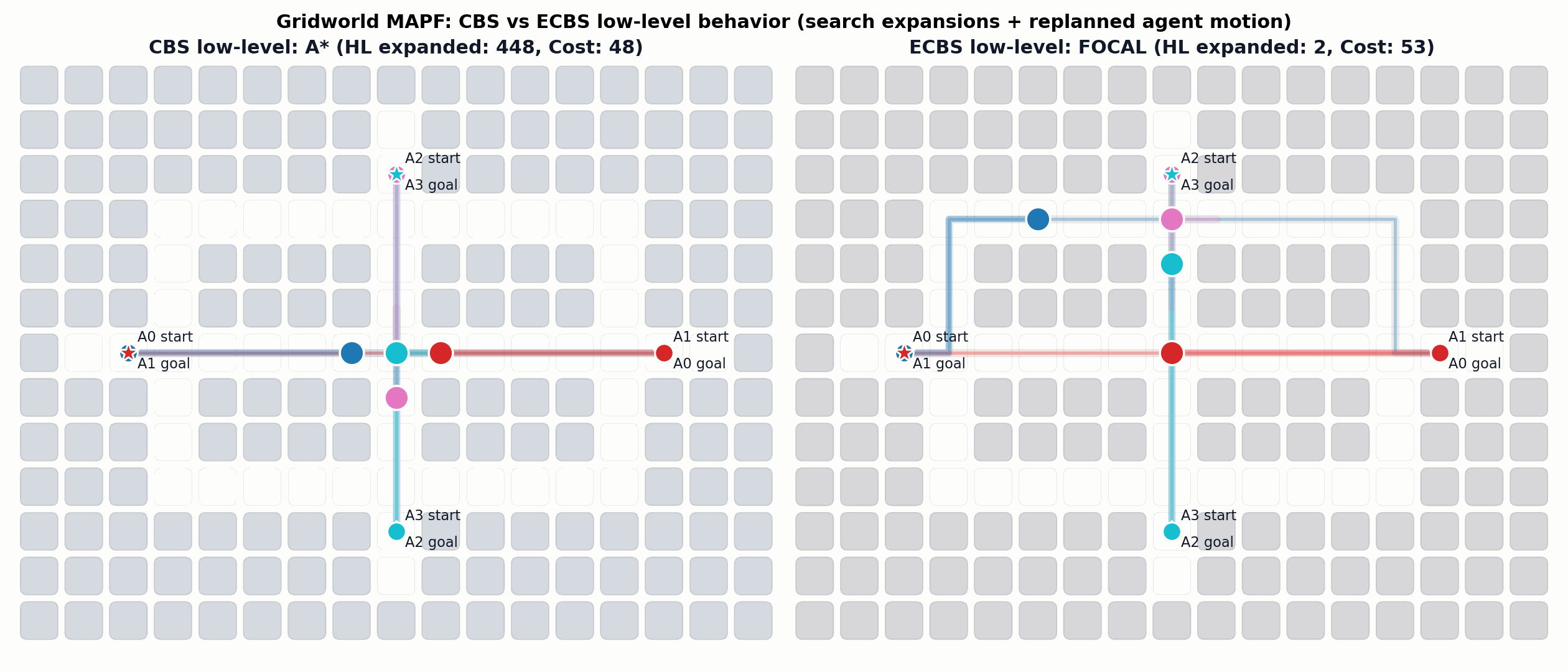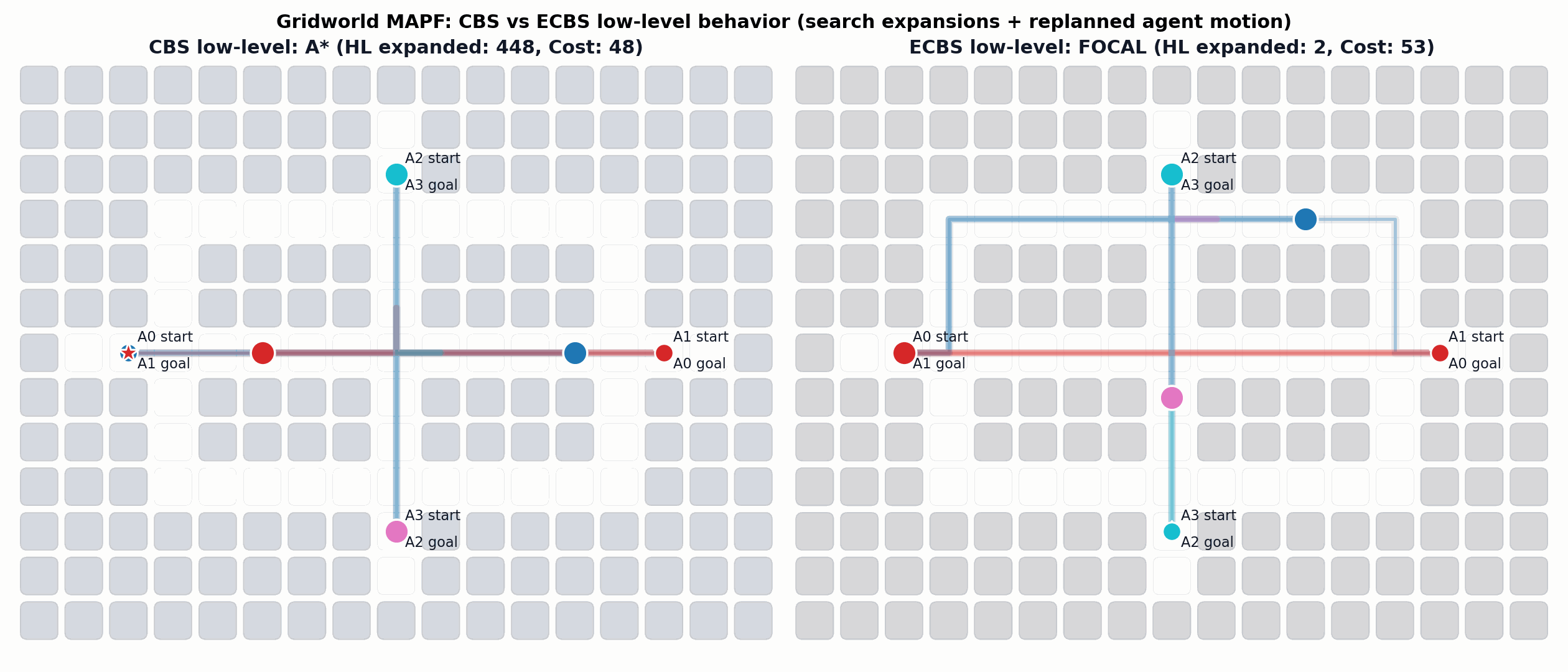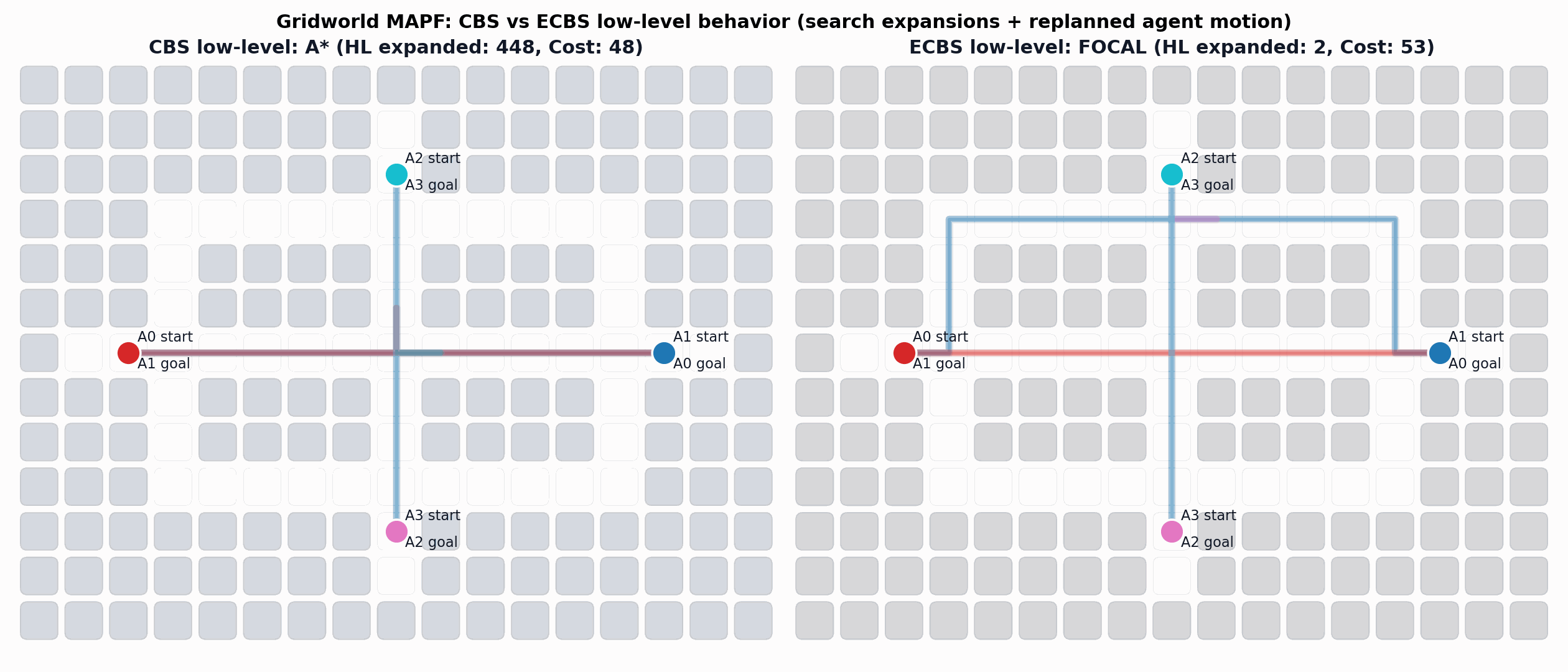
Barer, M., Sharon, G., Stern, R. and Felner, A. Suboptimal variants of the conflict-based search algorithm for the multi-agent pathfinding problem. SoCS 2014.
Enhanced Conflict-Based Search (ECBS)
A relevant improvement to CBS is ECBS. Here solution quality can be traded for computational efficiency (i.e., finding solutions more quickly).
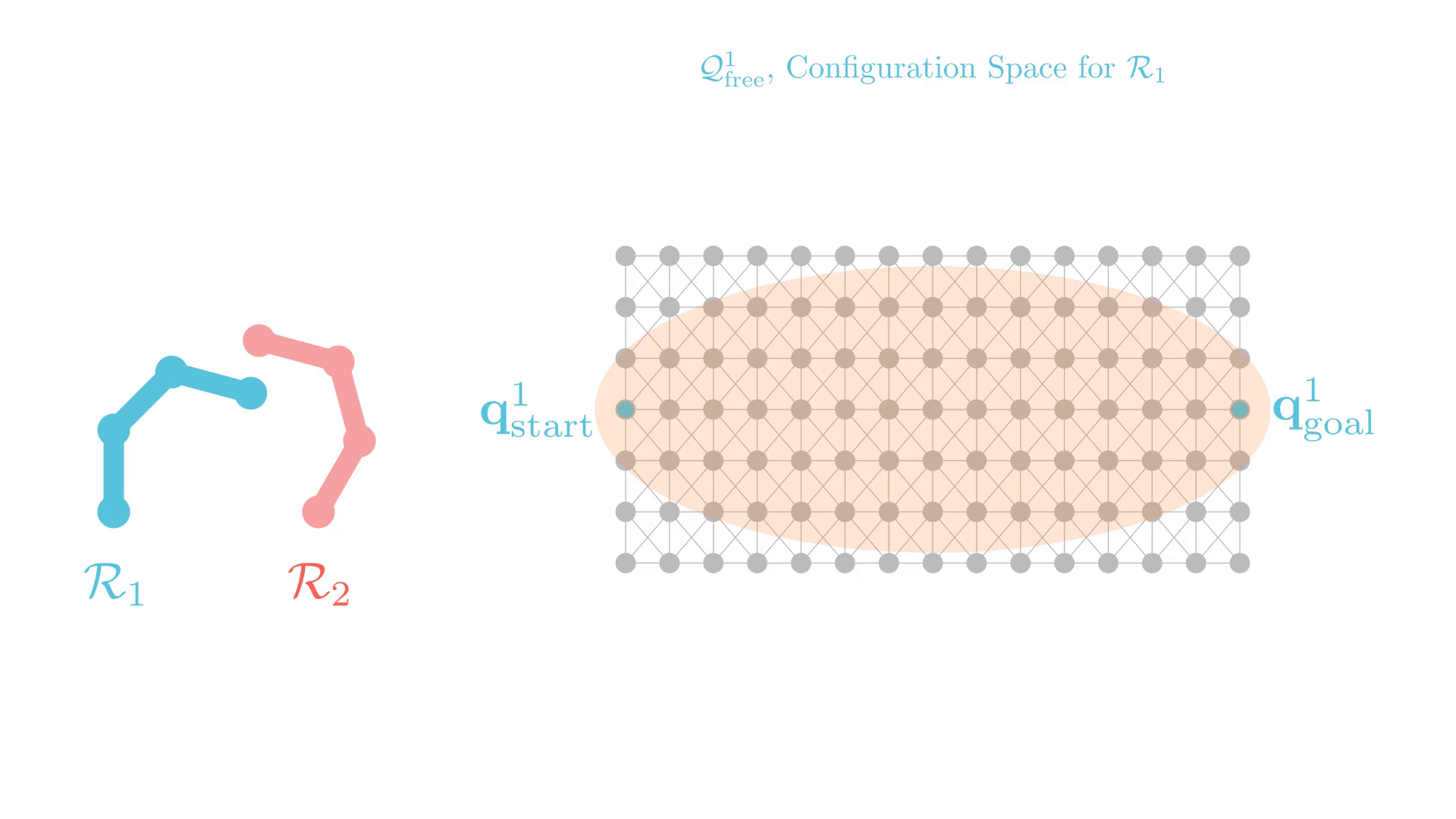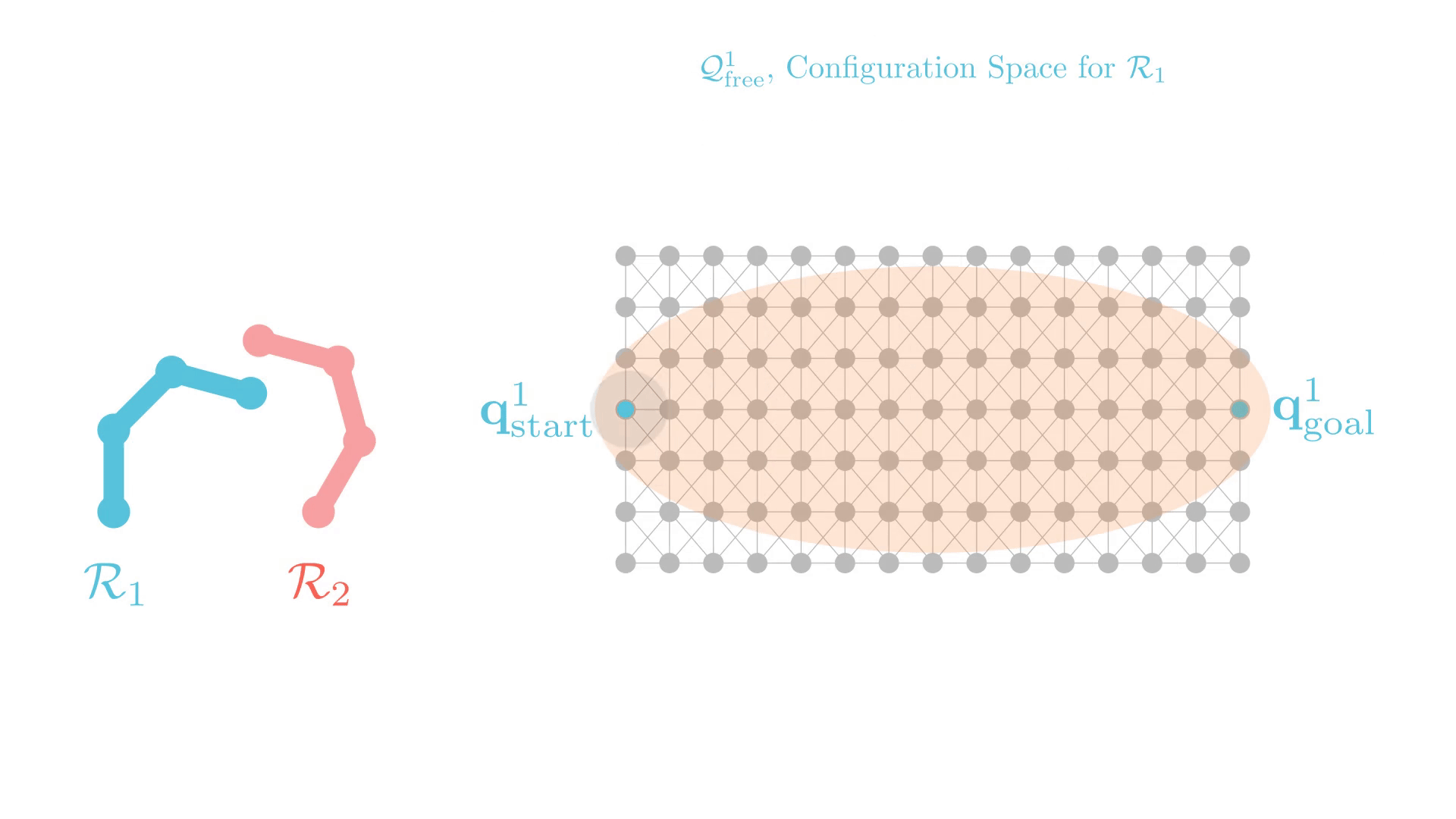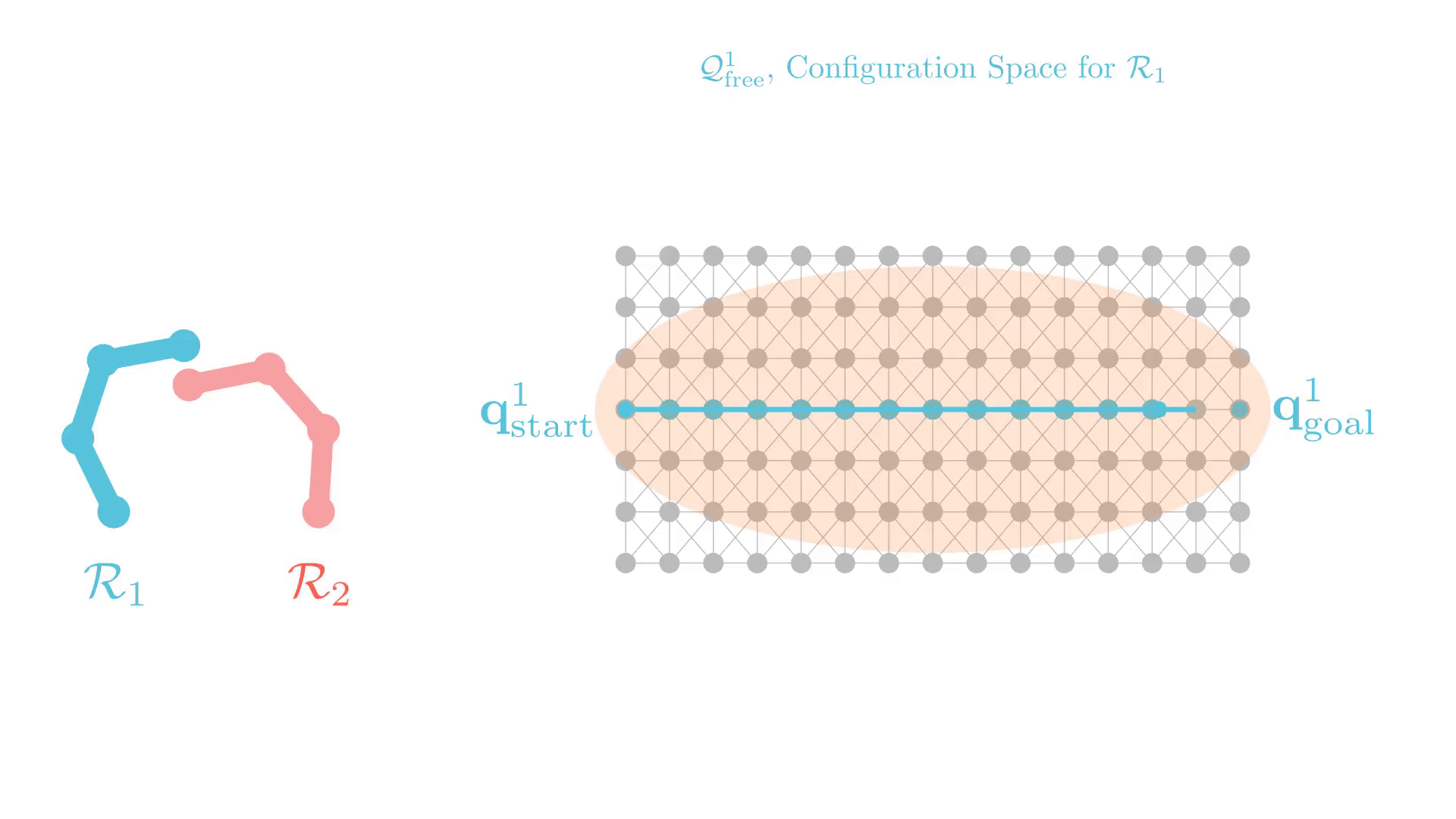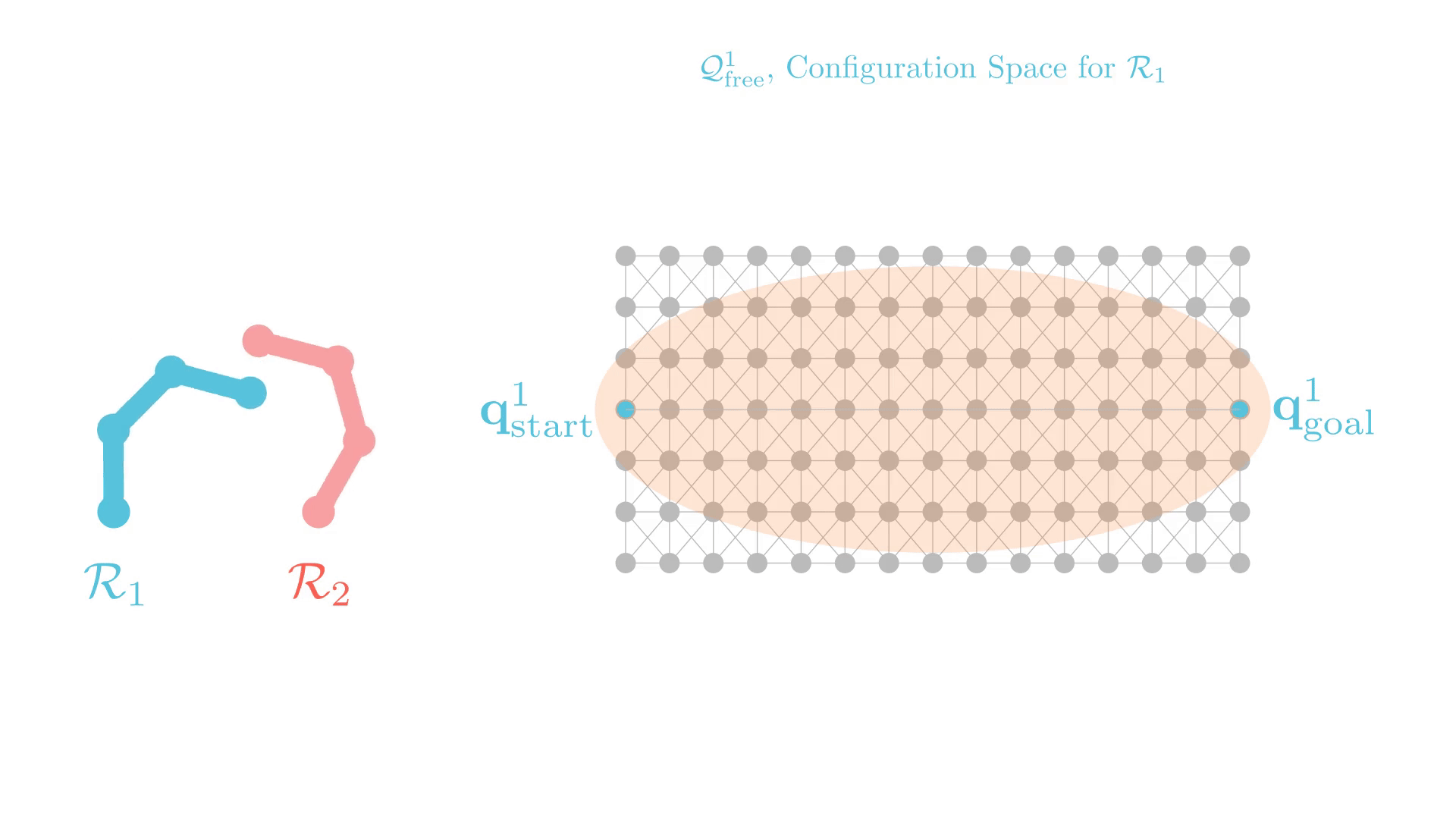
Graph Search for Manipulation
Joint angles
B. J. Cohen, S. Chitta and M. Likhachev, "Search-based planning for manipulation with motion primitives," ICRA 2010
Graph Search for Manipulation
Joint angles
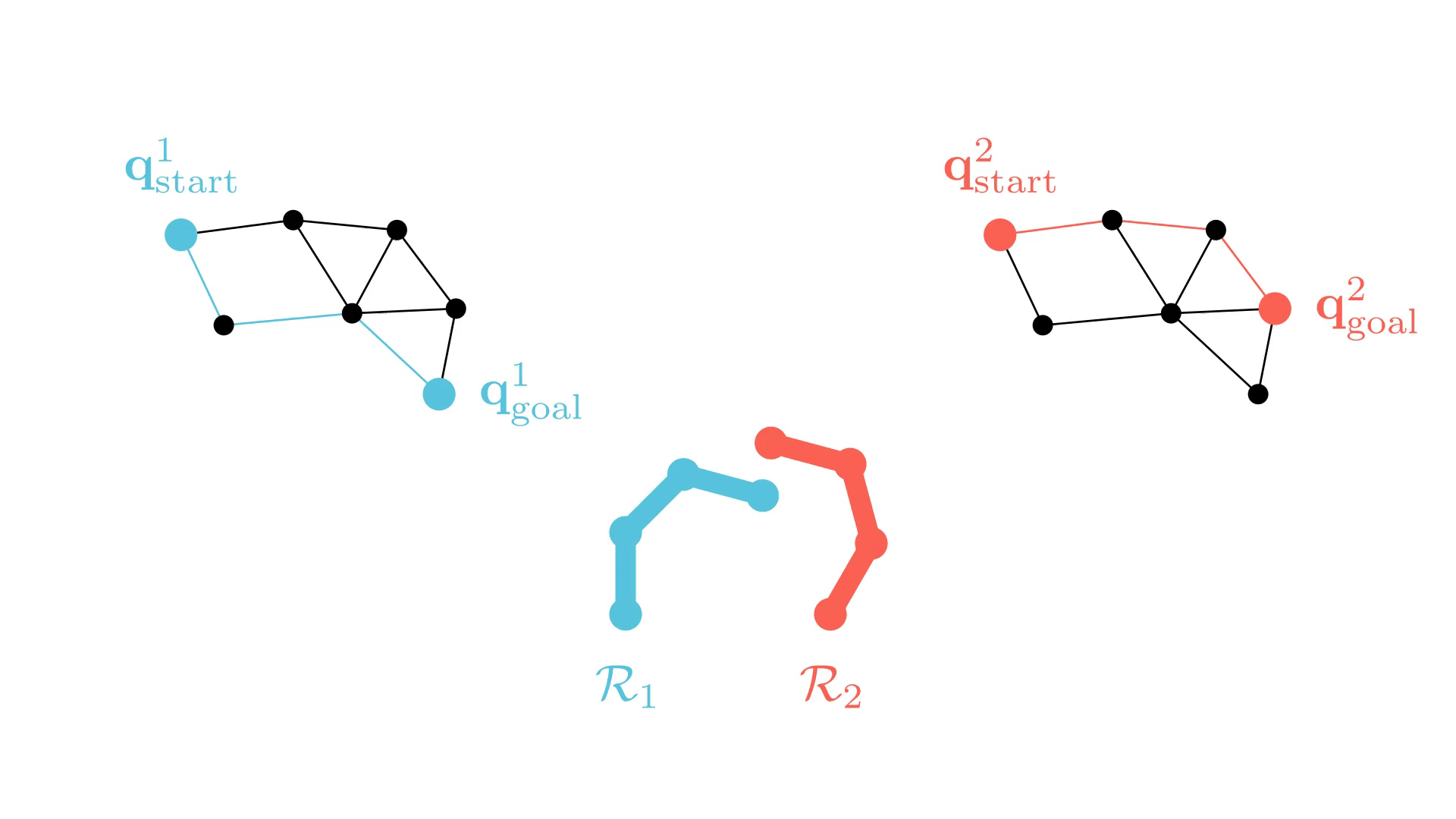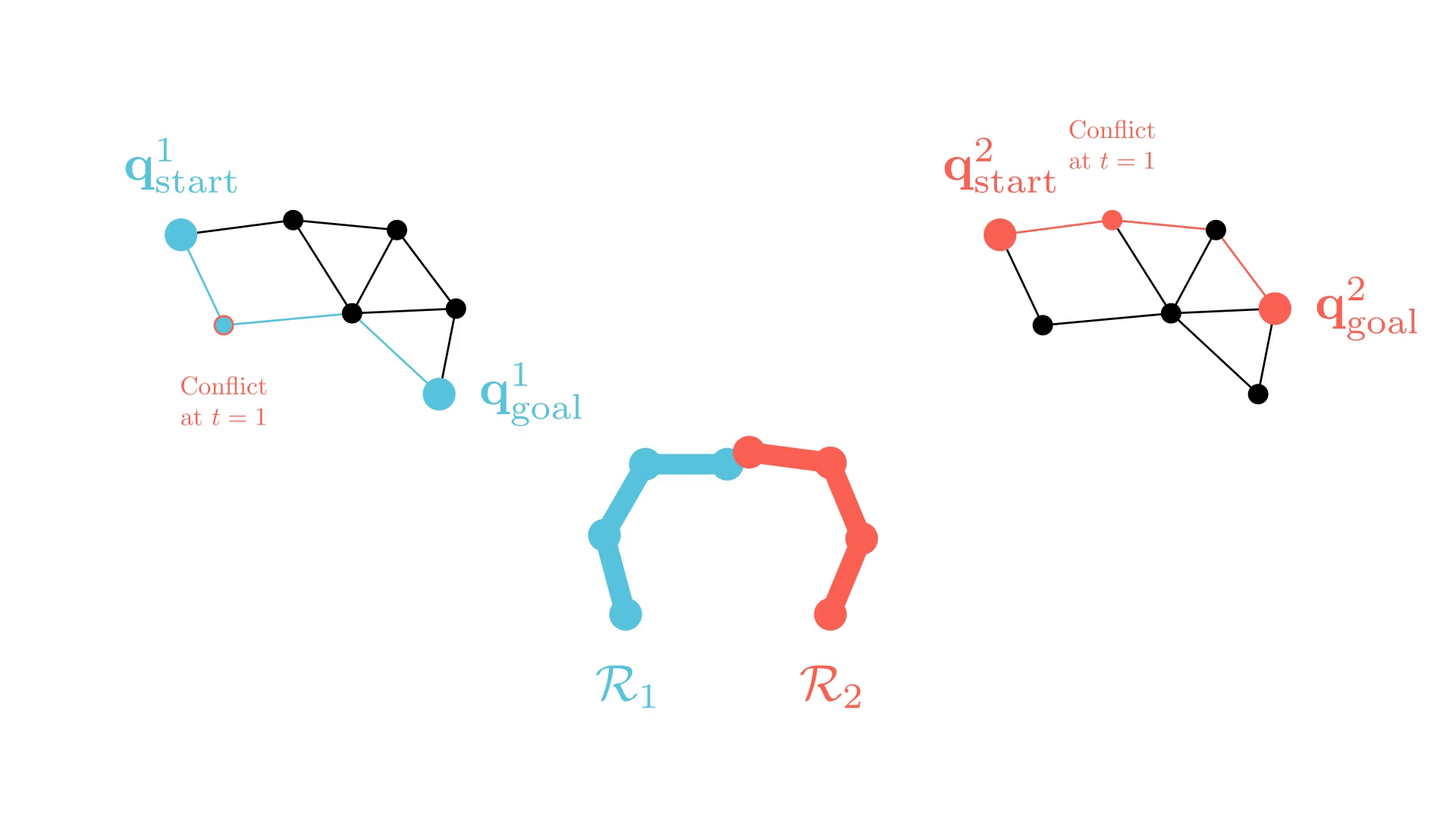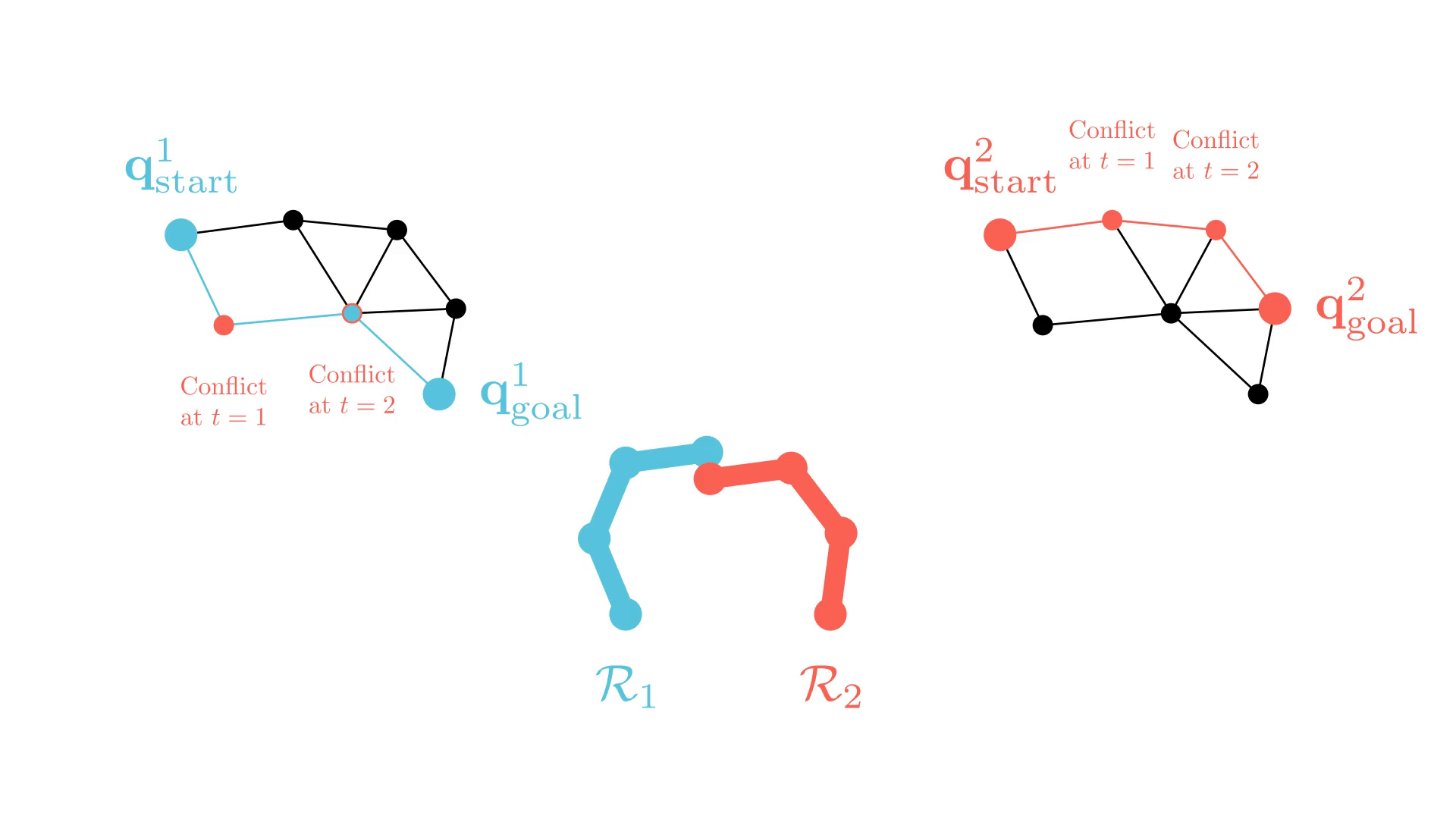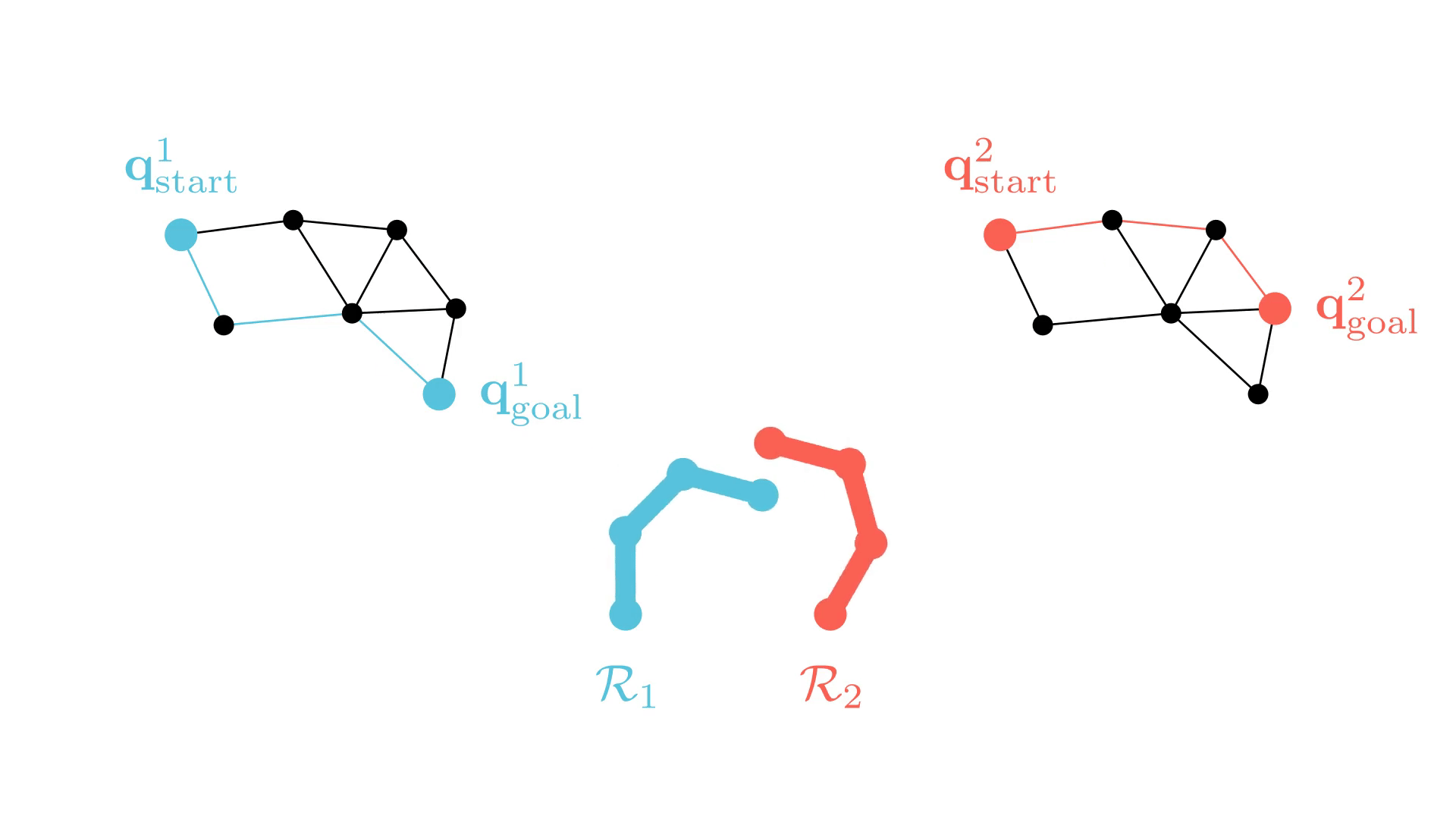
Graph Search for Manipulation
Joint angles
Graph Search for Manipulation
Joint angles
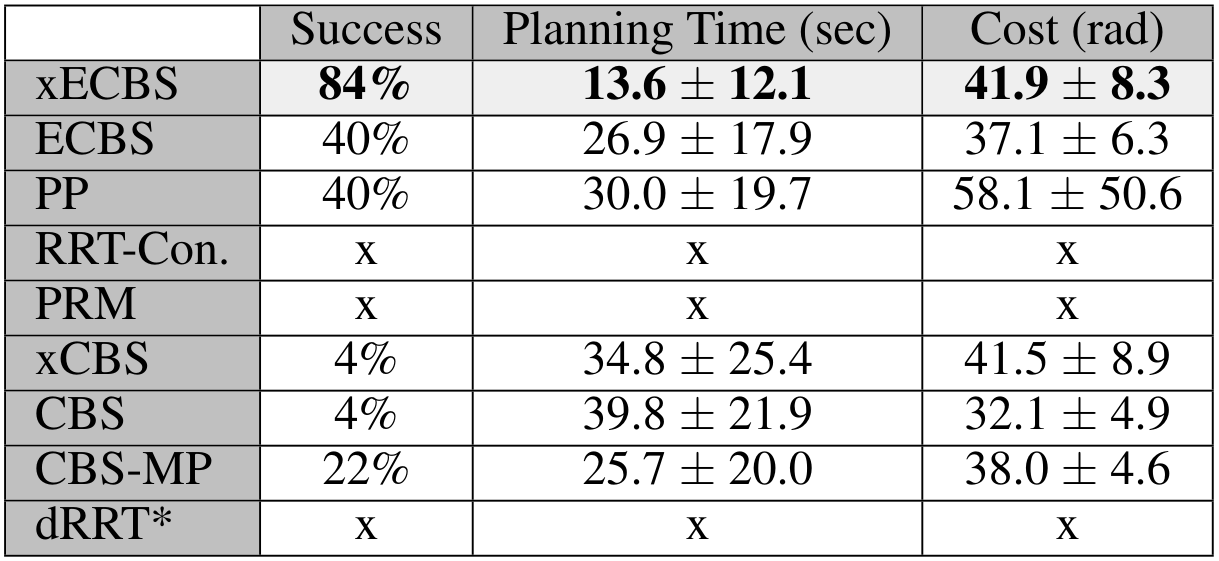
CBS for M-RAMP
The (in)efficiency of single-robot planning greatly affects CBS-like algorithms.
4-Robot Bin-Picking
8-Robot Shelf Rearrangement
The repetitive planning in CBS takes time.
CBS: A Single-Robot Perspective
CBS: A Single-Robot Perspective
_
CBS: A Single-Robot Perspective
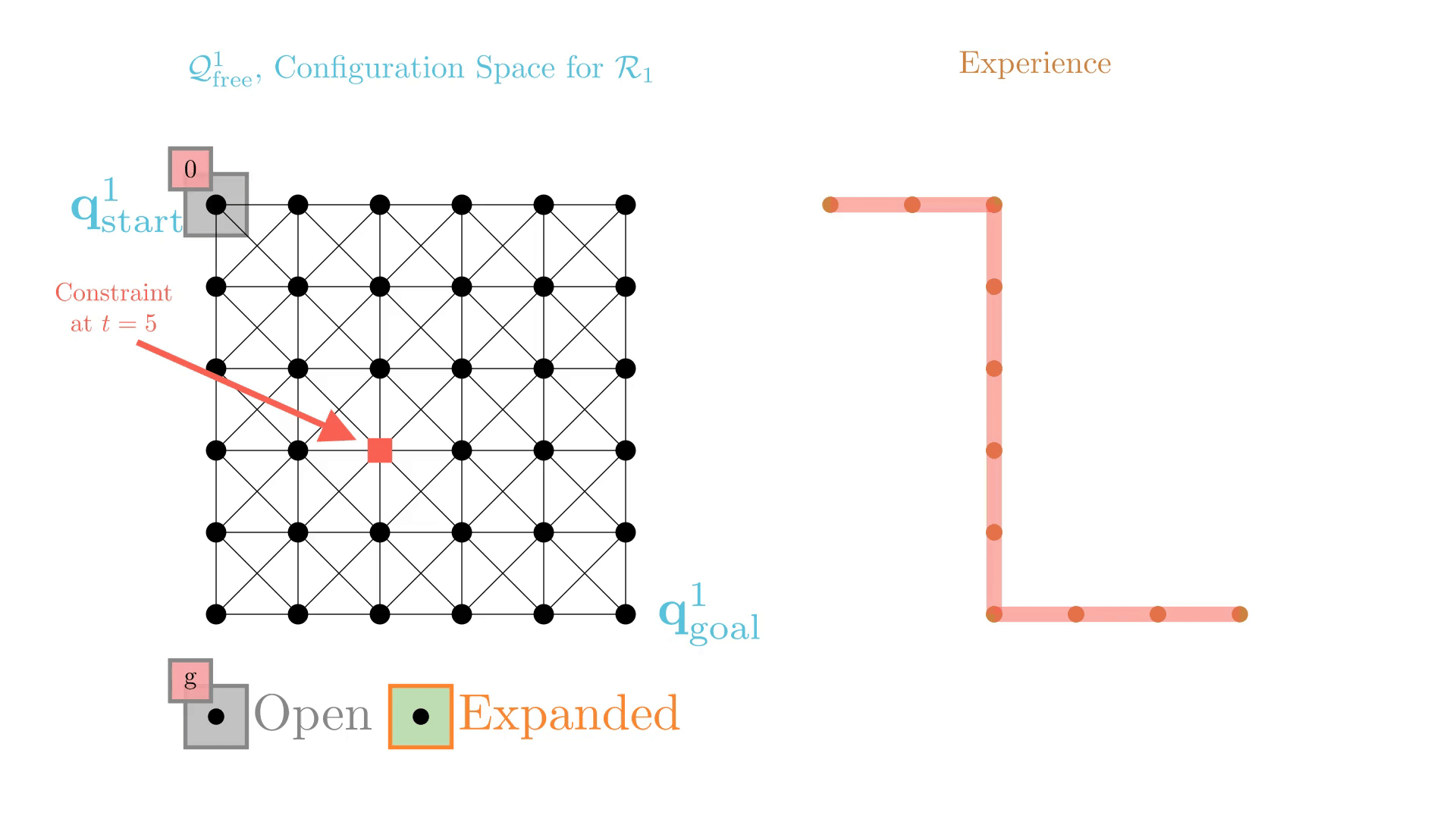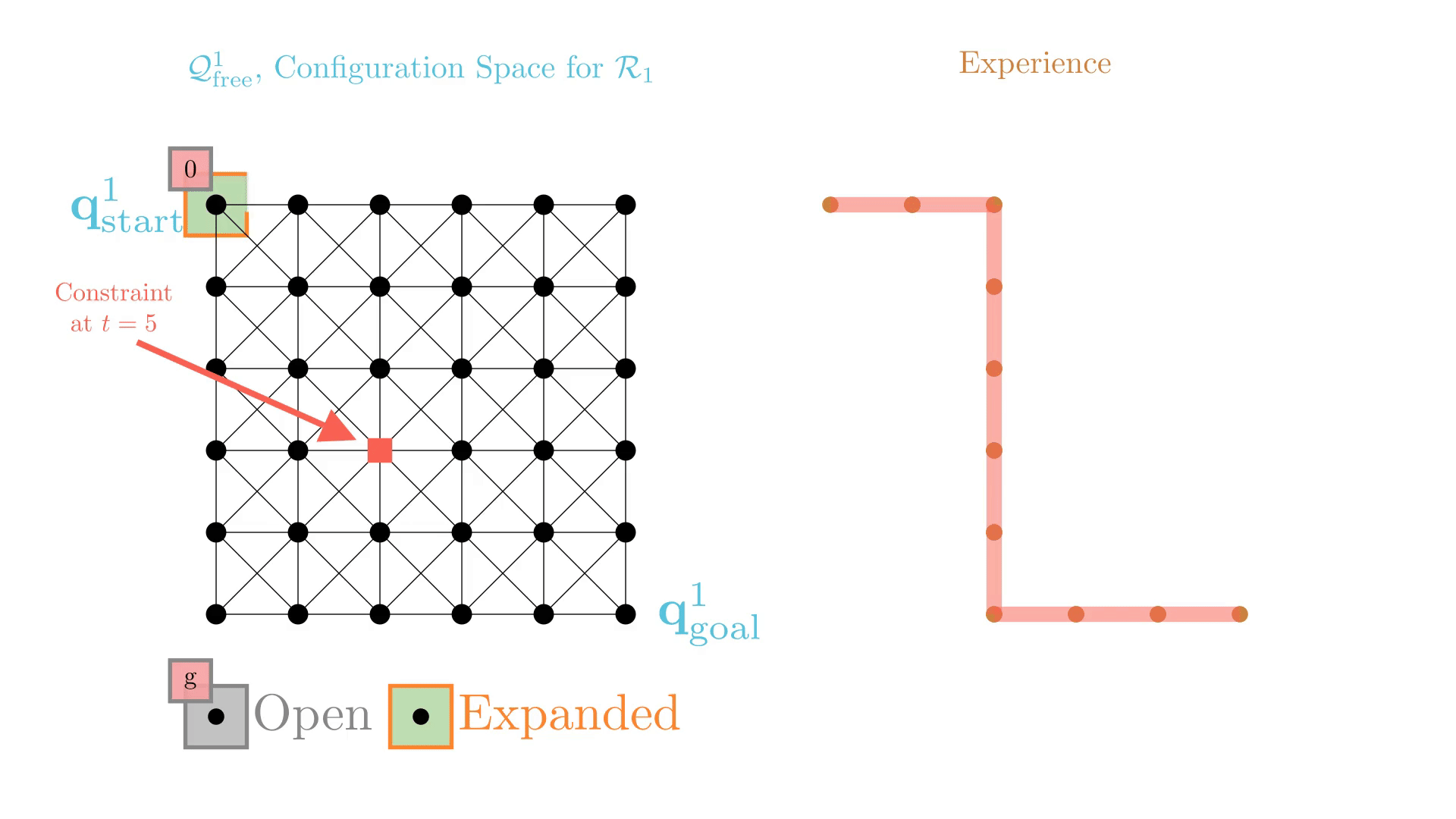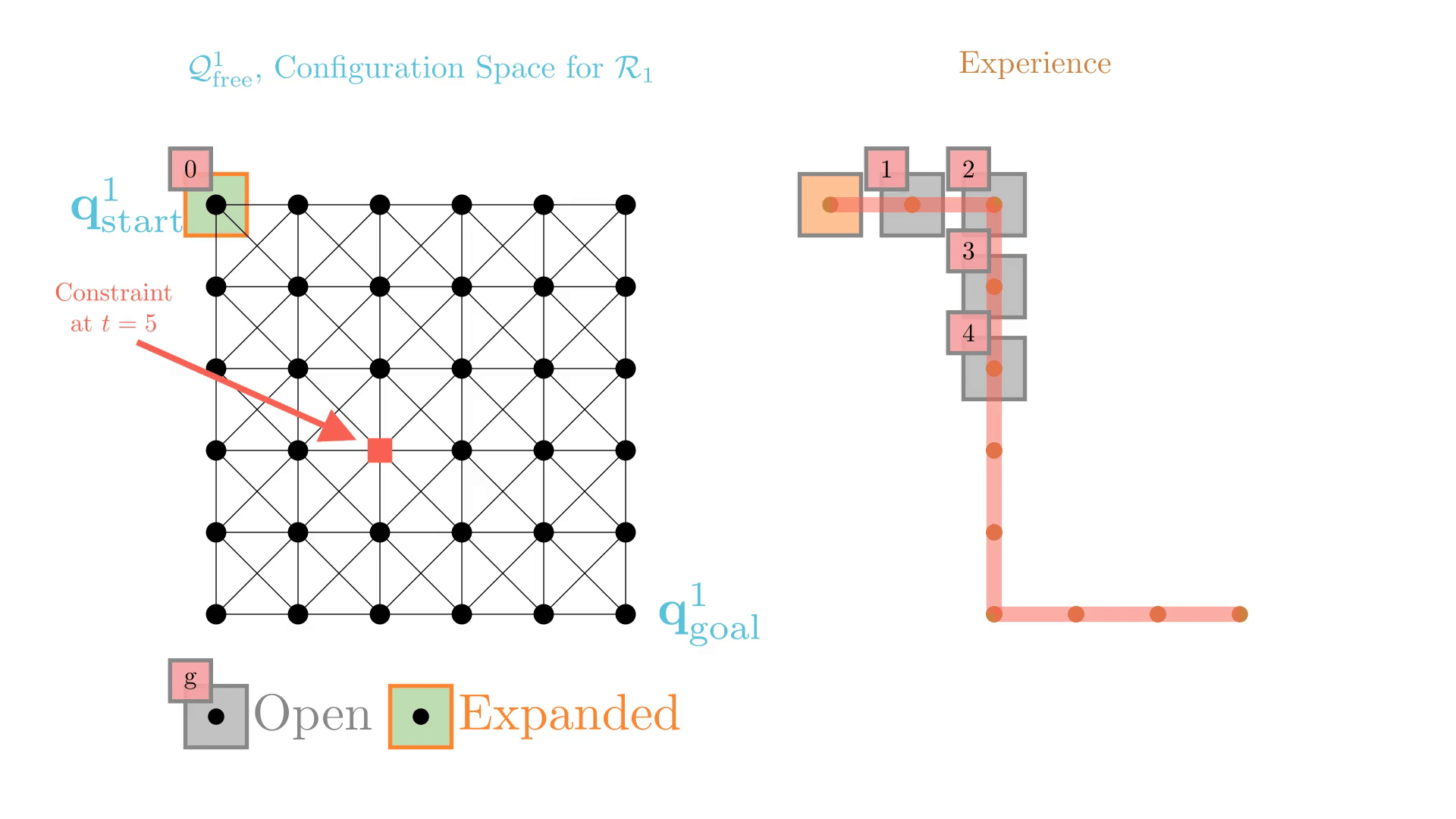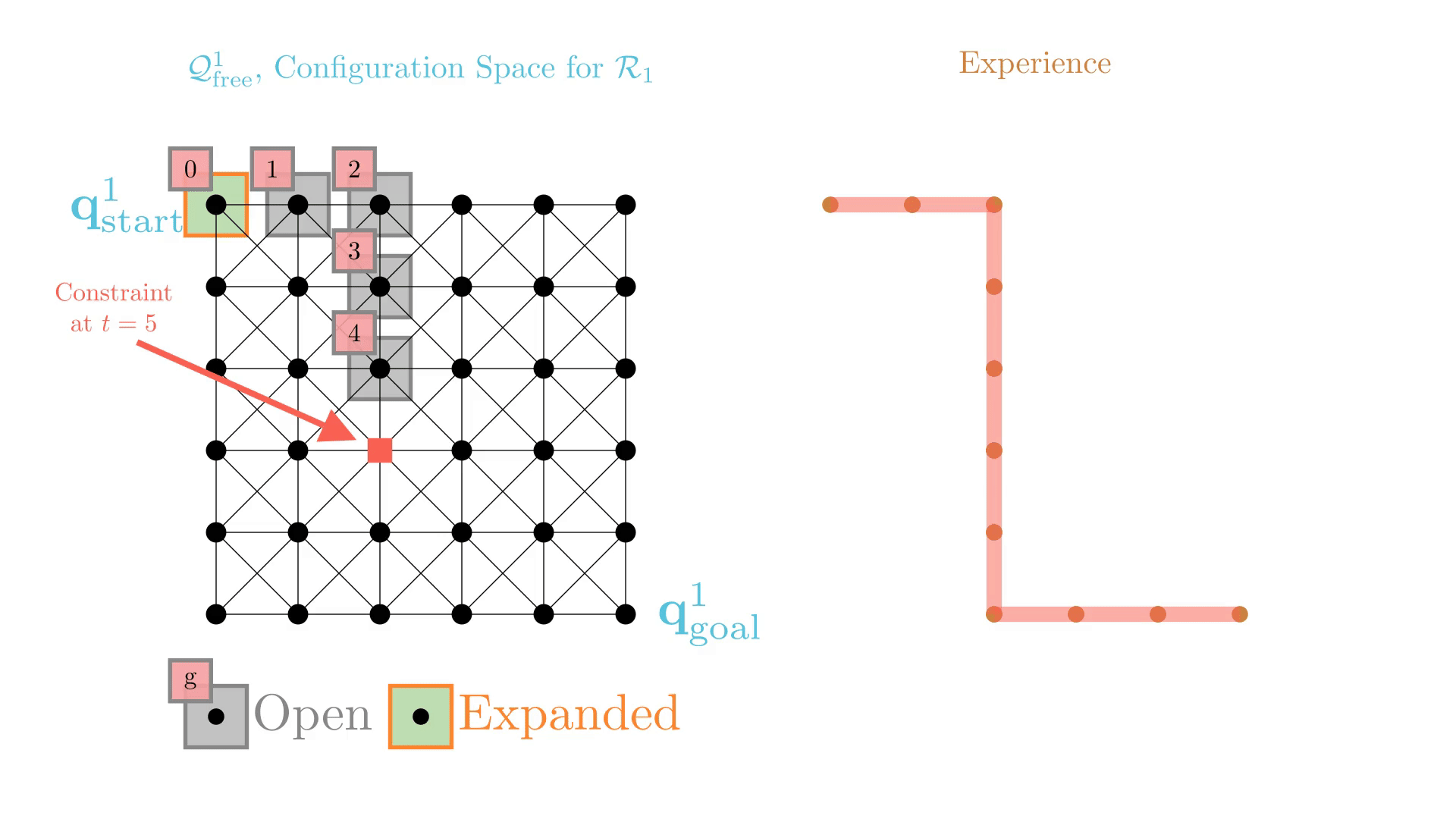
Successive single-agent planner calls are nearly identical.
-> CBS may require many replanning calls to find a solution.
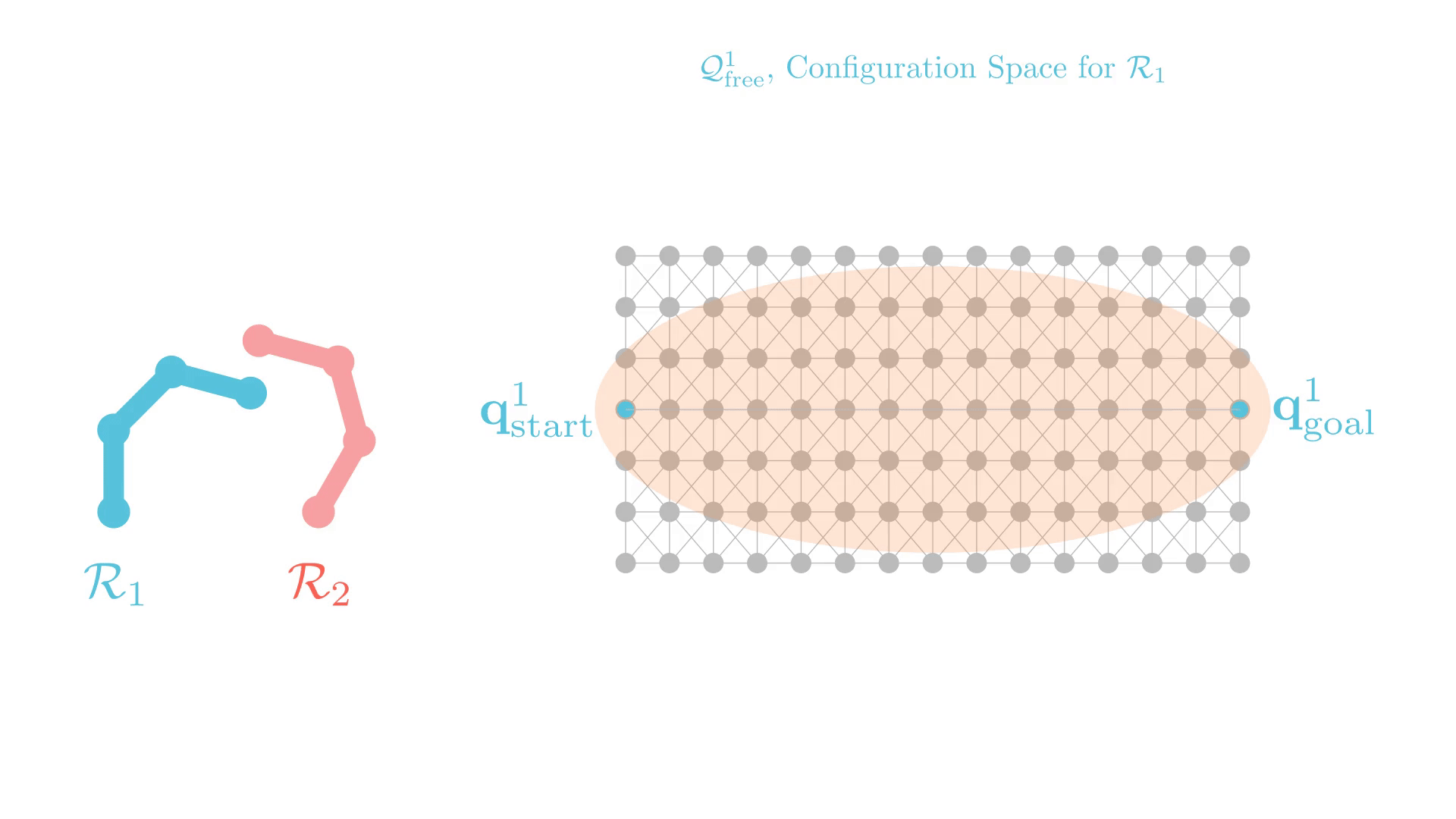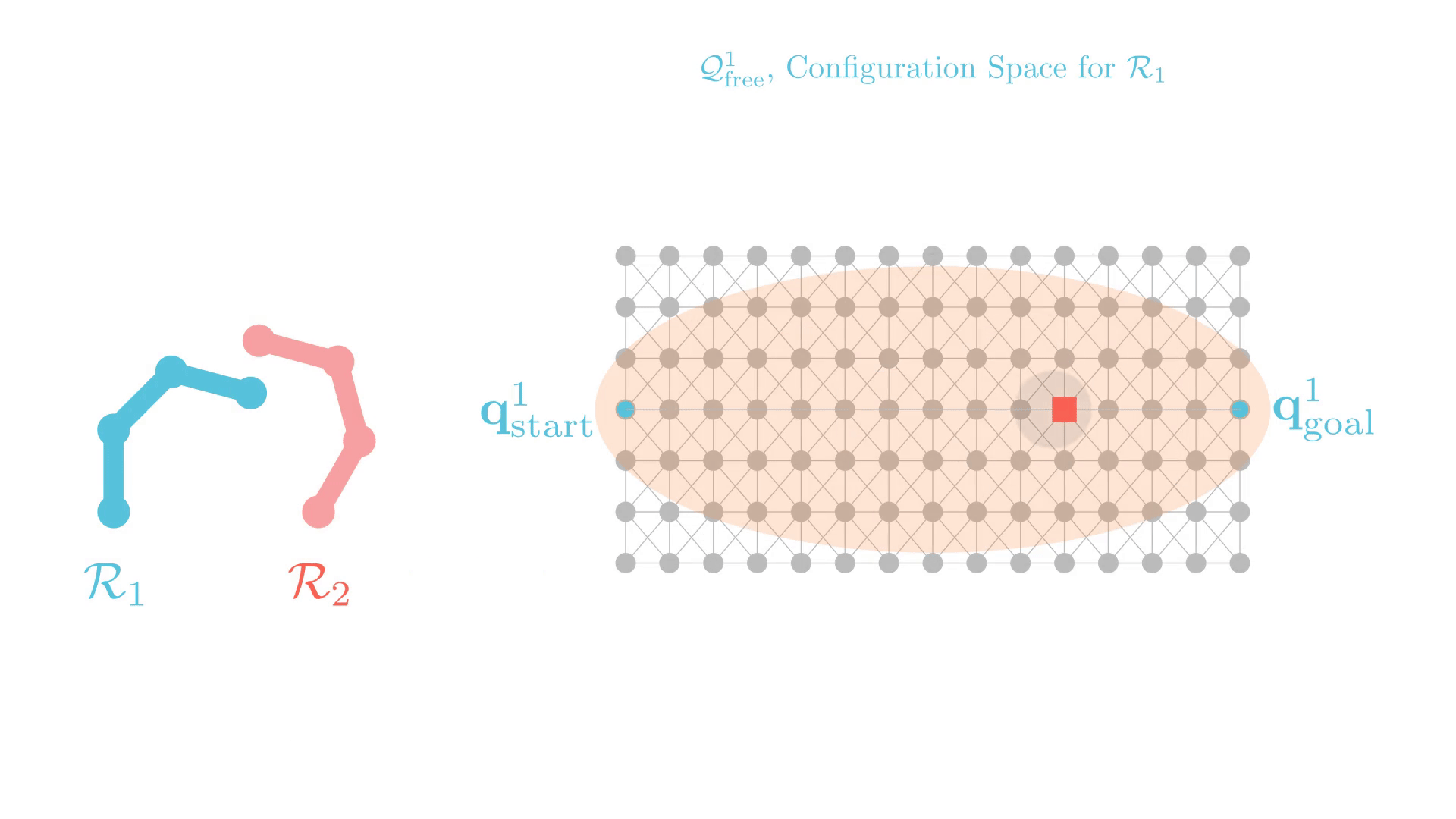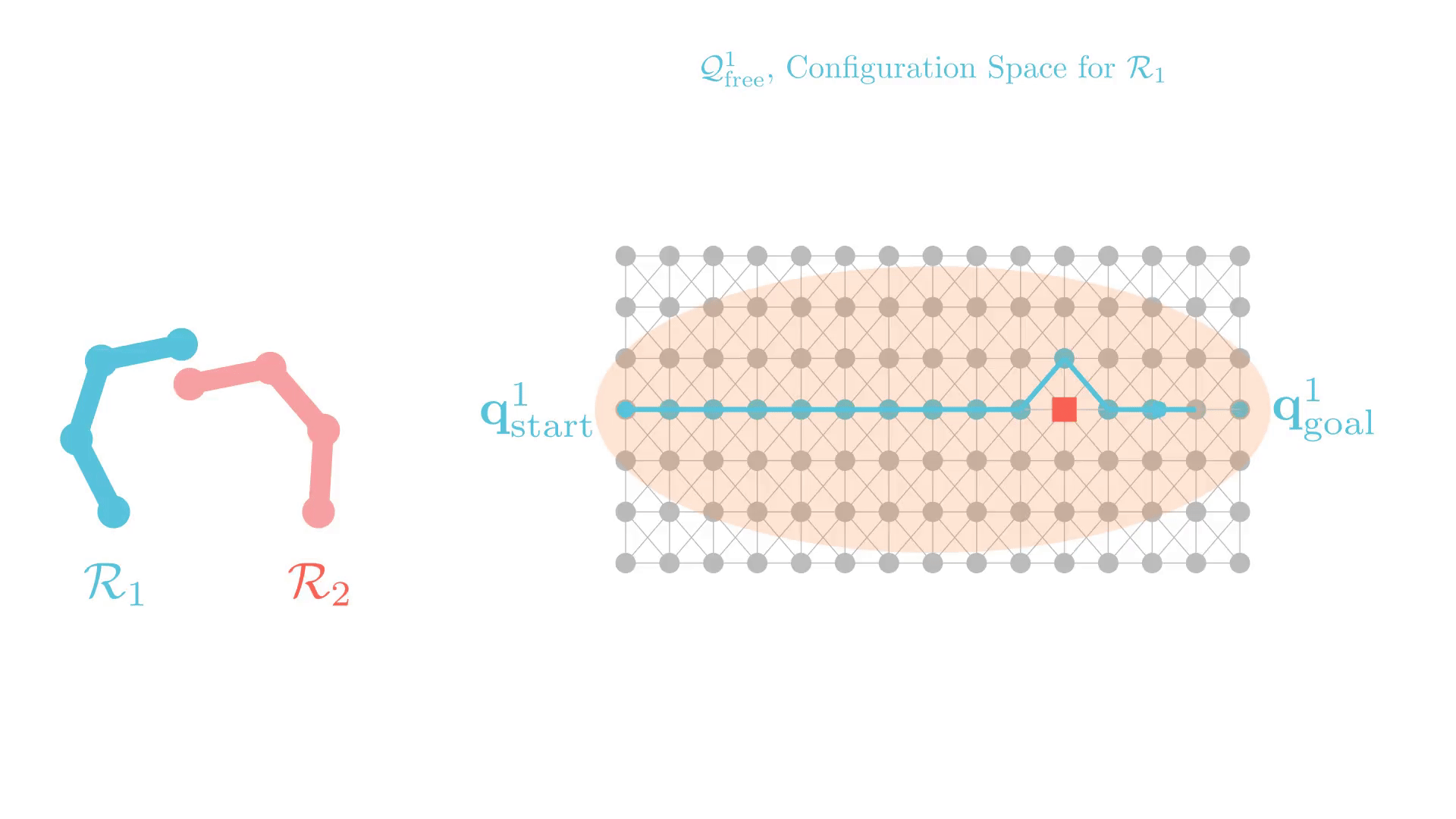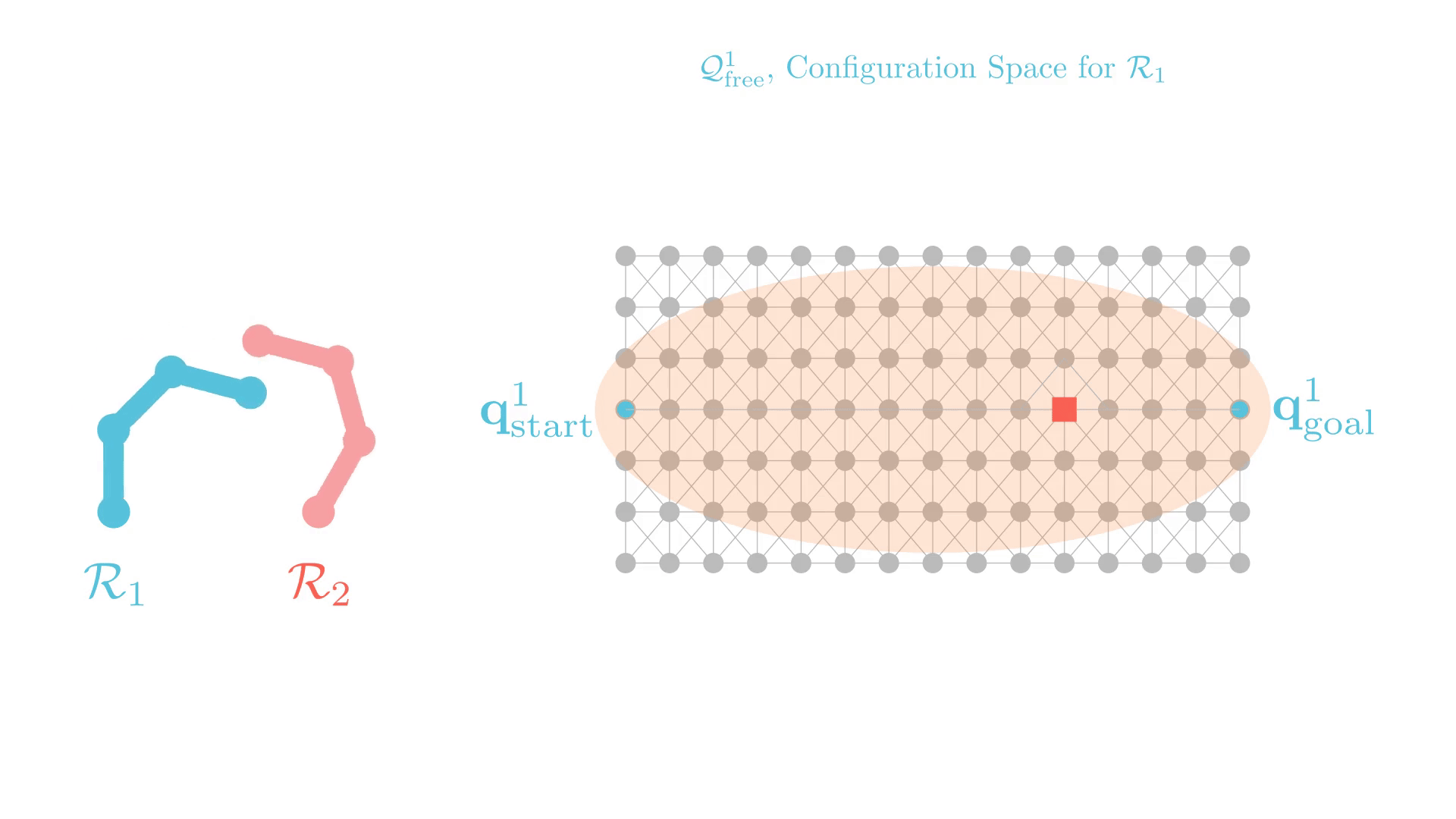
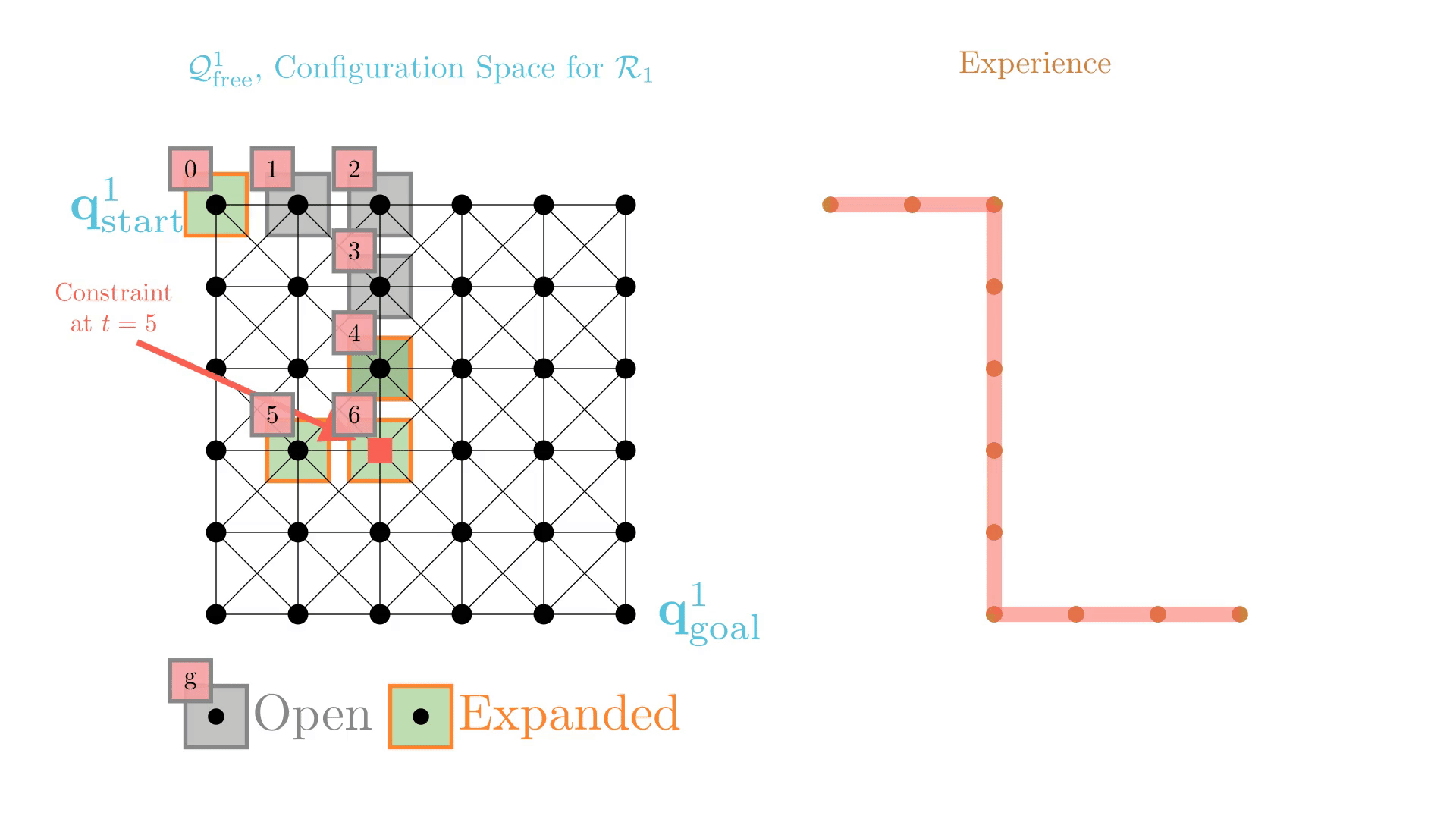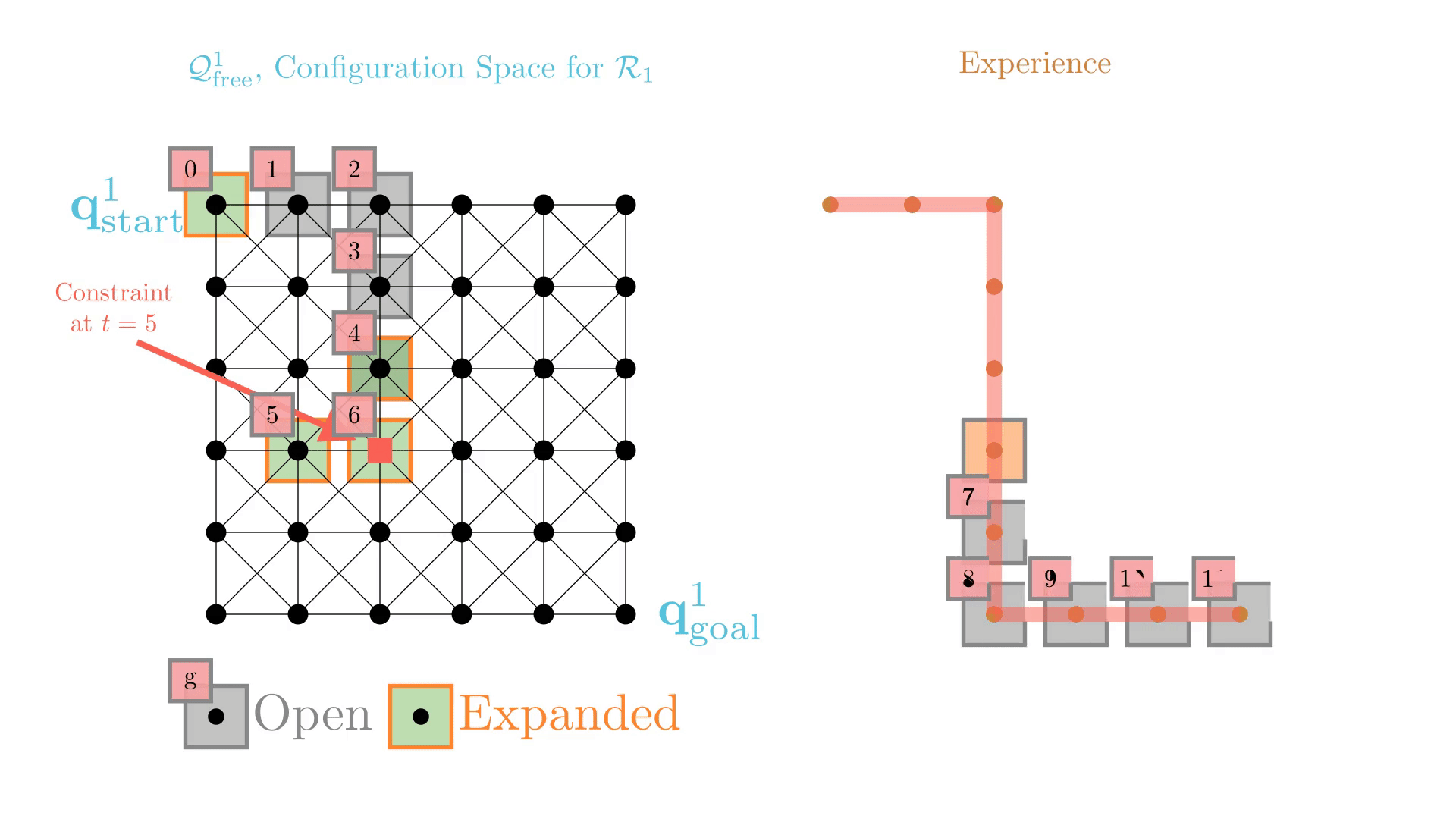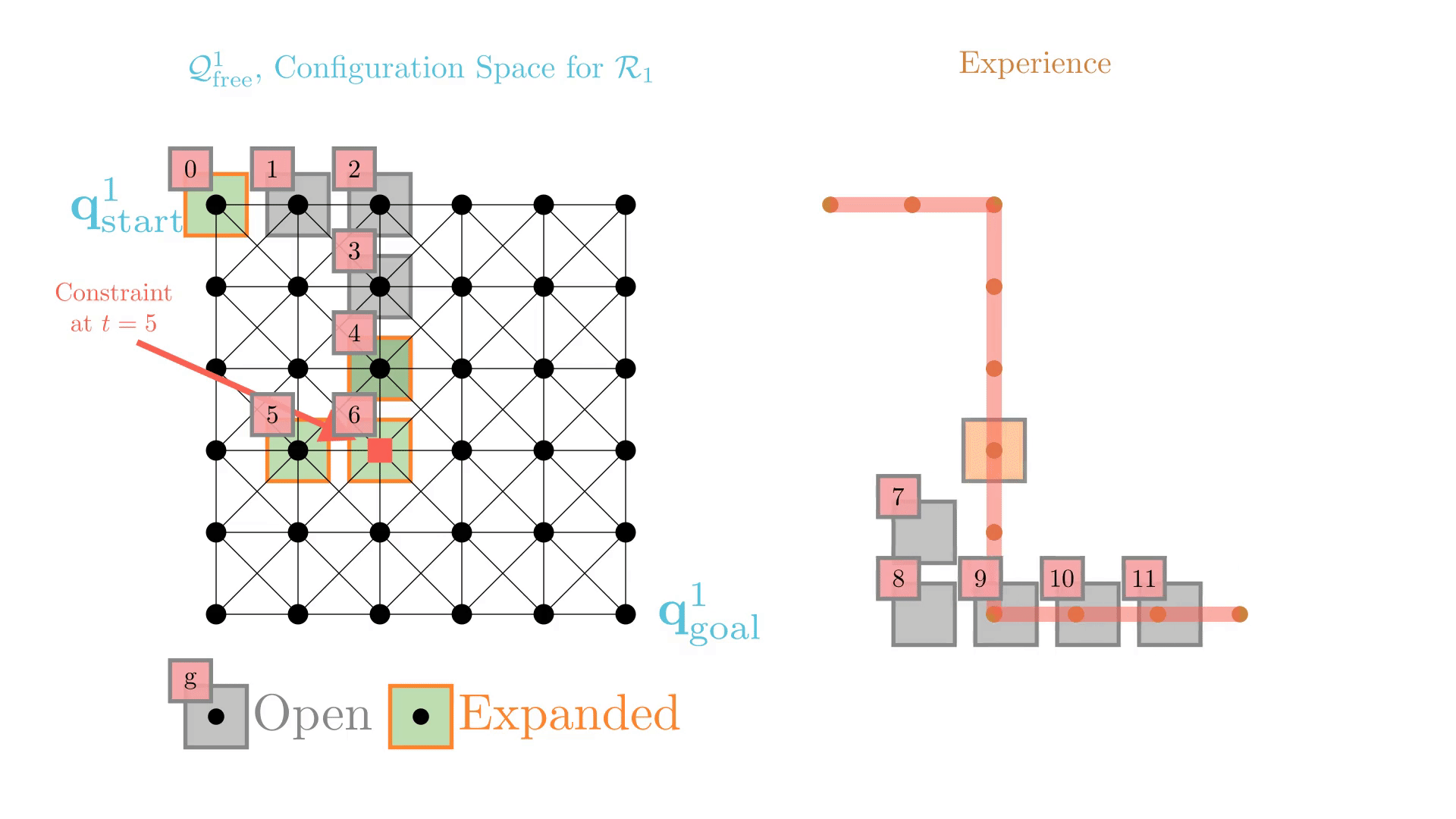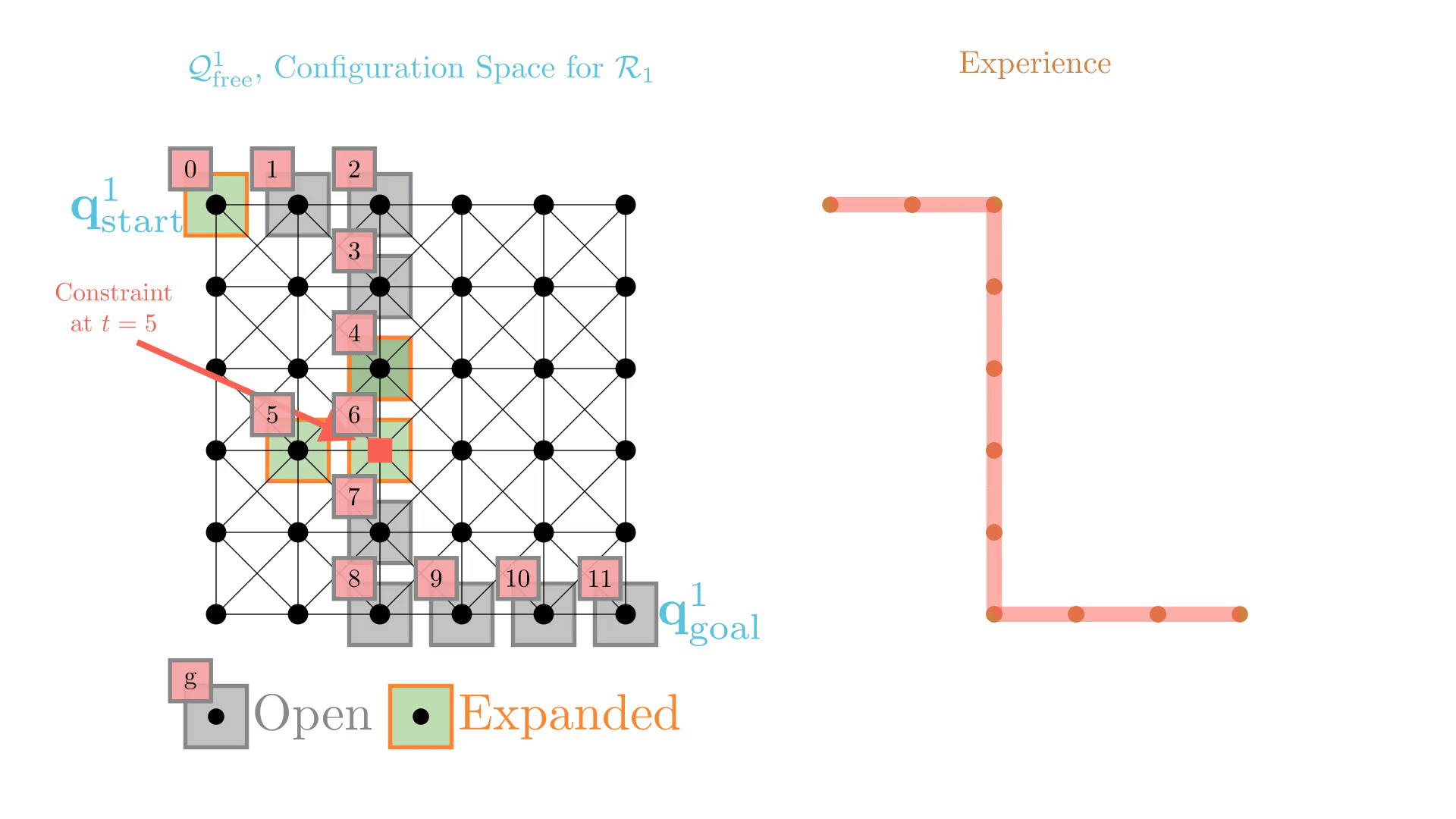
Experience-Accelerated Search
The planning graph remains the same
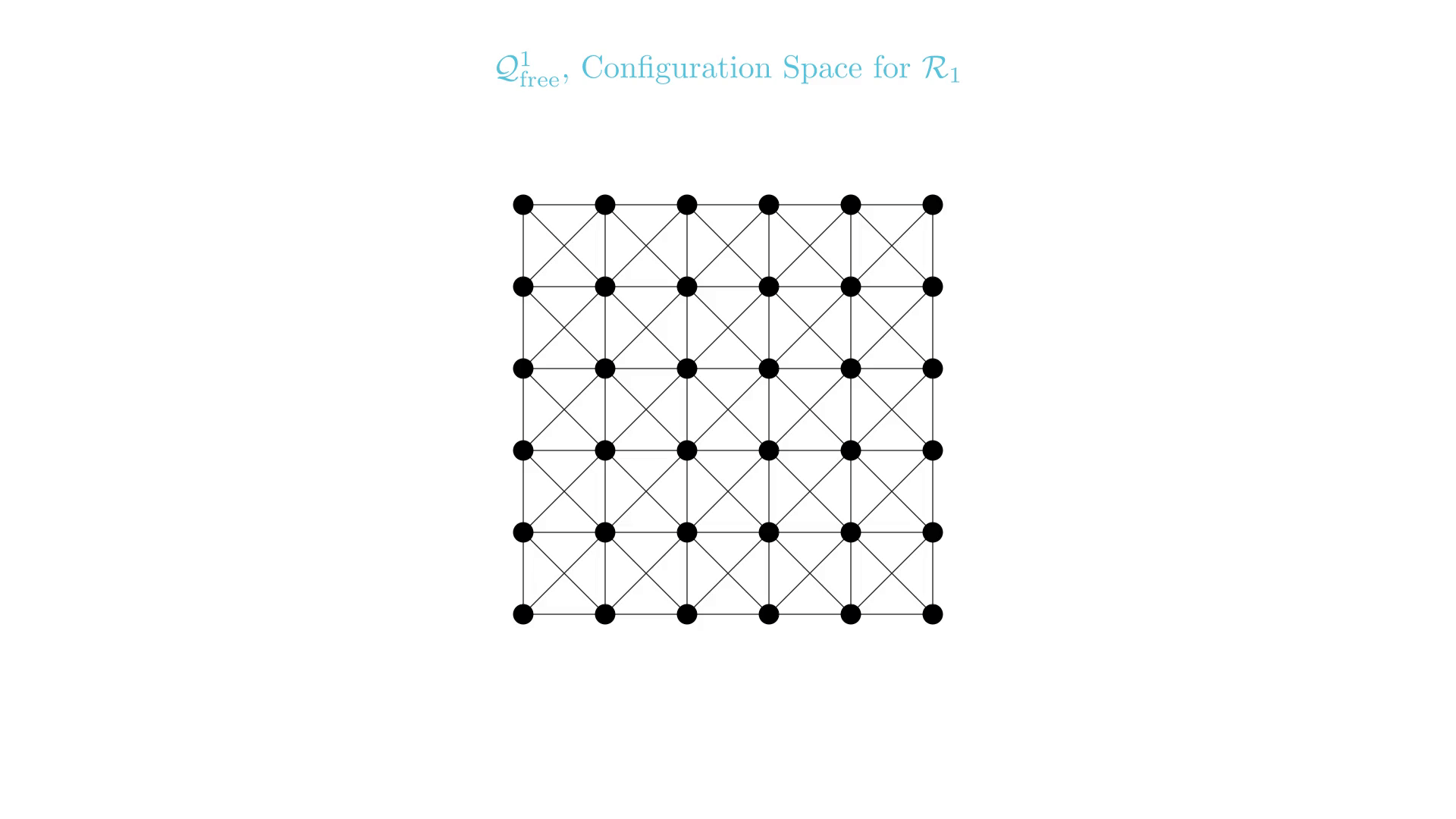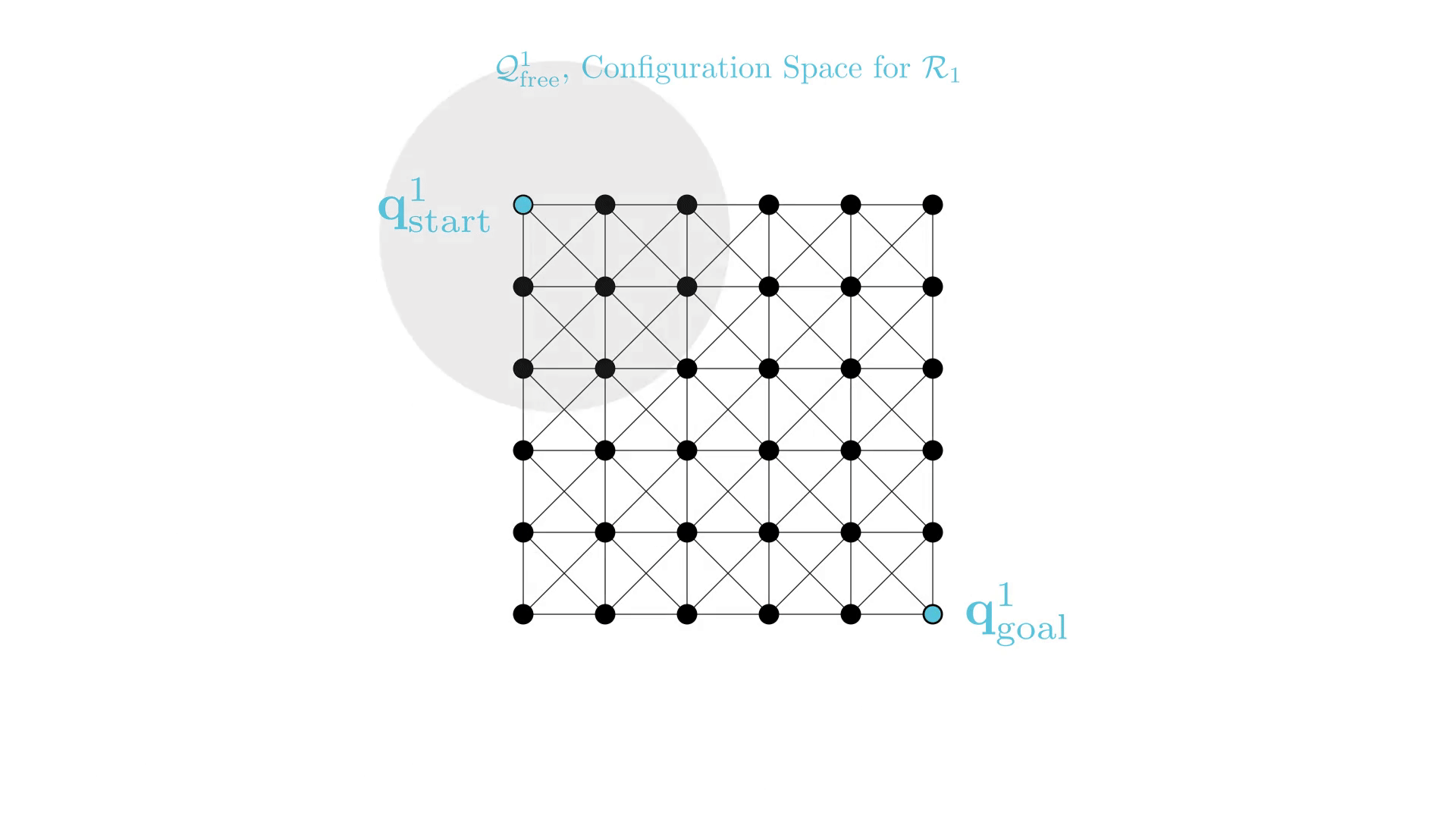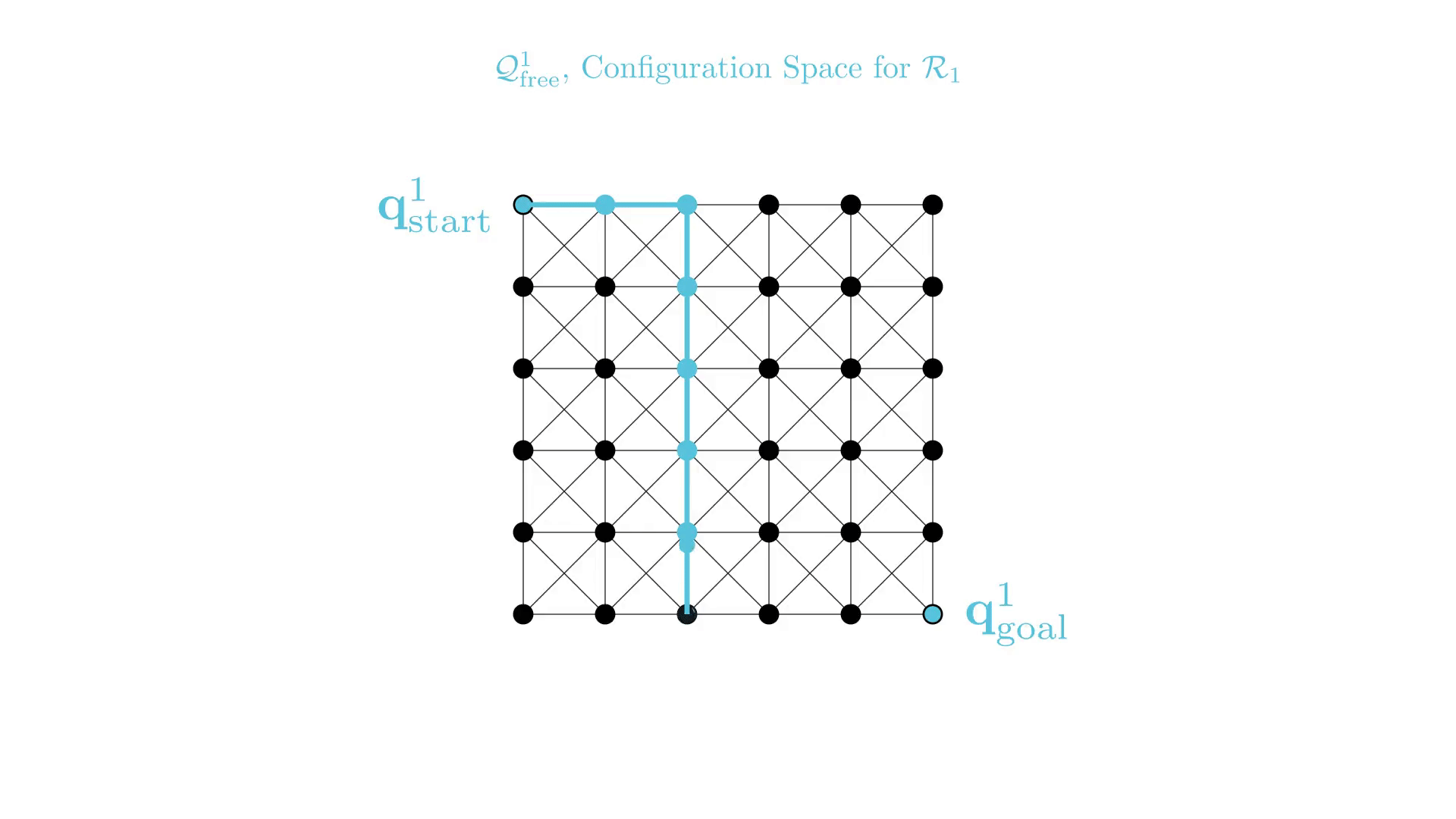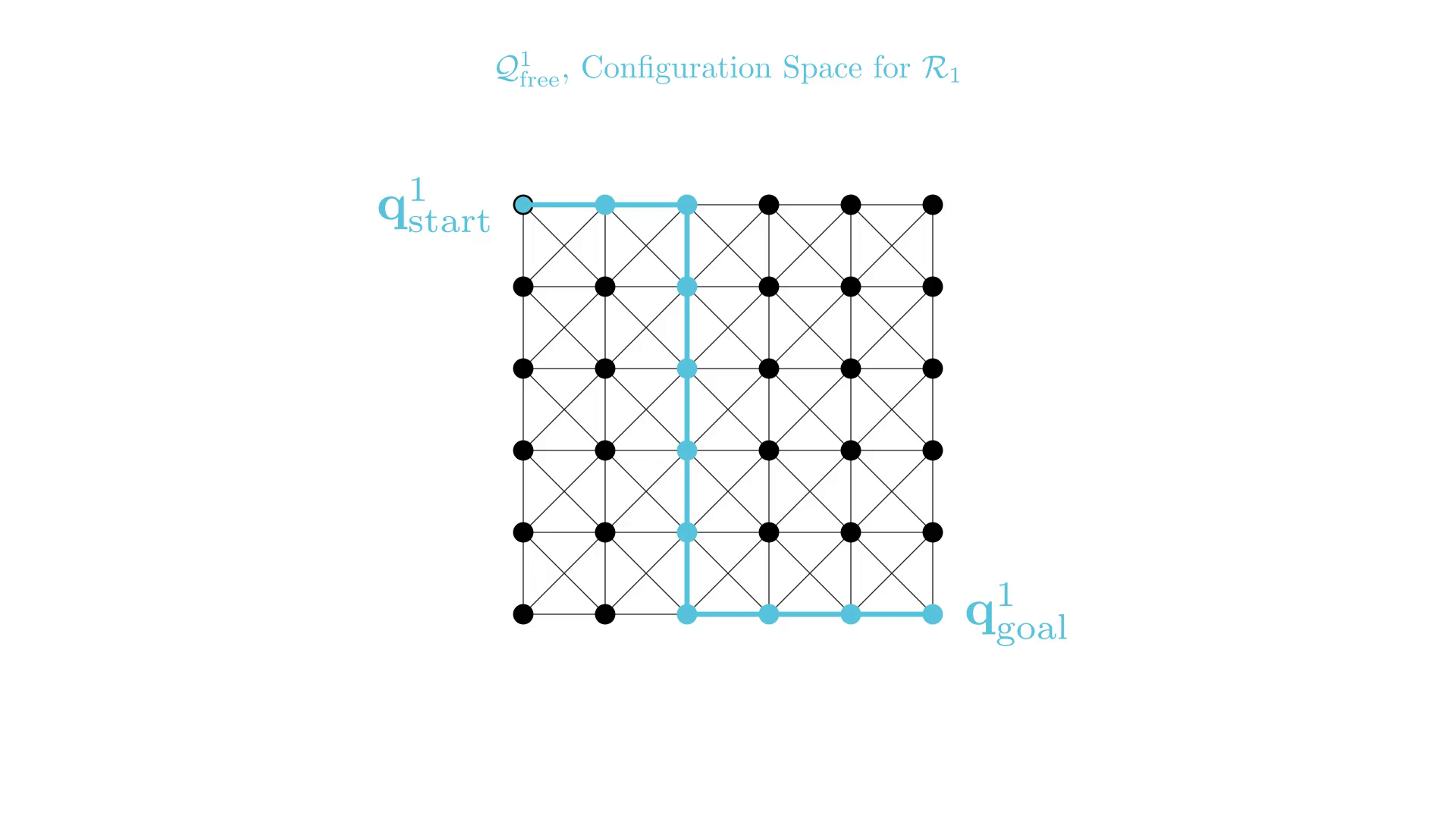
Start and goal states remain the same between replanning calls
The path segments before and after the constraints are still valid
The only change is the addition of a new constraint
Experience-Accelerated Search
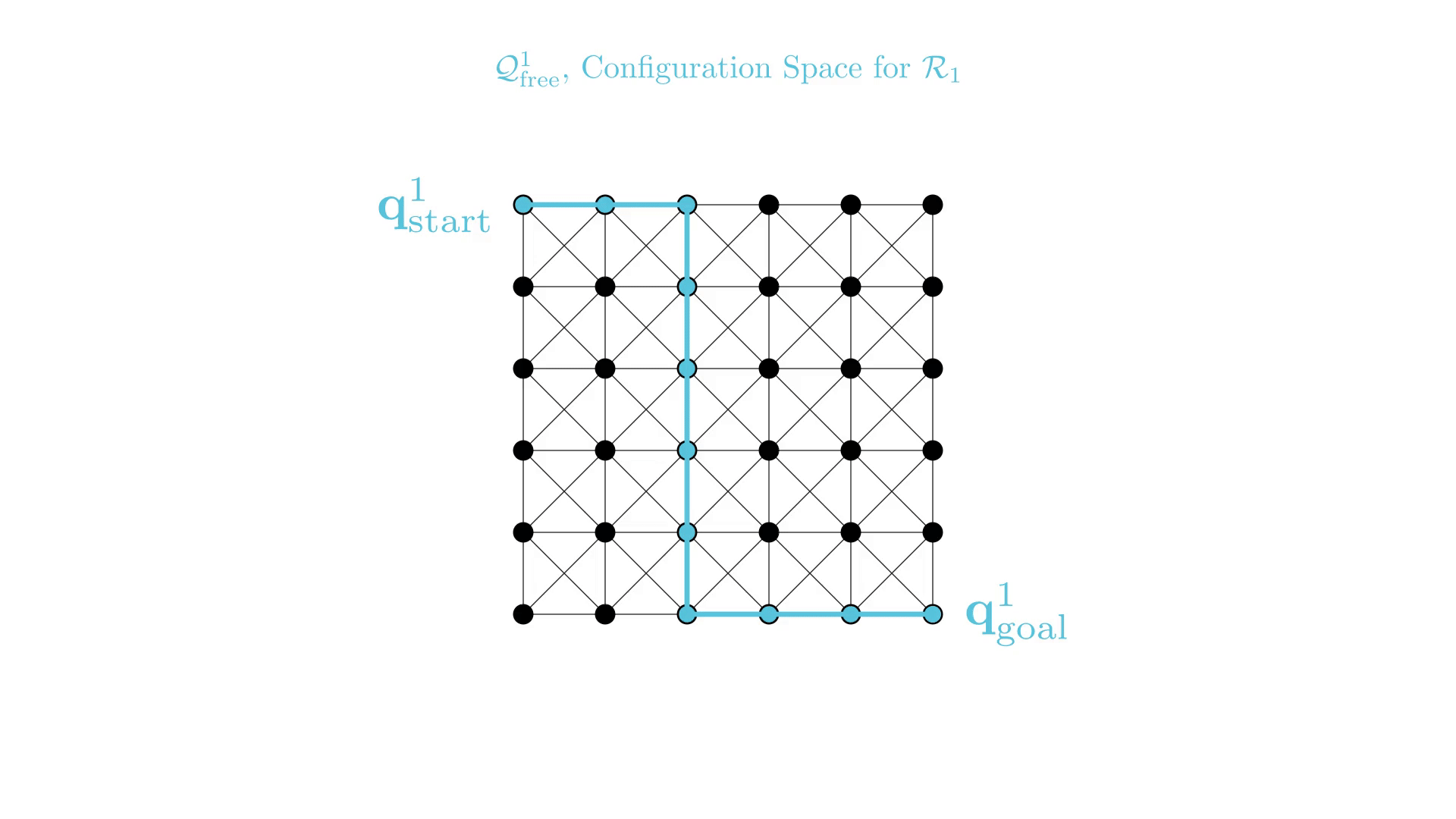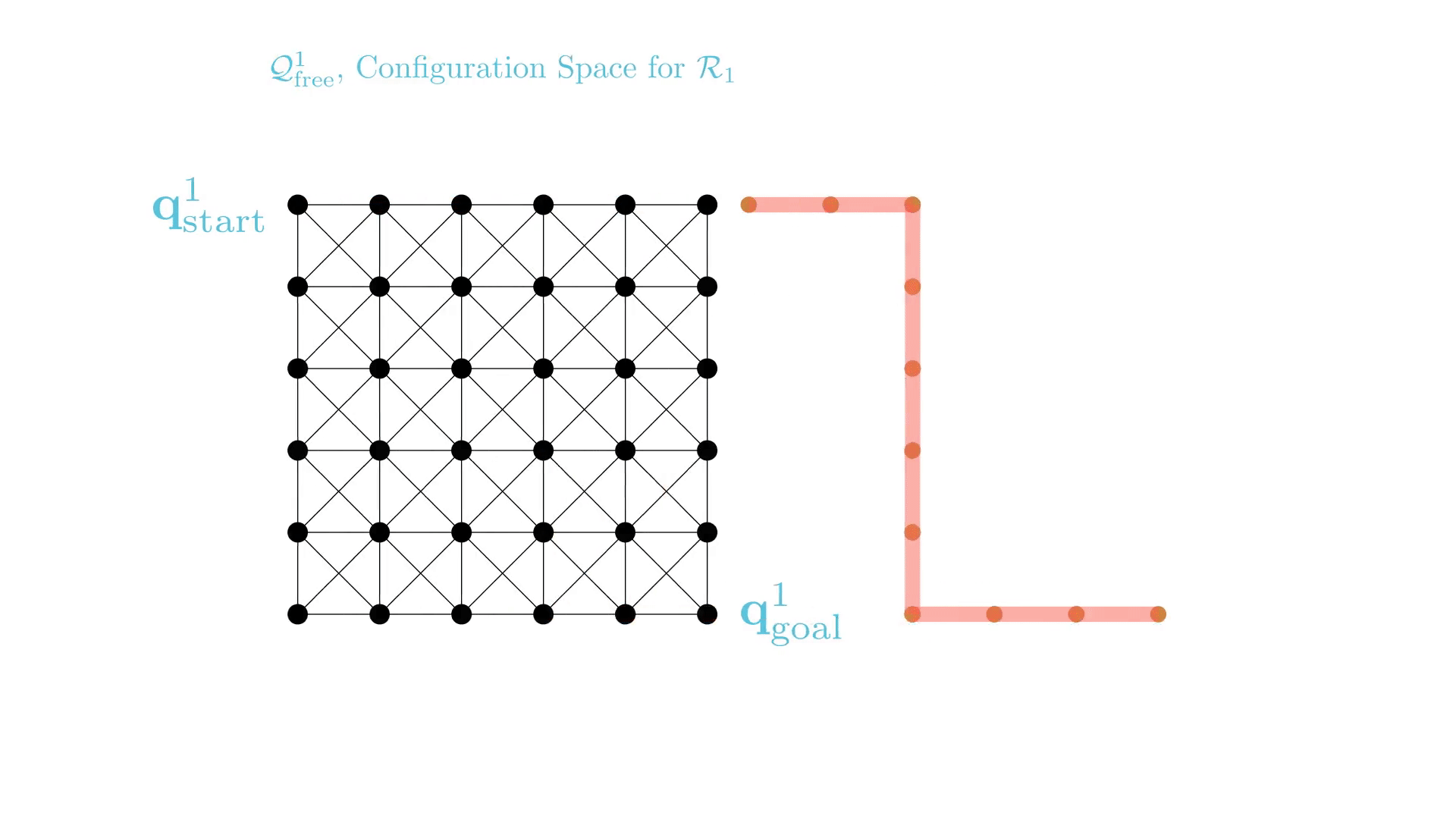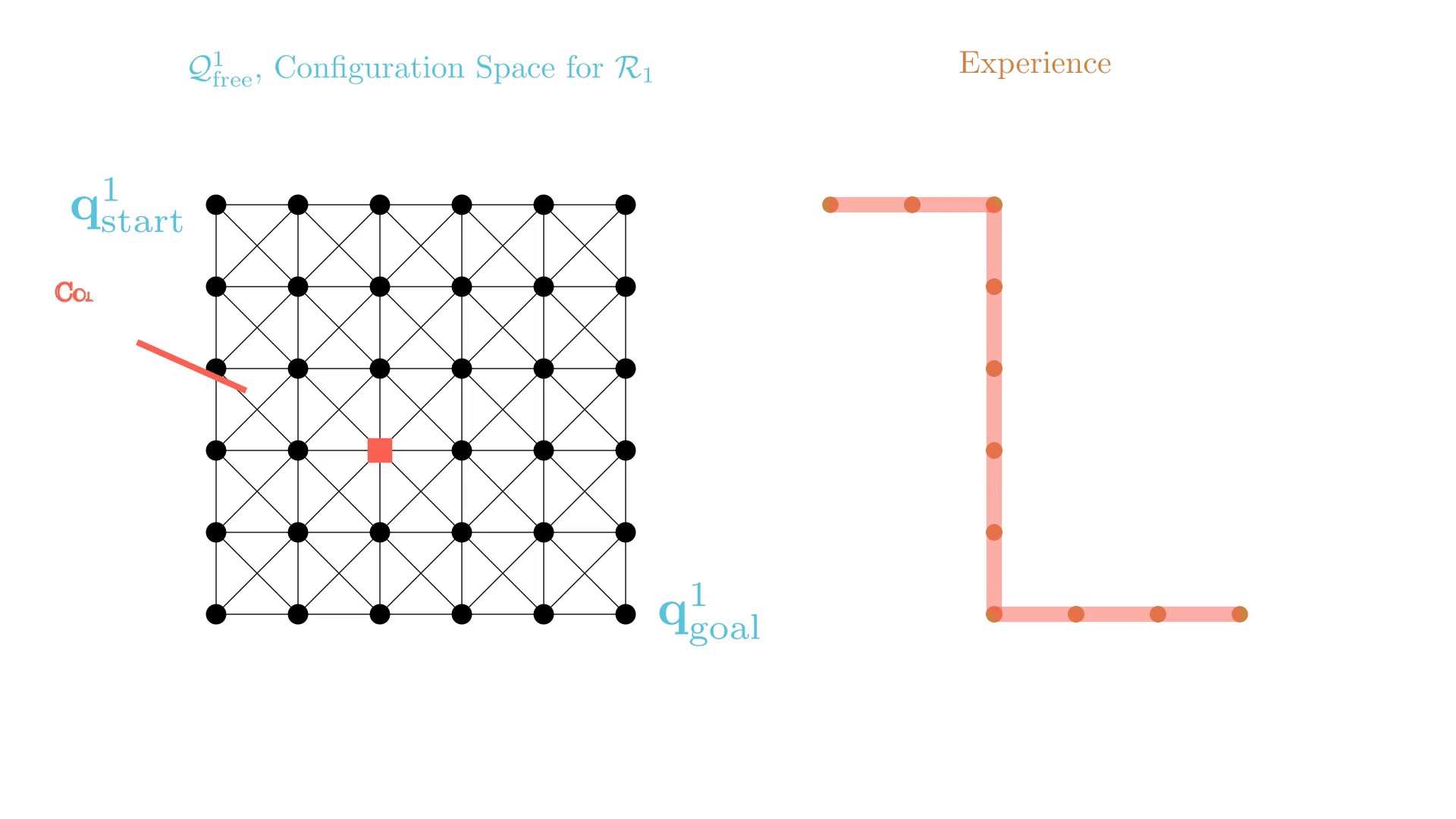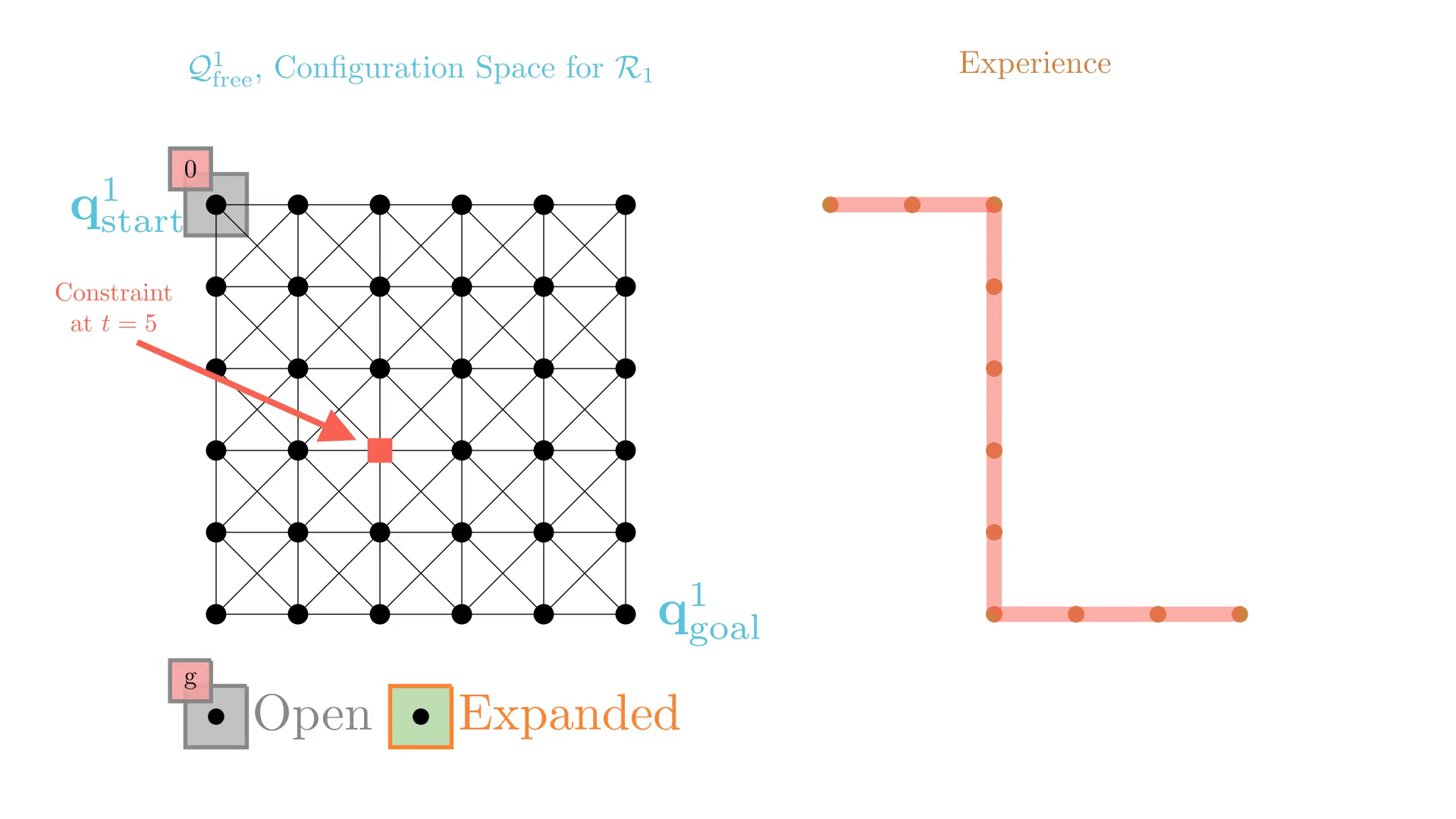
Experience-Accelerated Search
Experience-Accelerated Search
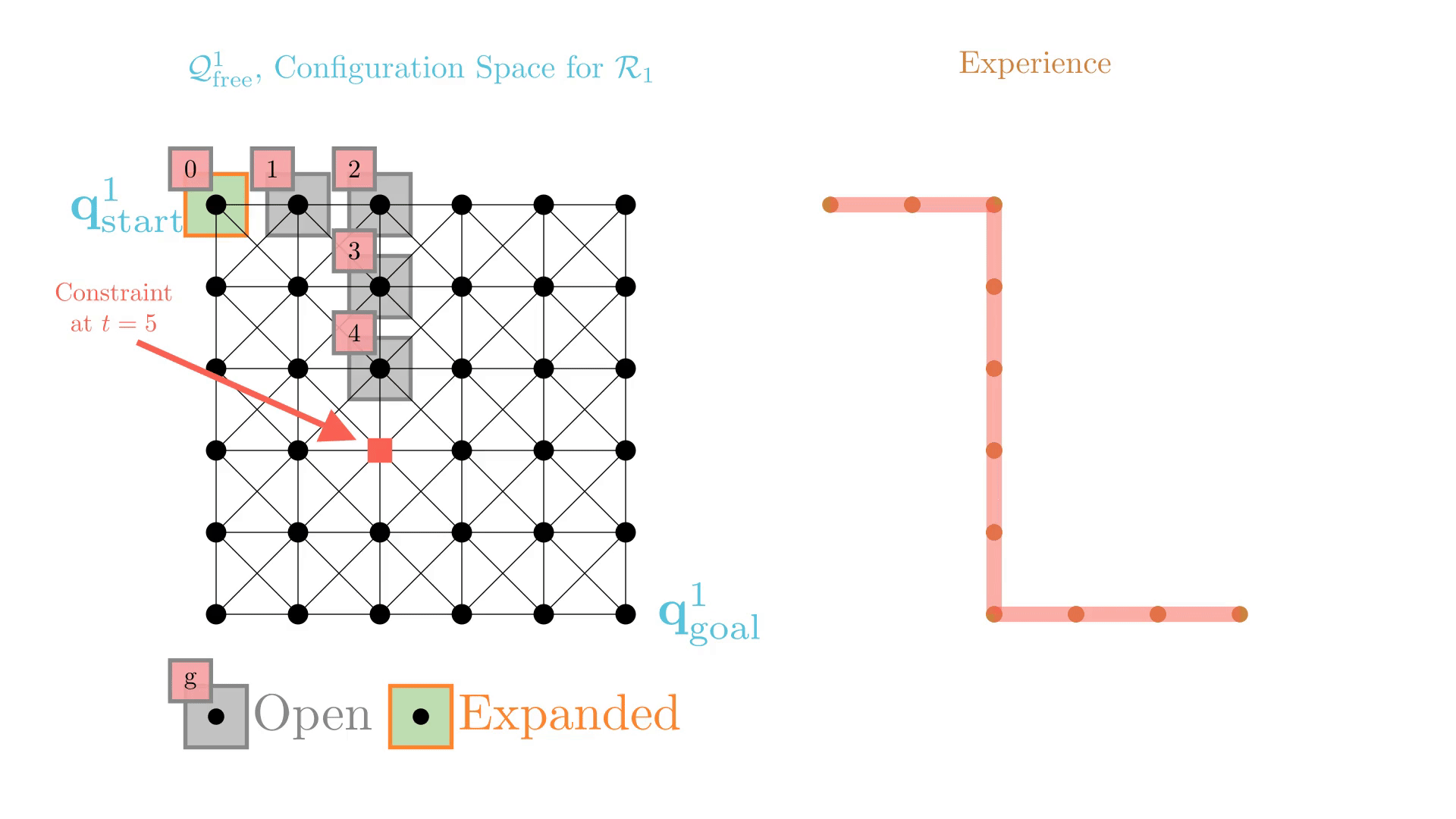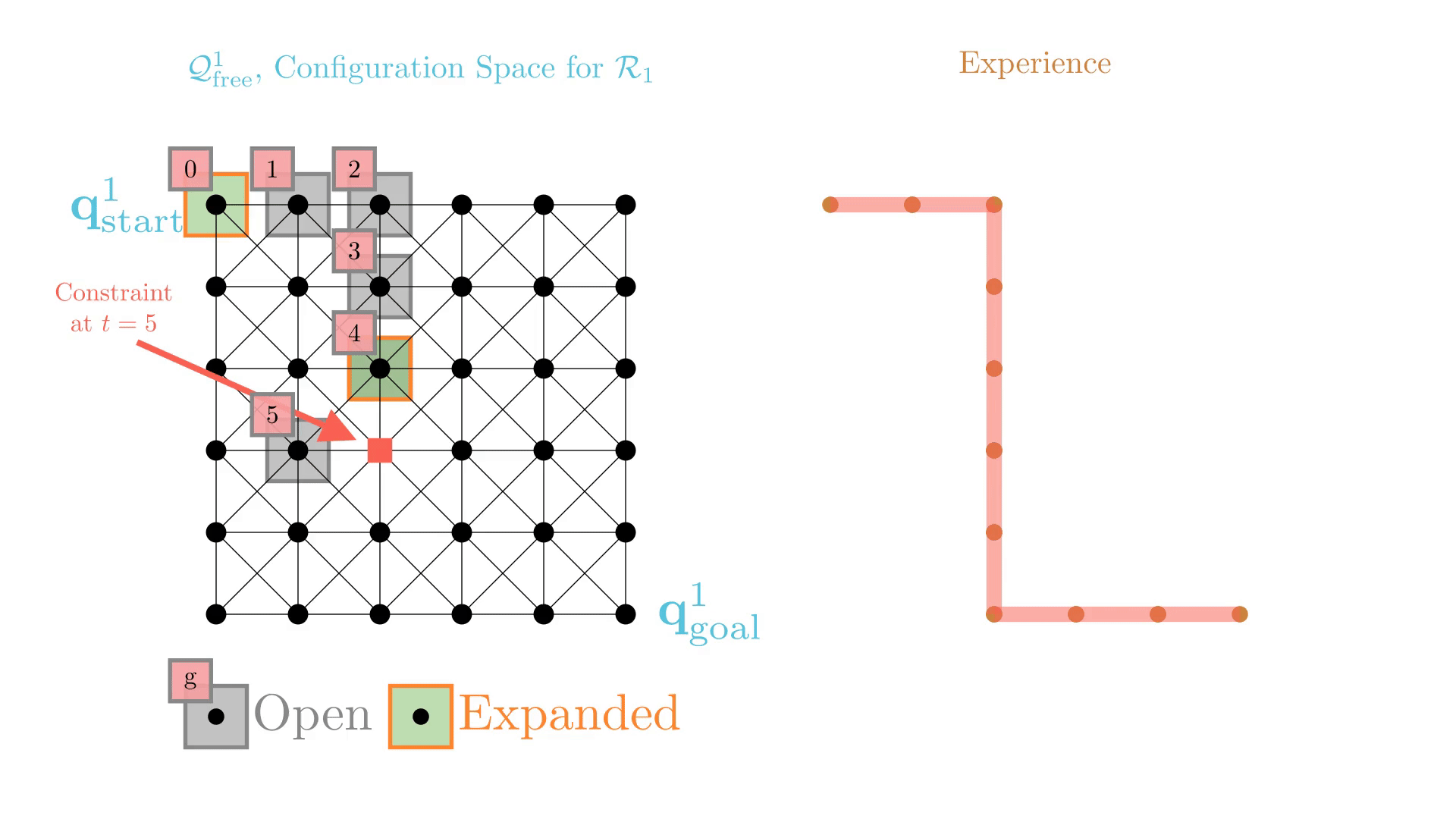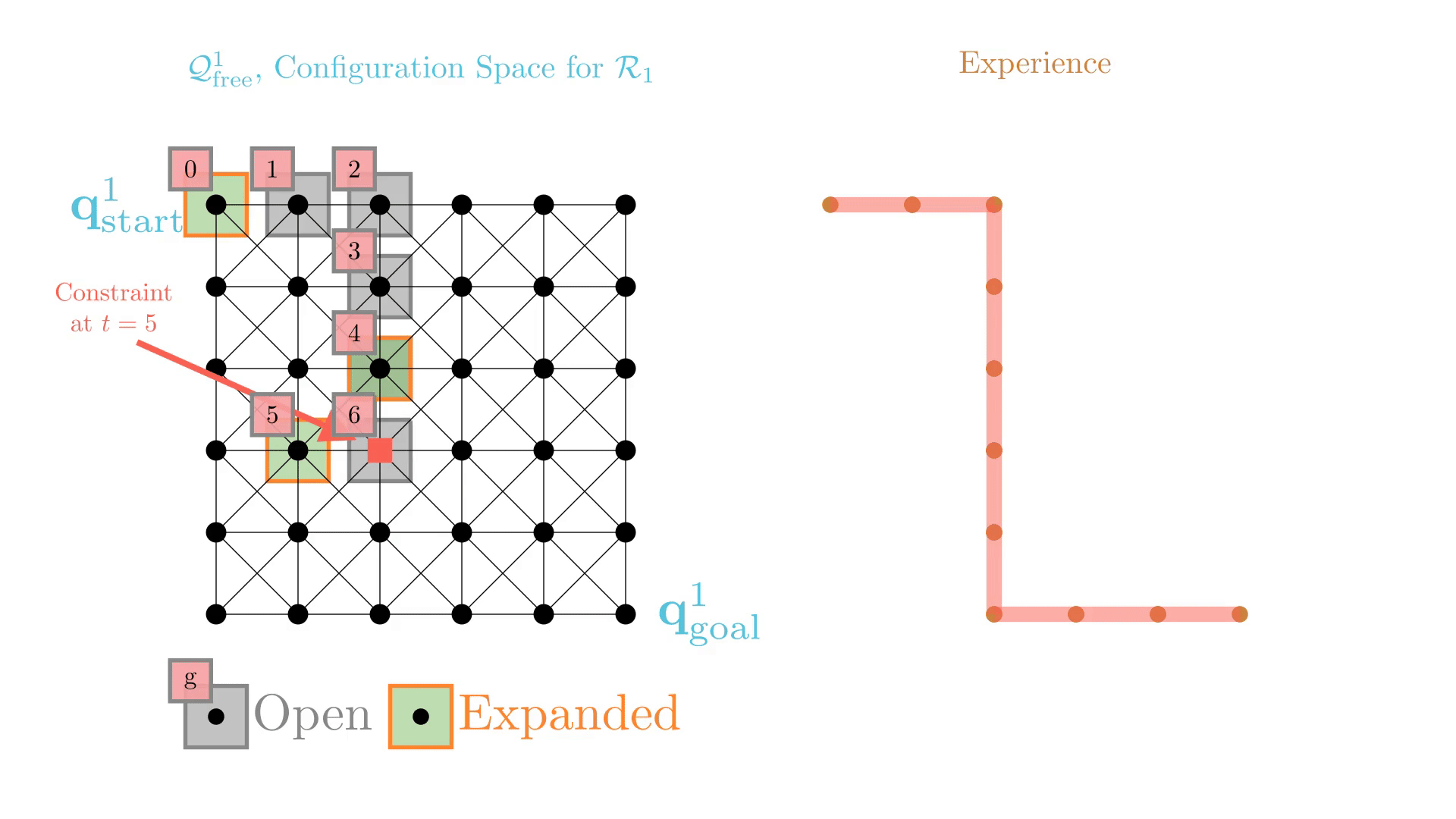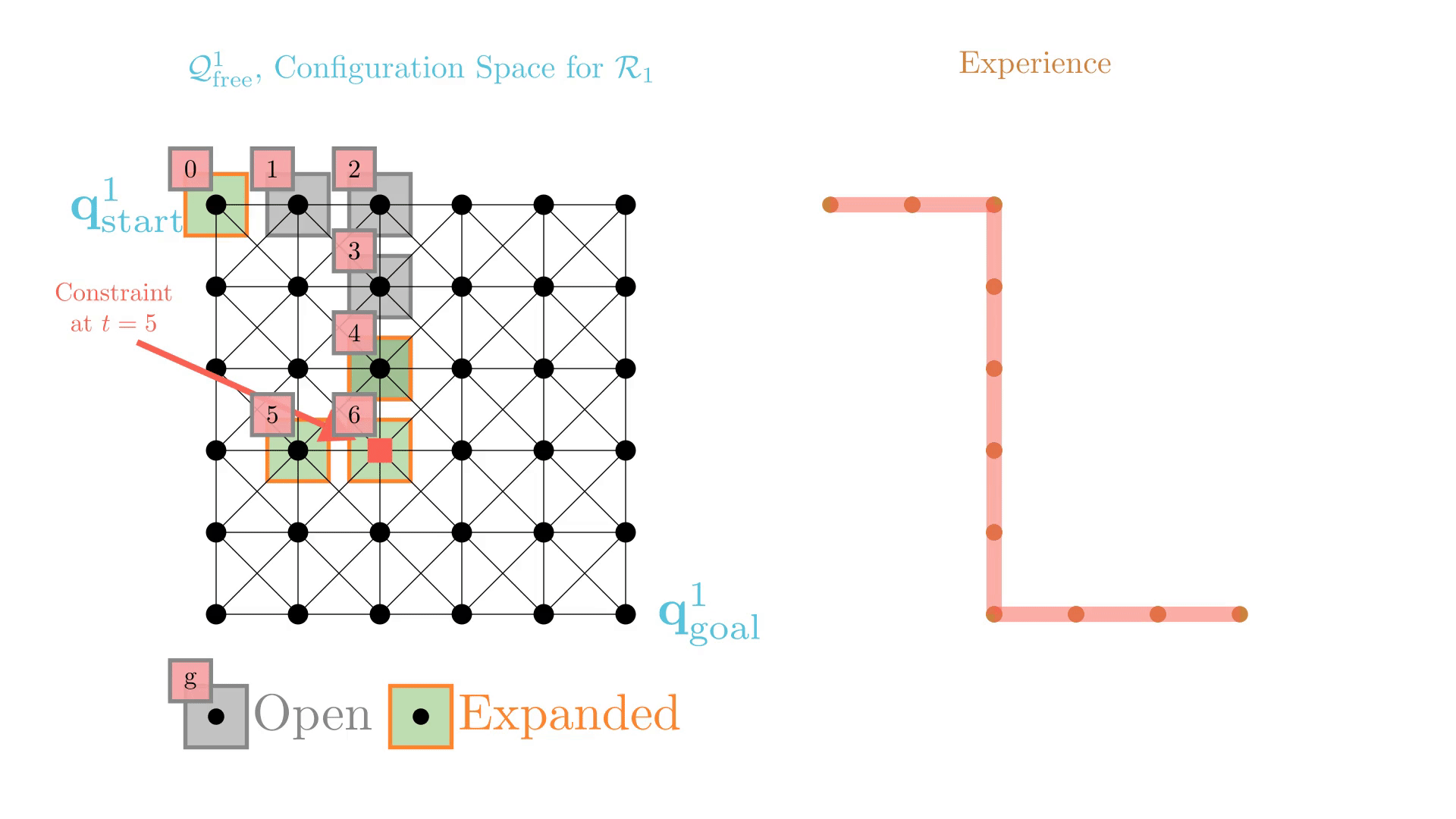
Experience-Accelerated Search
Experience-Accelerated Search
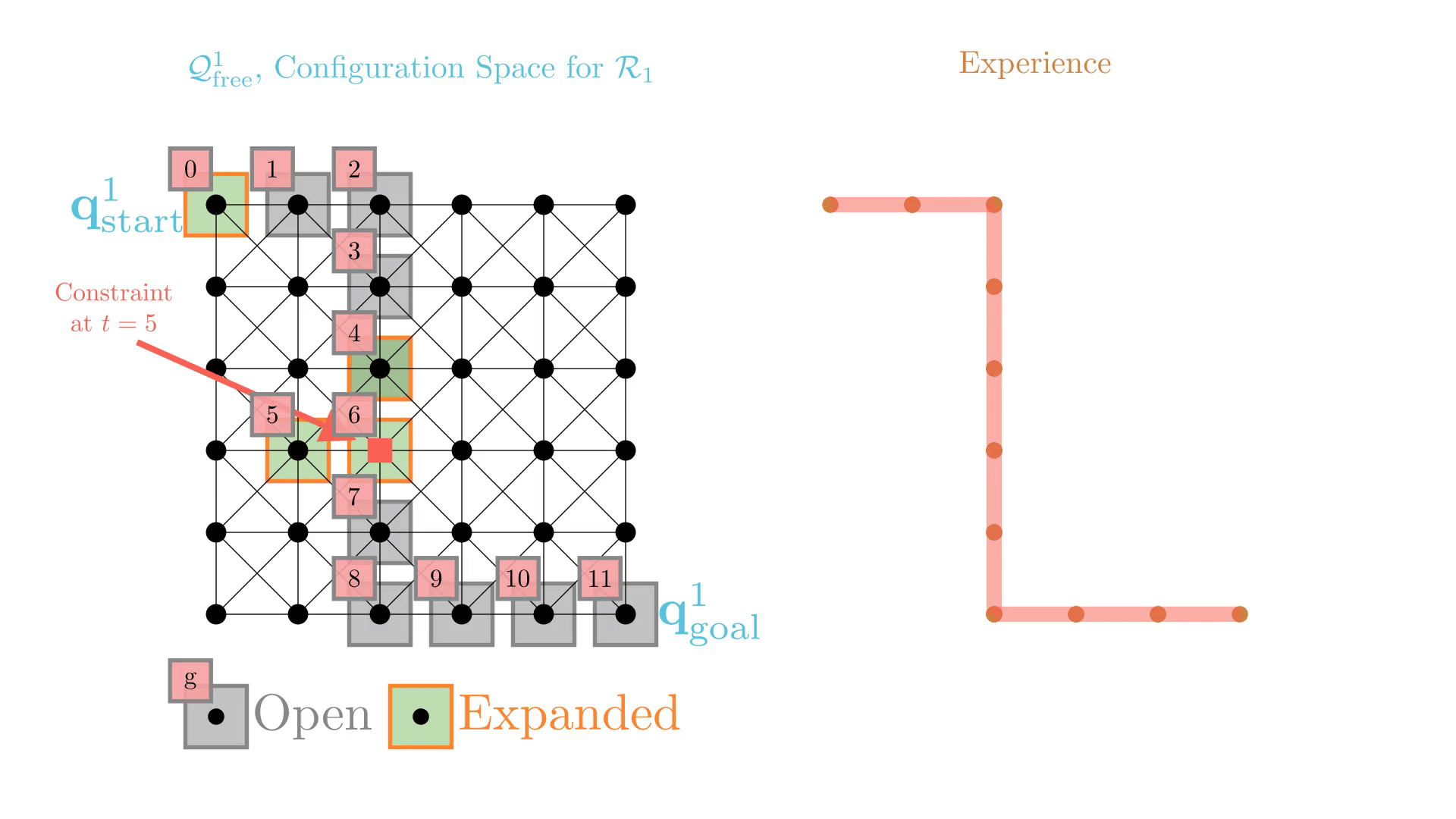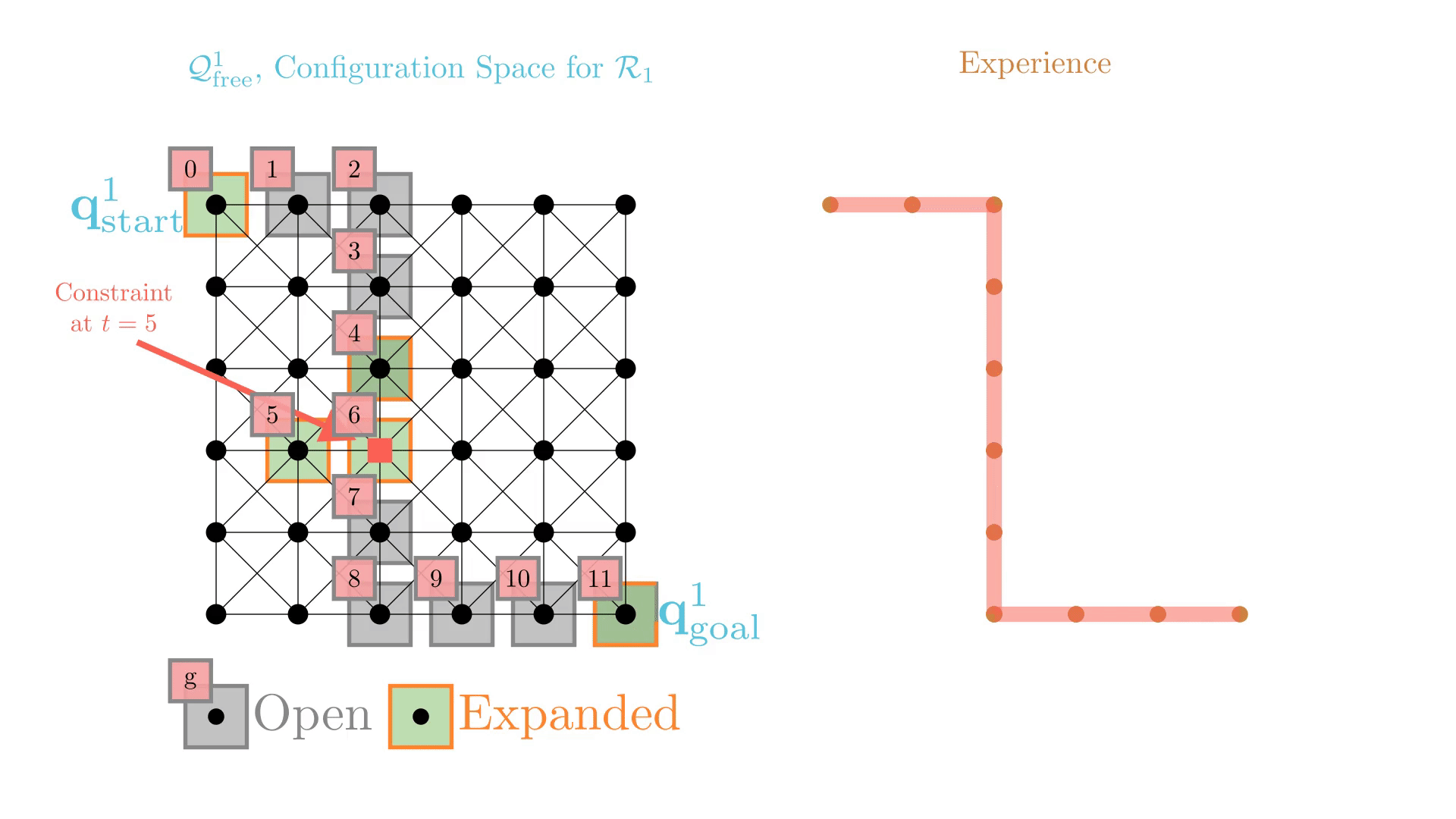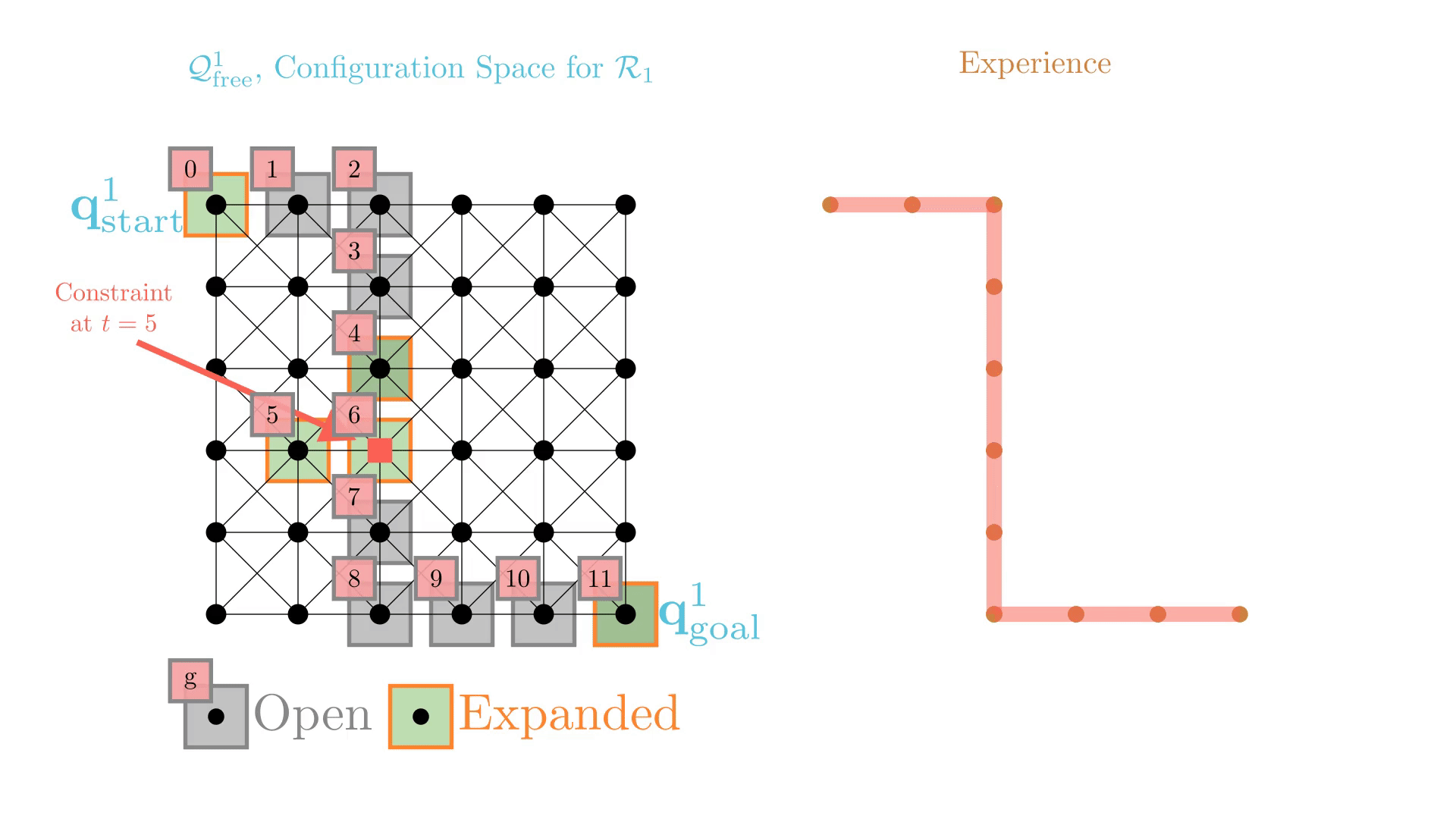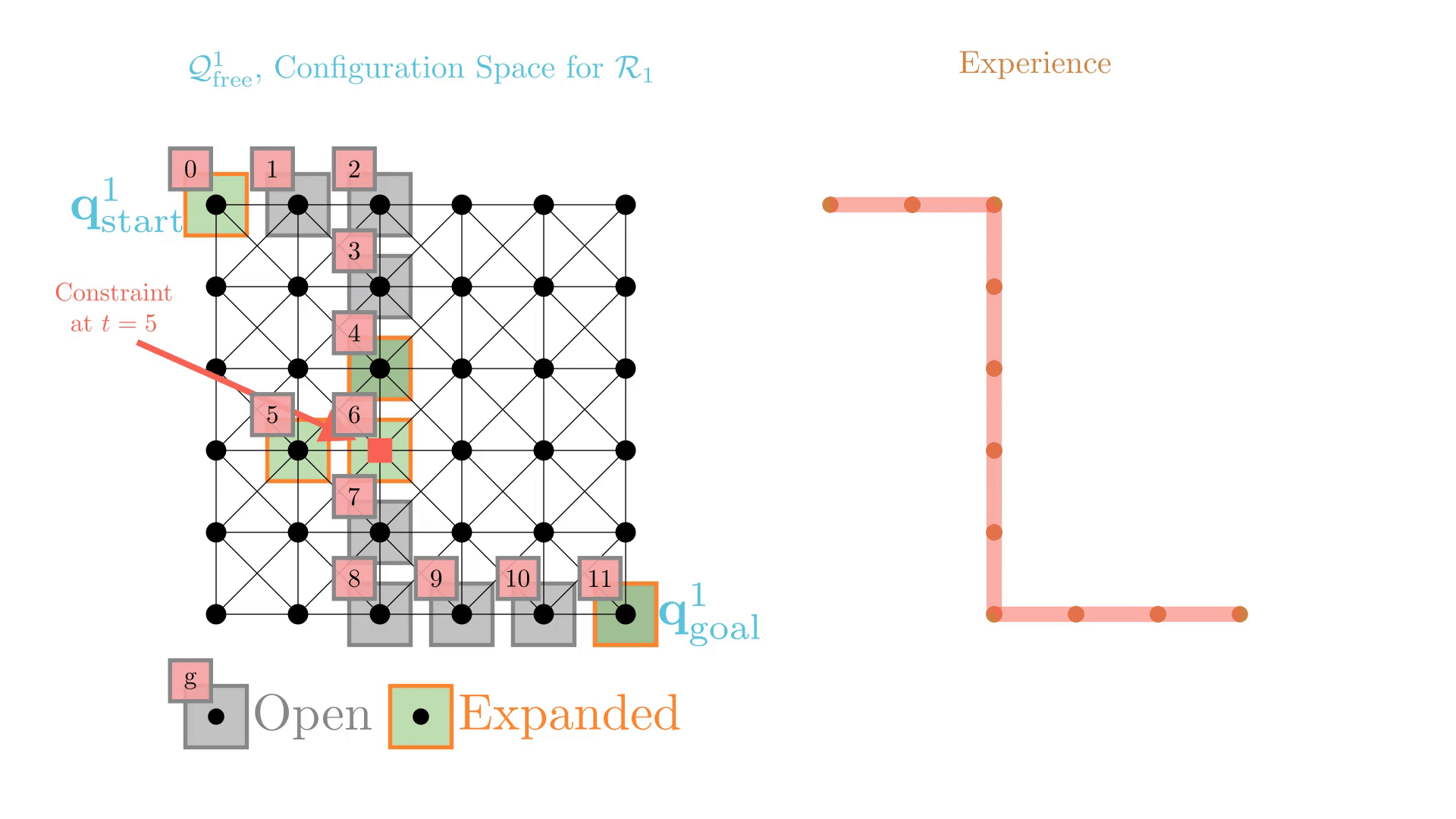
Experience-Accelerated Search
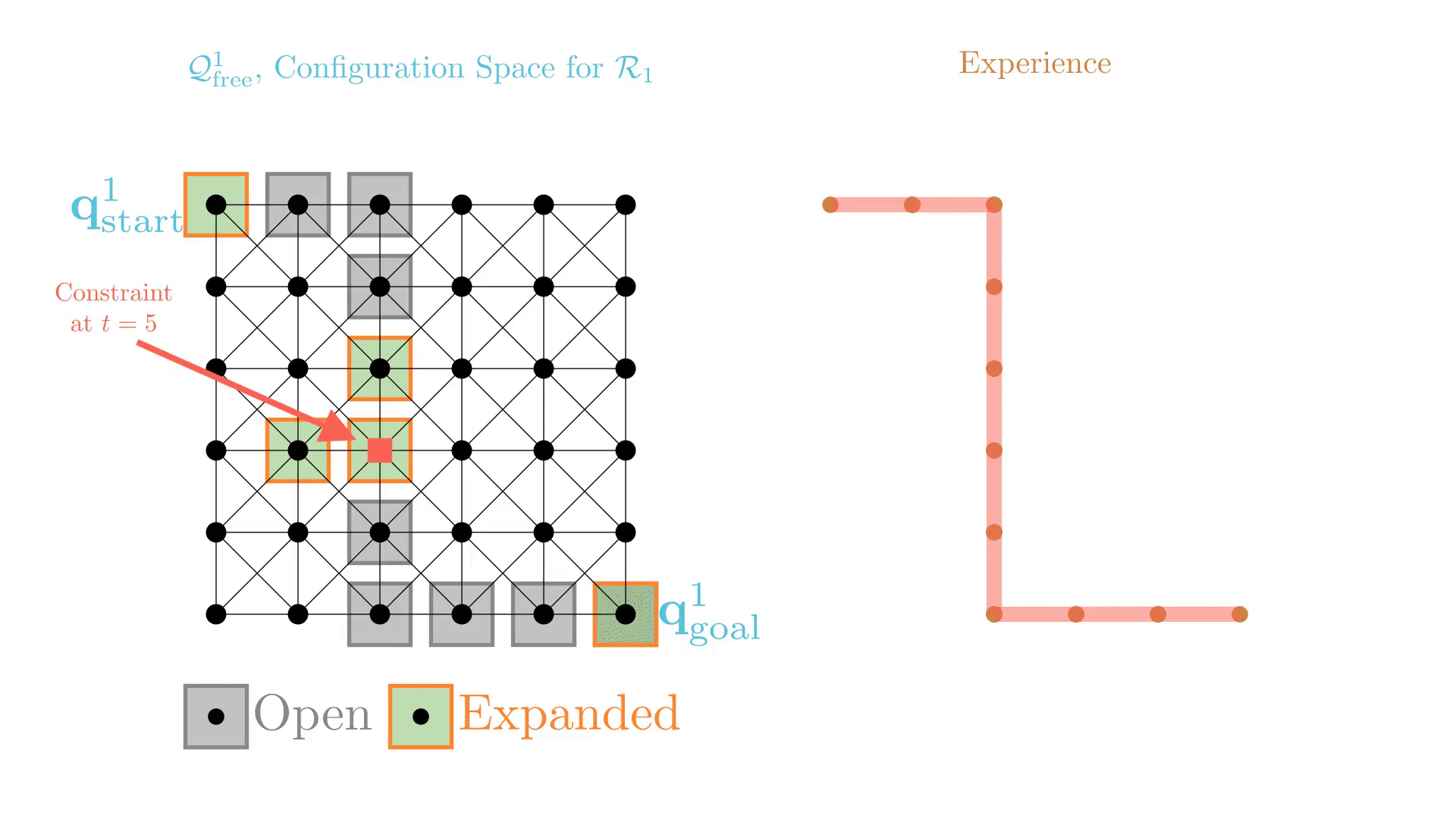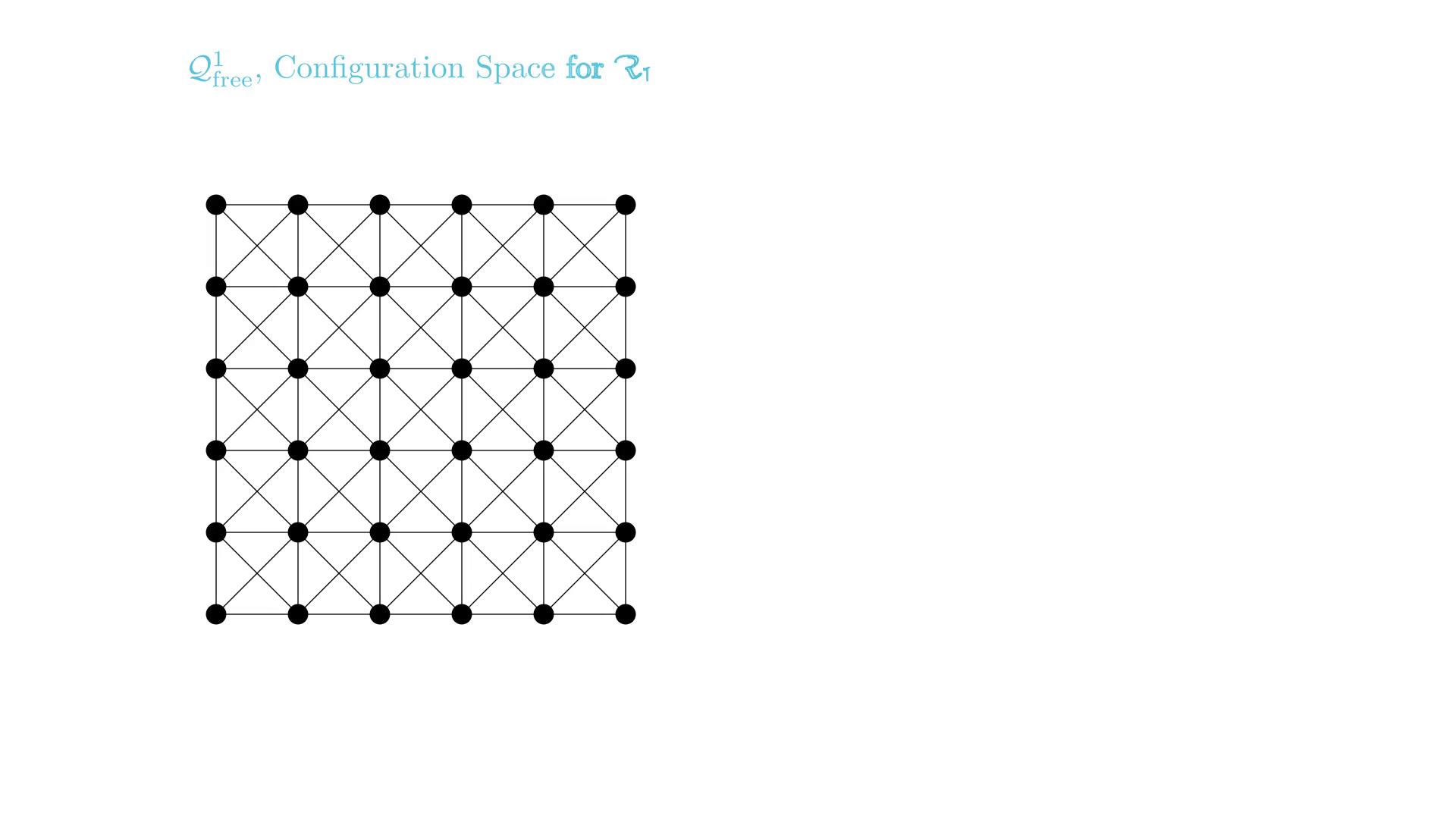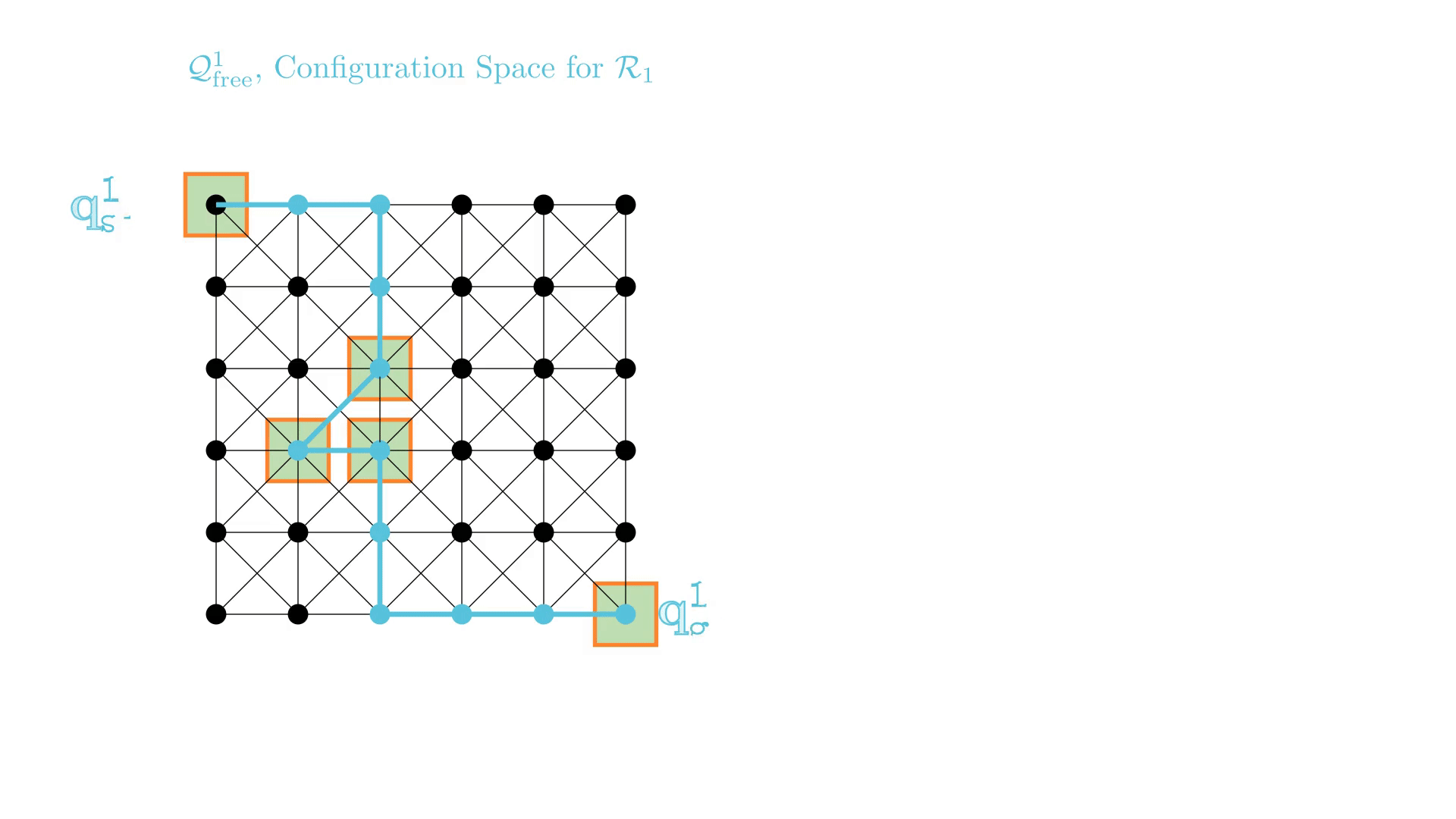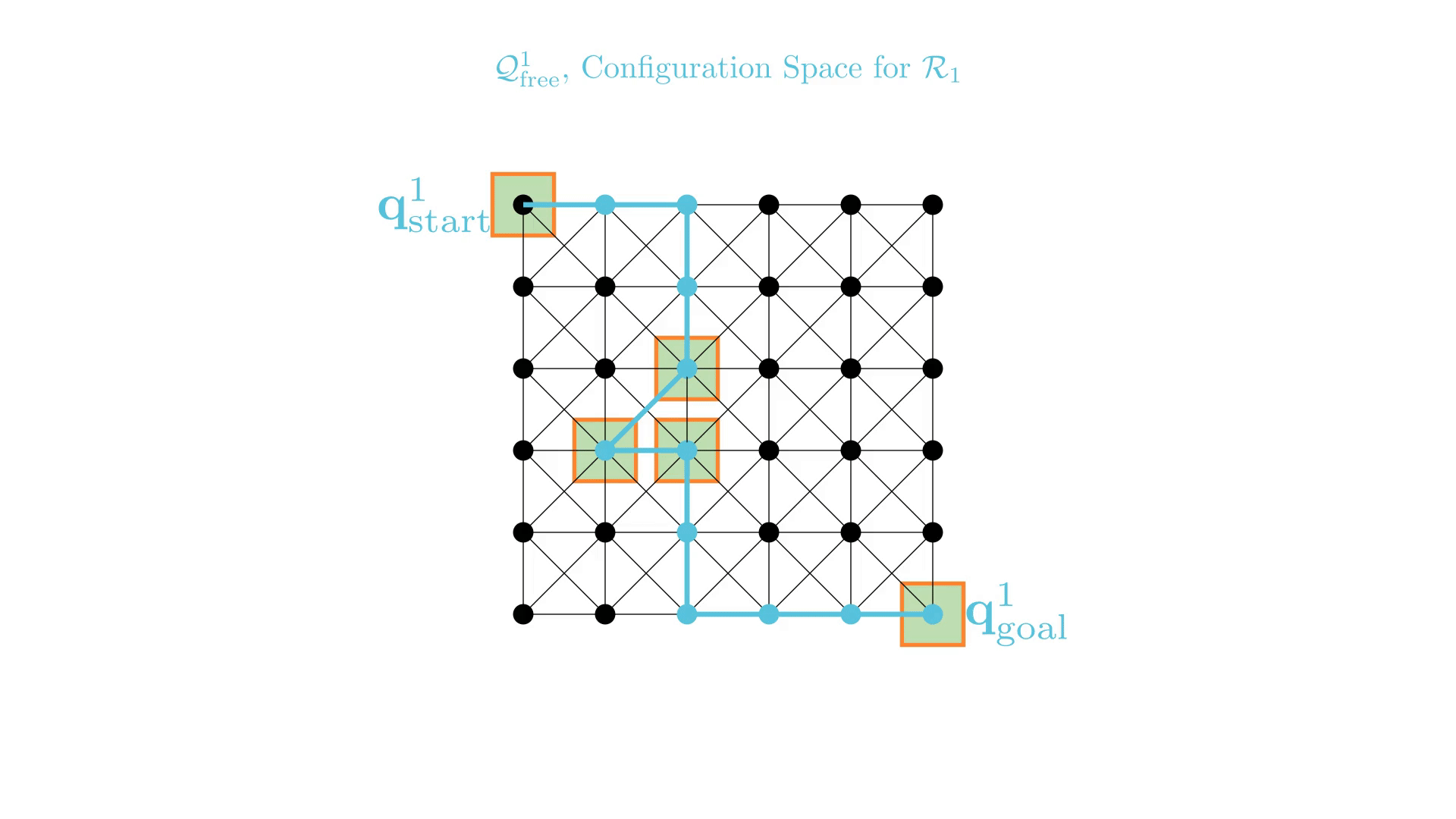
By reusing experience, the new search effort (expanded states) is smaller.
Reusing computation helps! And retains bounded sub-optimality and completeness guarantees.
Experience-Accelerated CBS (xECBS)
Reusing search efforts significantly speeds up the search.
4-Robot Bin-Picking
8-Robot Shelf Rearrangement
Experience-Accelerated CBS (xECBS)
Reusing search efforts significantly speeds up the search.


Experience-Accelerated CBS (xECBS)
xECBS has failure modes.
Stronger Constraints in CBS
xECBS imposes constraints that only prohibit one configuration at a single time
(or transition), and may need many replanning calls before a collision is resolved.
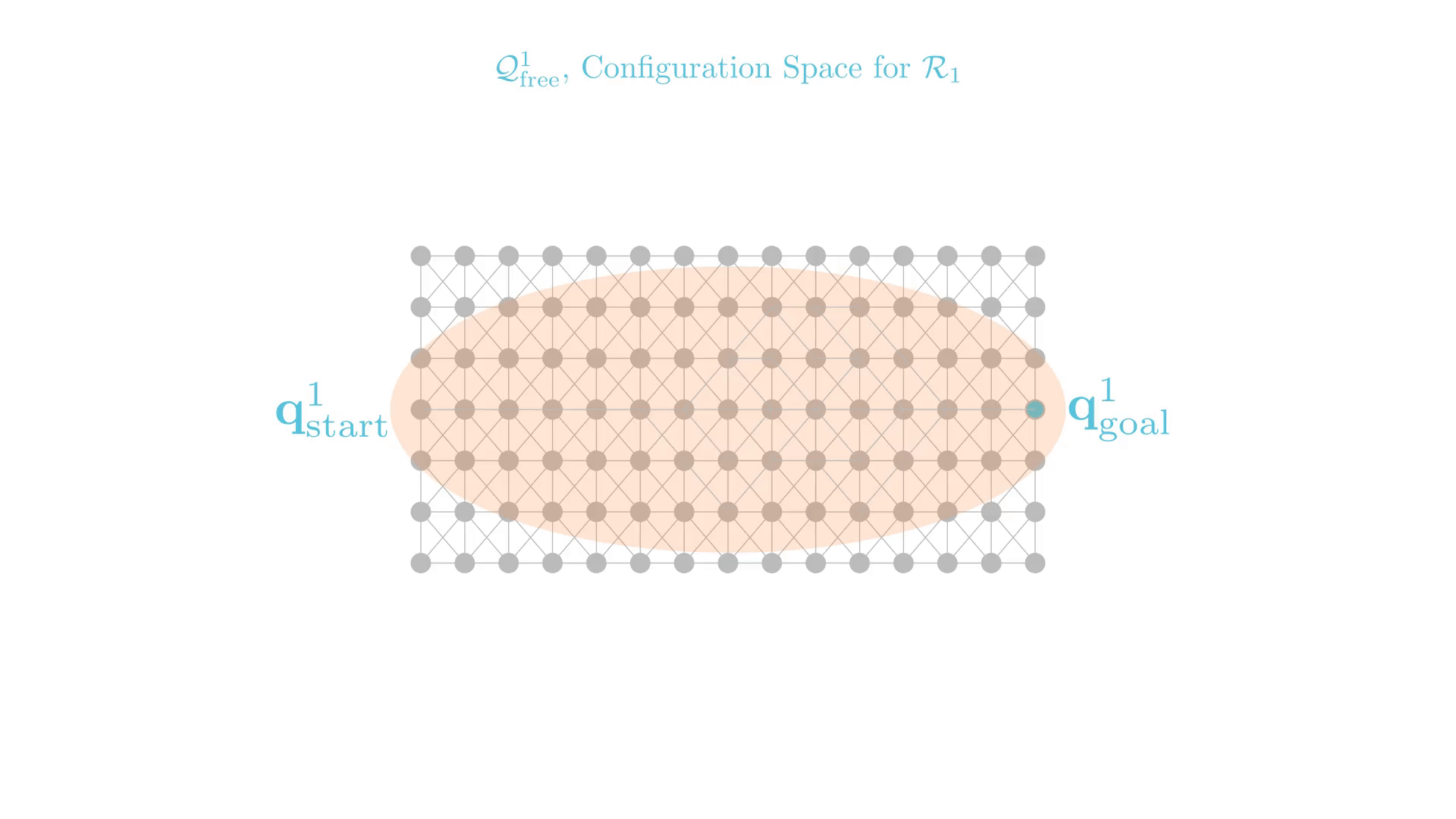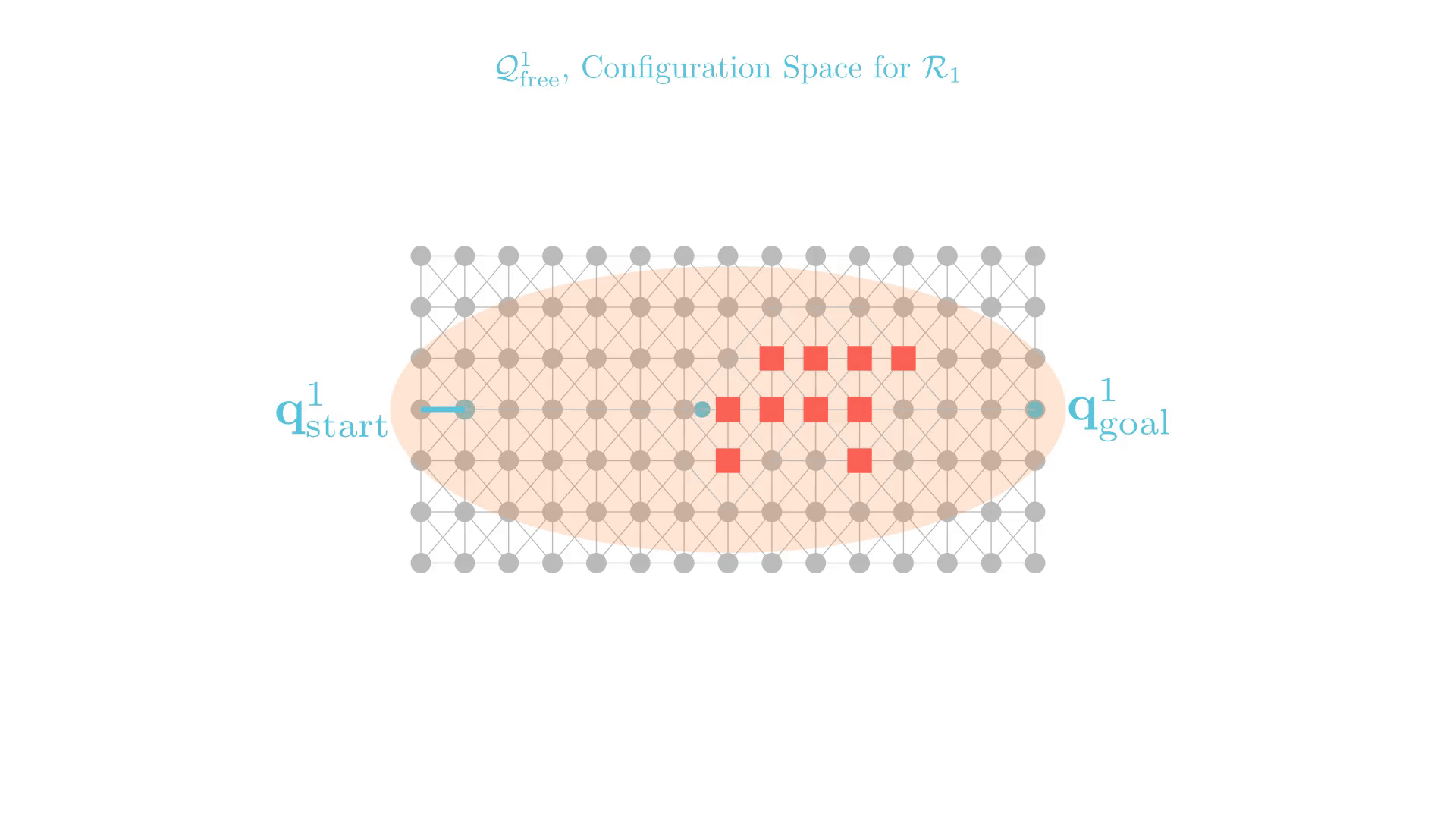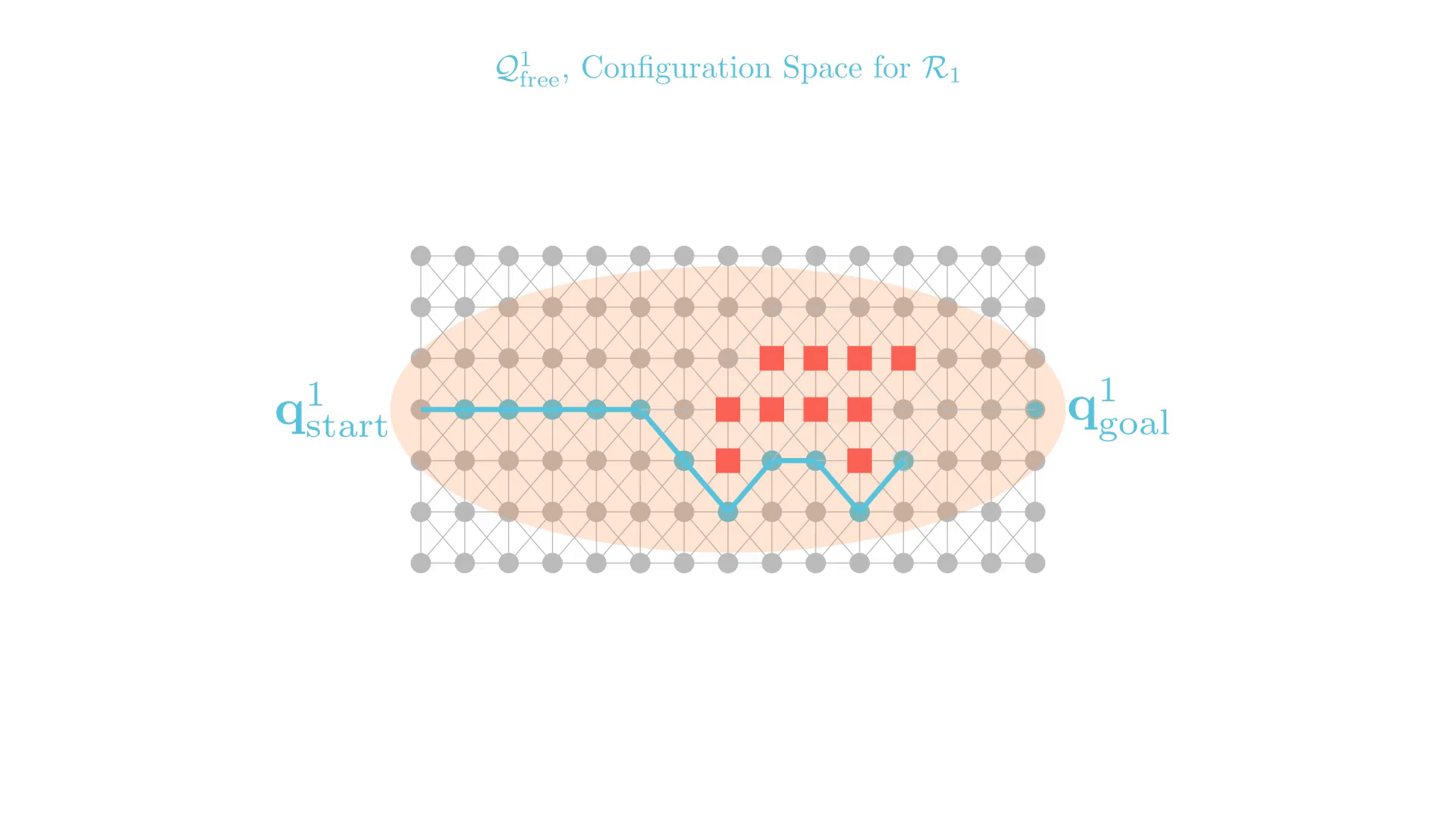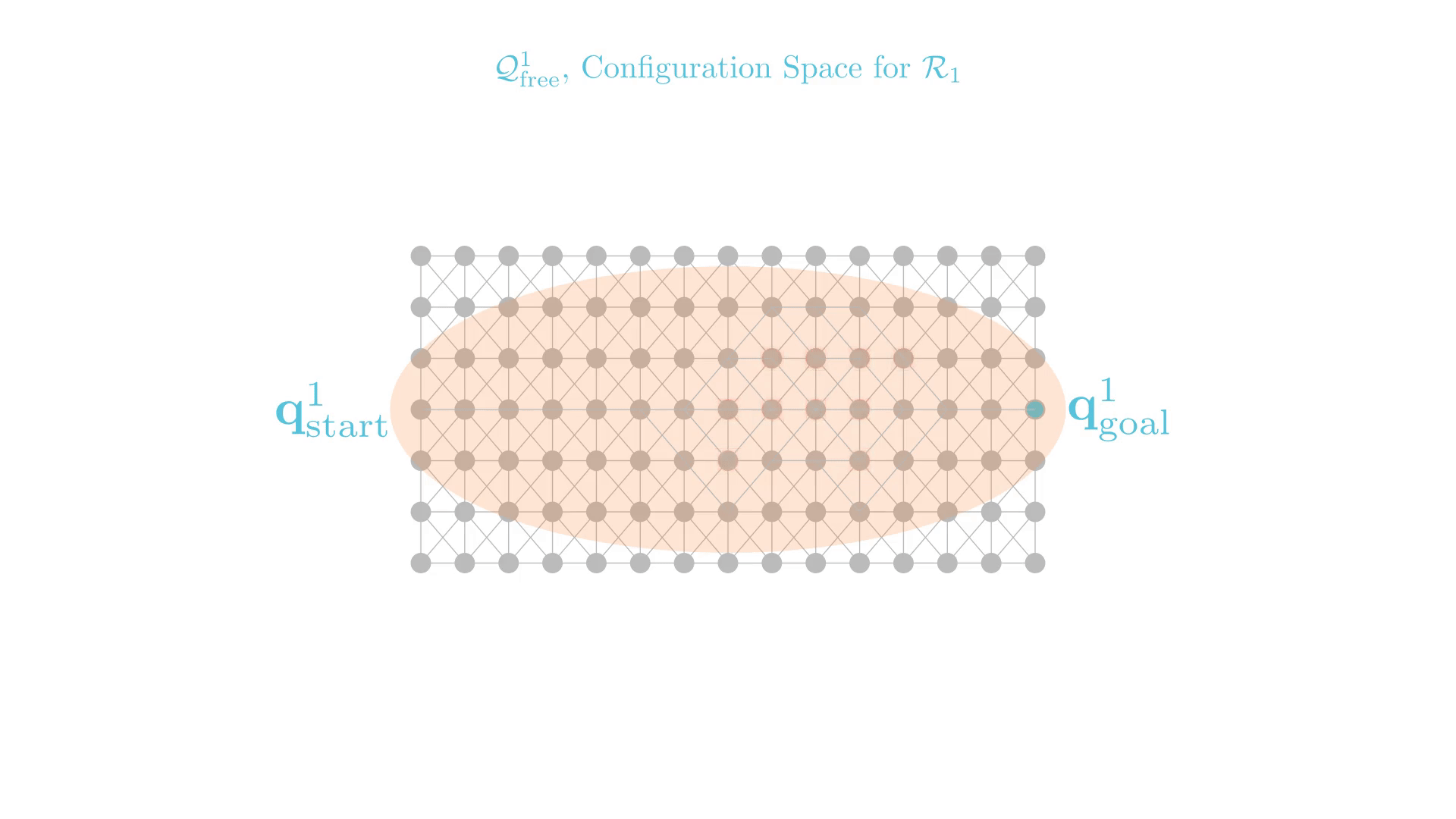
Can we use "stronger"
constraints in CBS?
Stronger Constraints in CBS
Can we use "stronger" constraints in CBS?
Stronger Constraints in CBS
Can we use "stronger" constraints in CBS?
Yes, but we need to be careful.
Stronger Constraints in CBS
Can we use "stronger" constraints in CBS?
Yes, but we need to be careful.
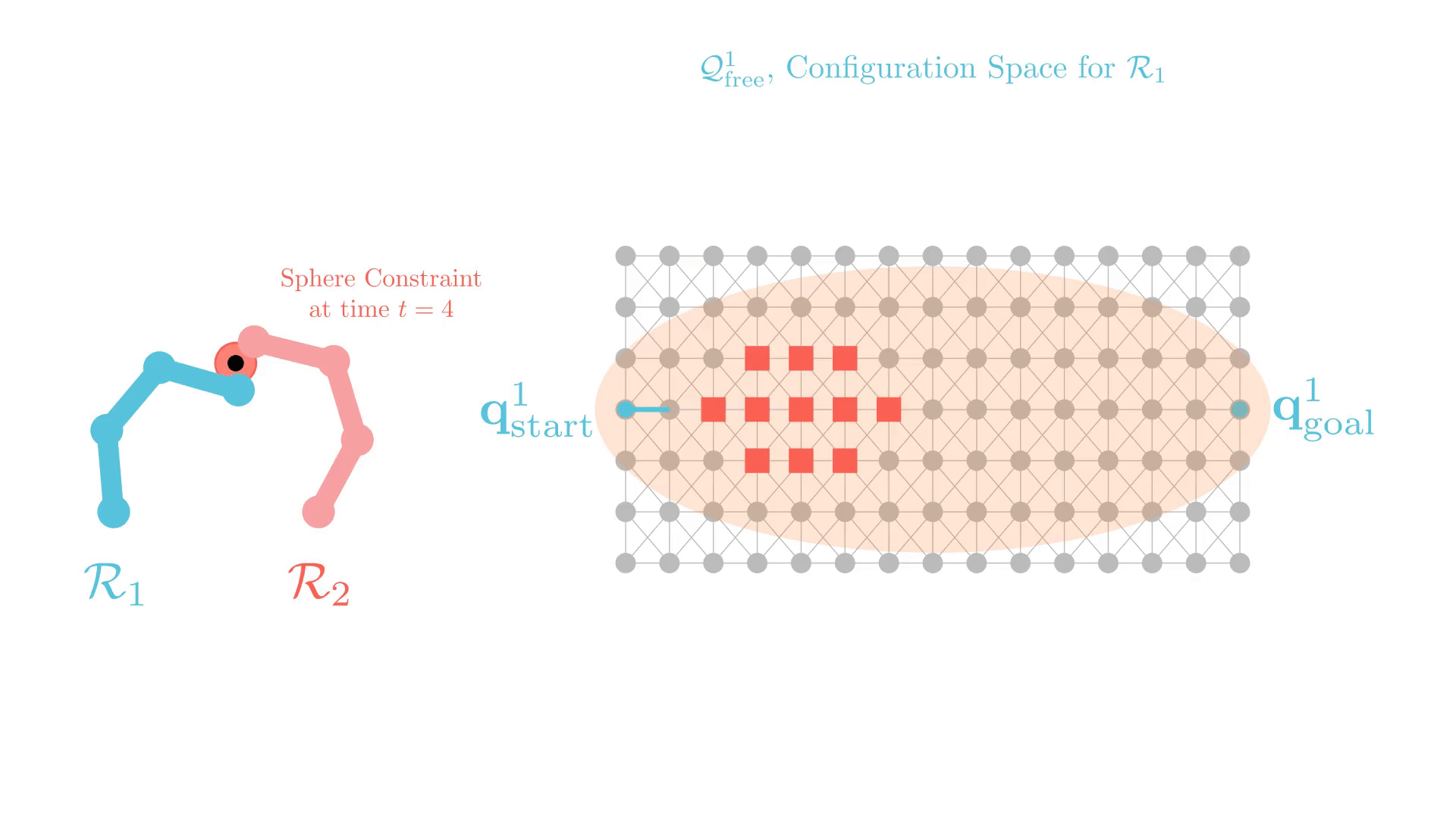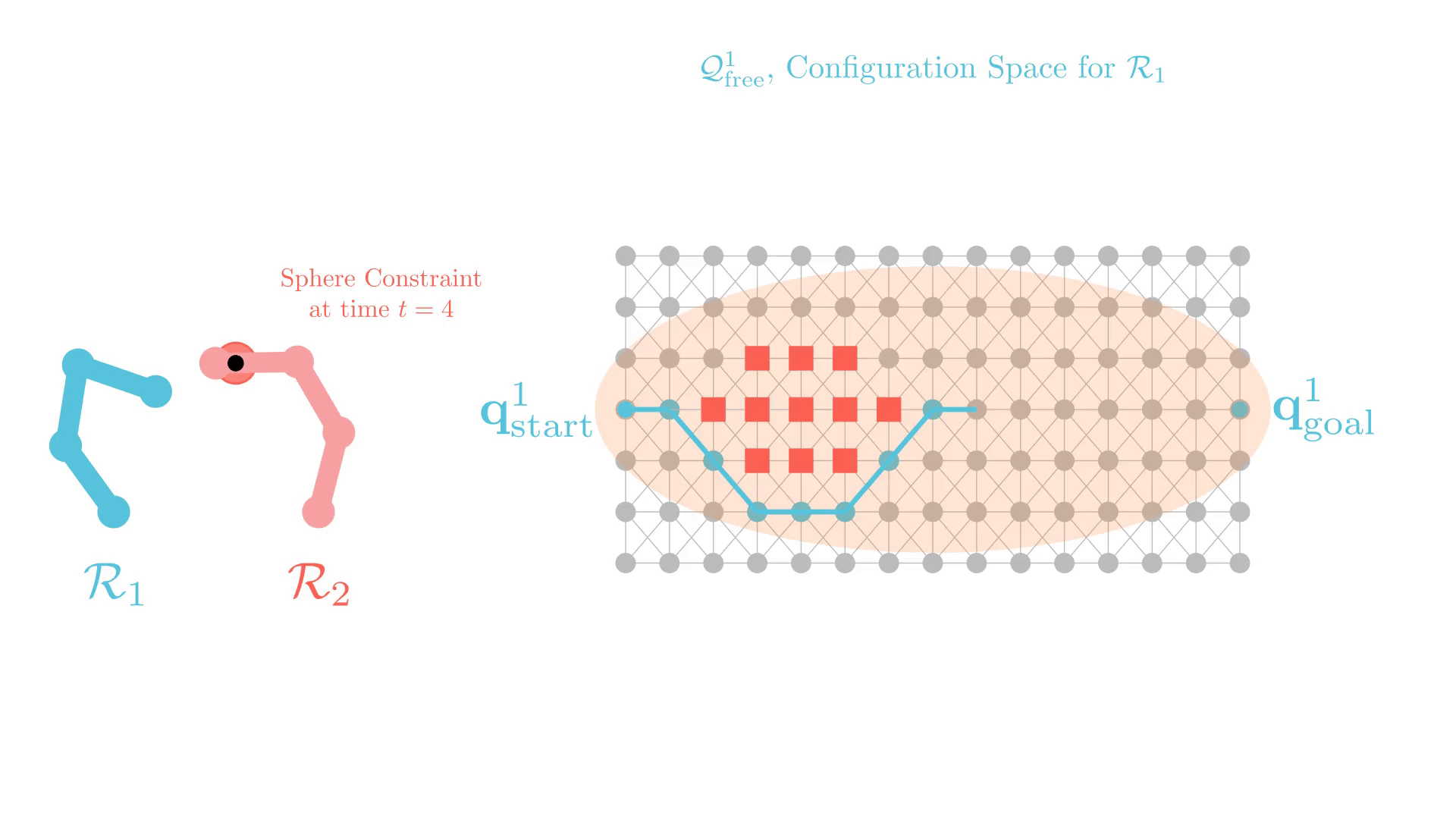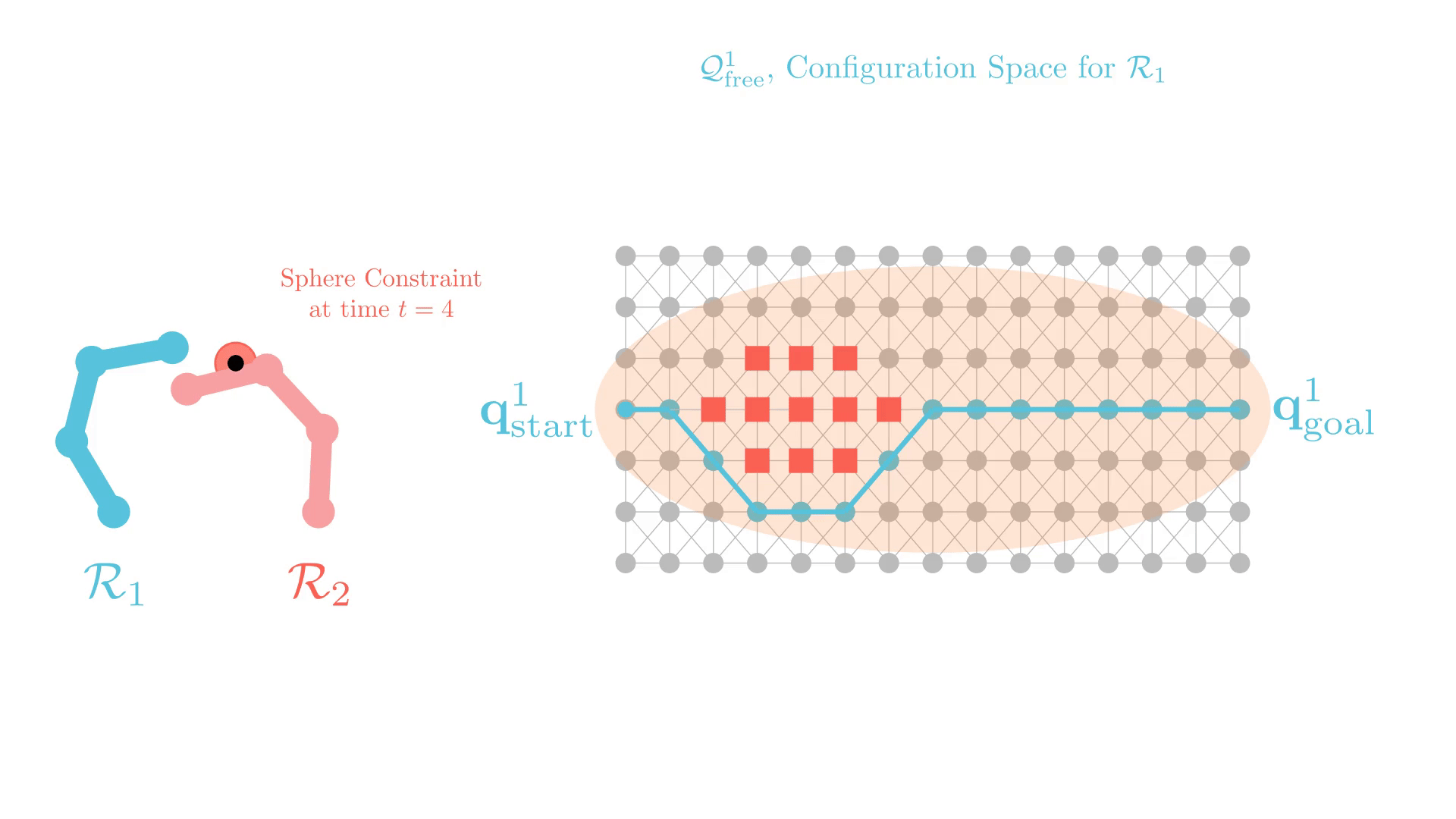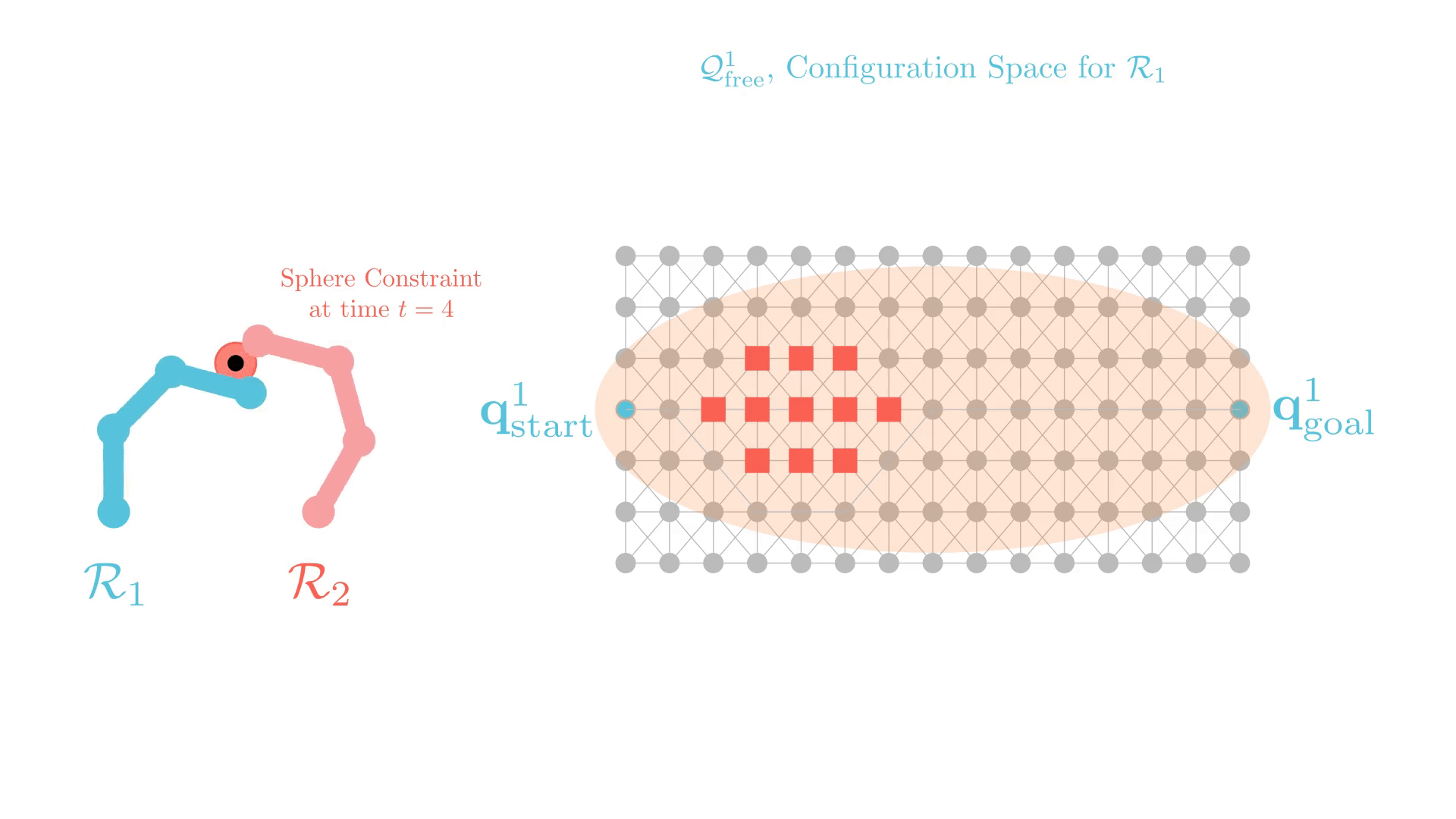
Stronger Constraints in CBS

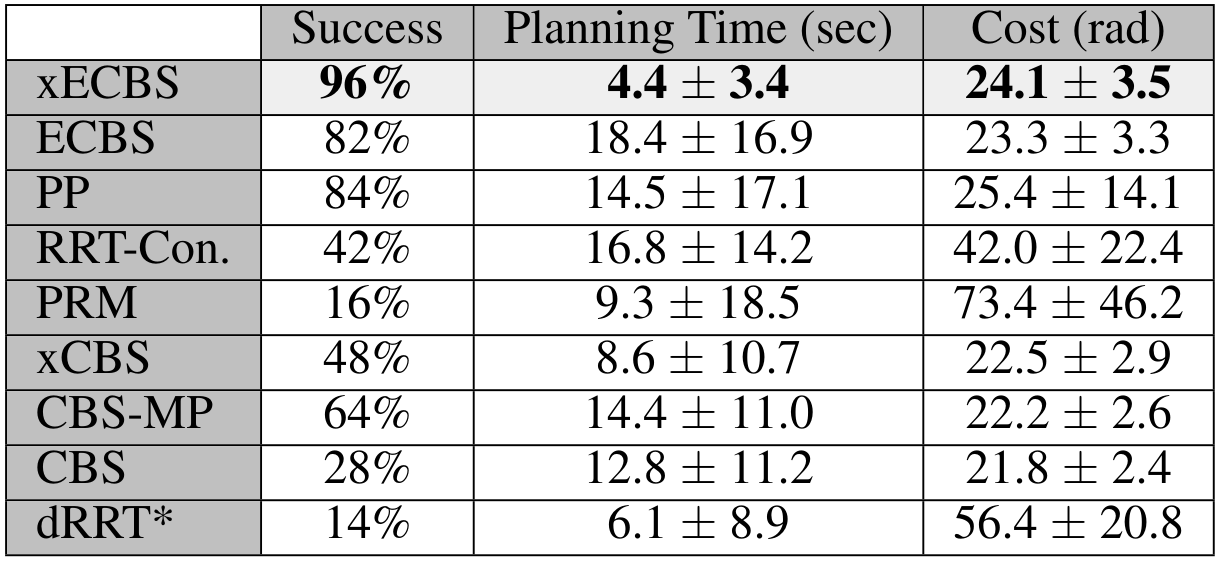
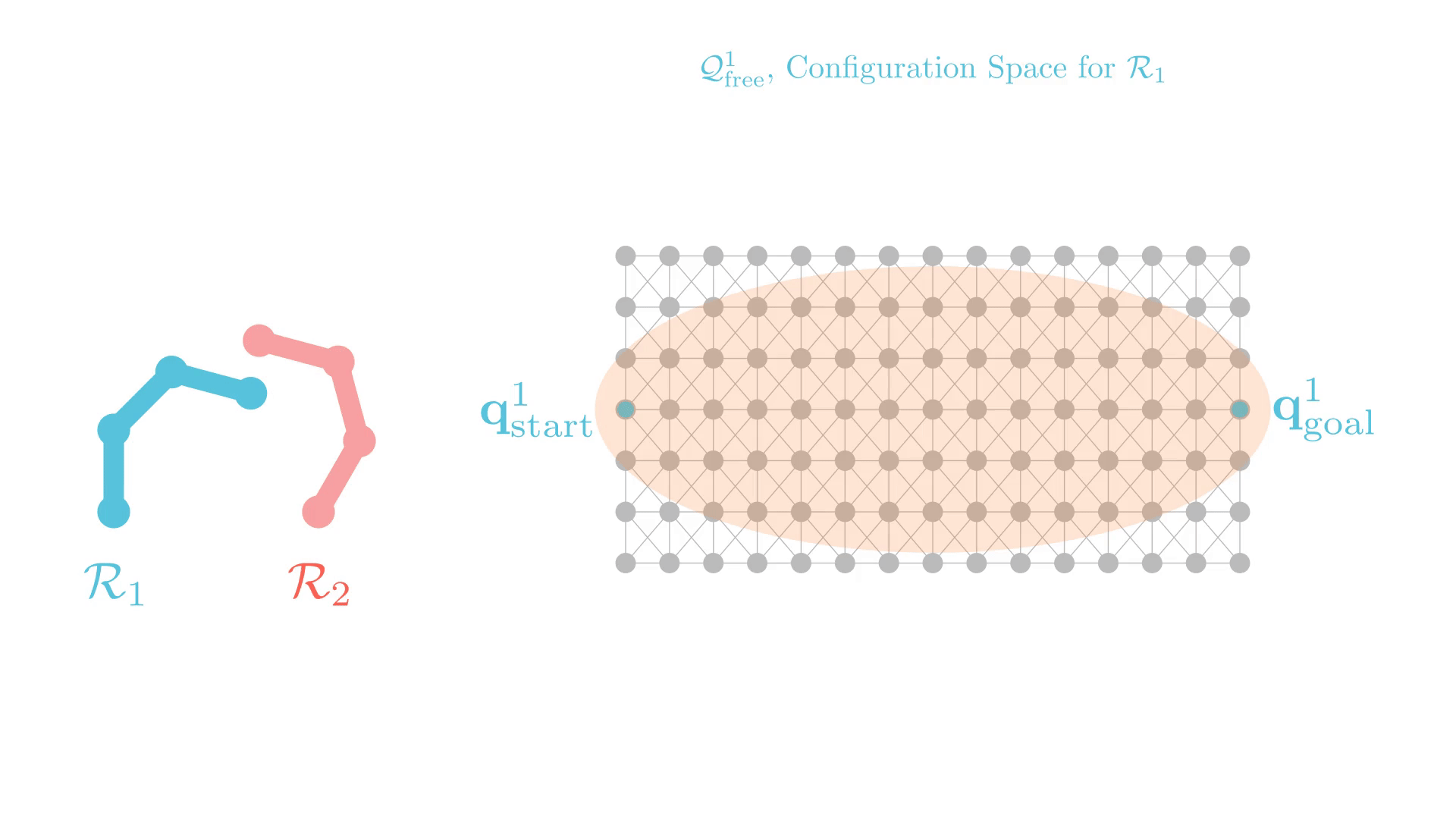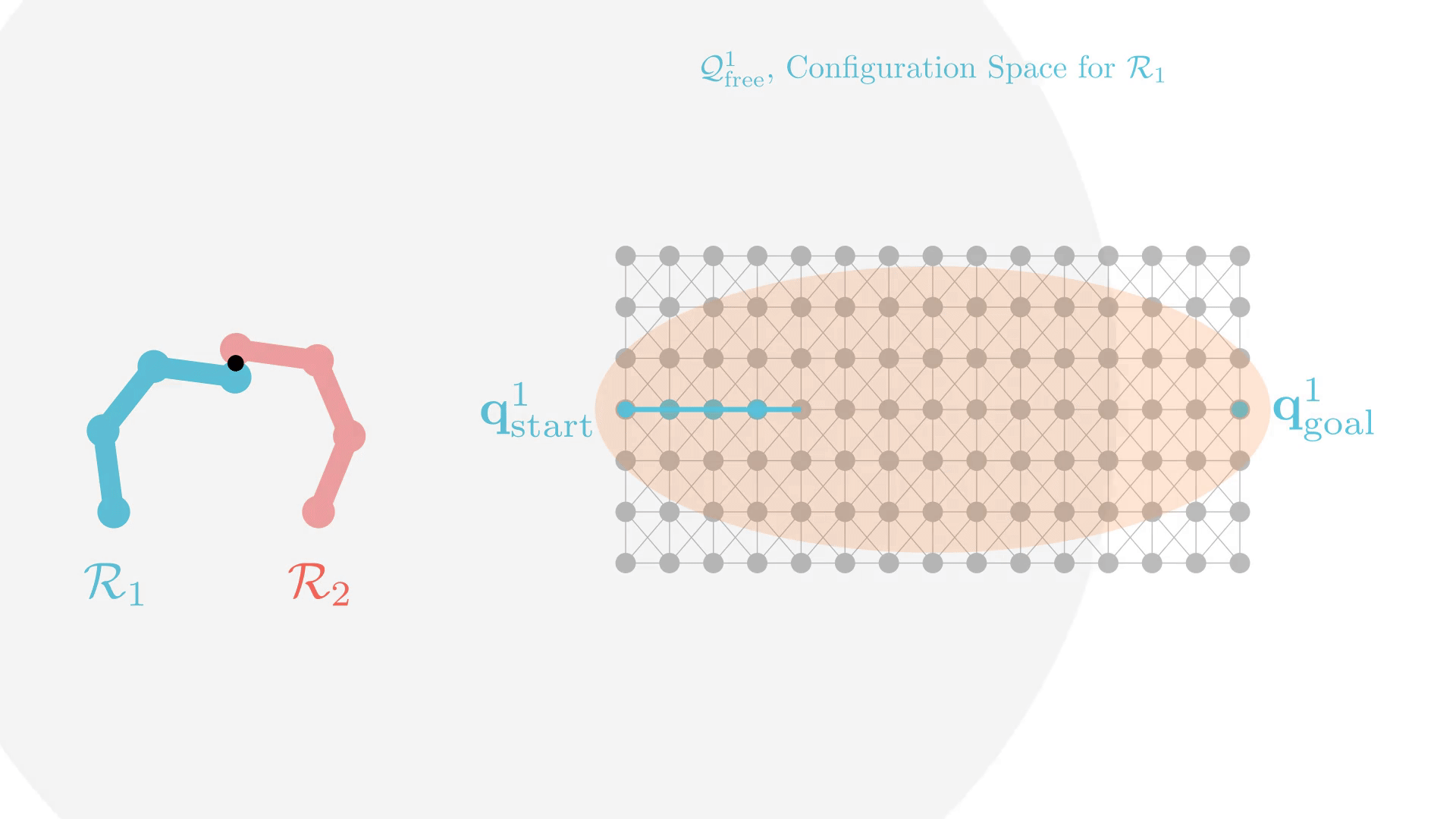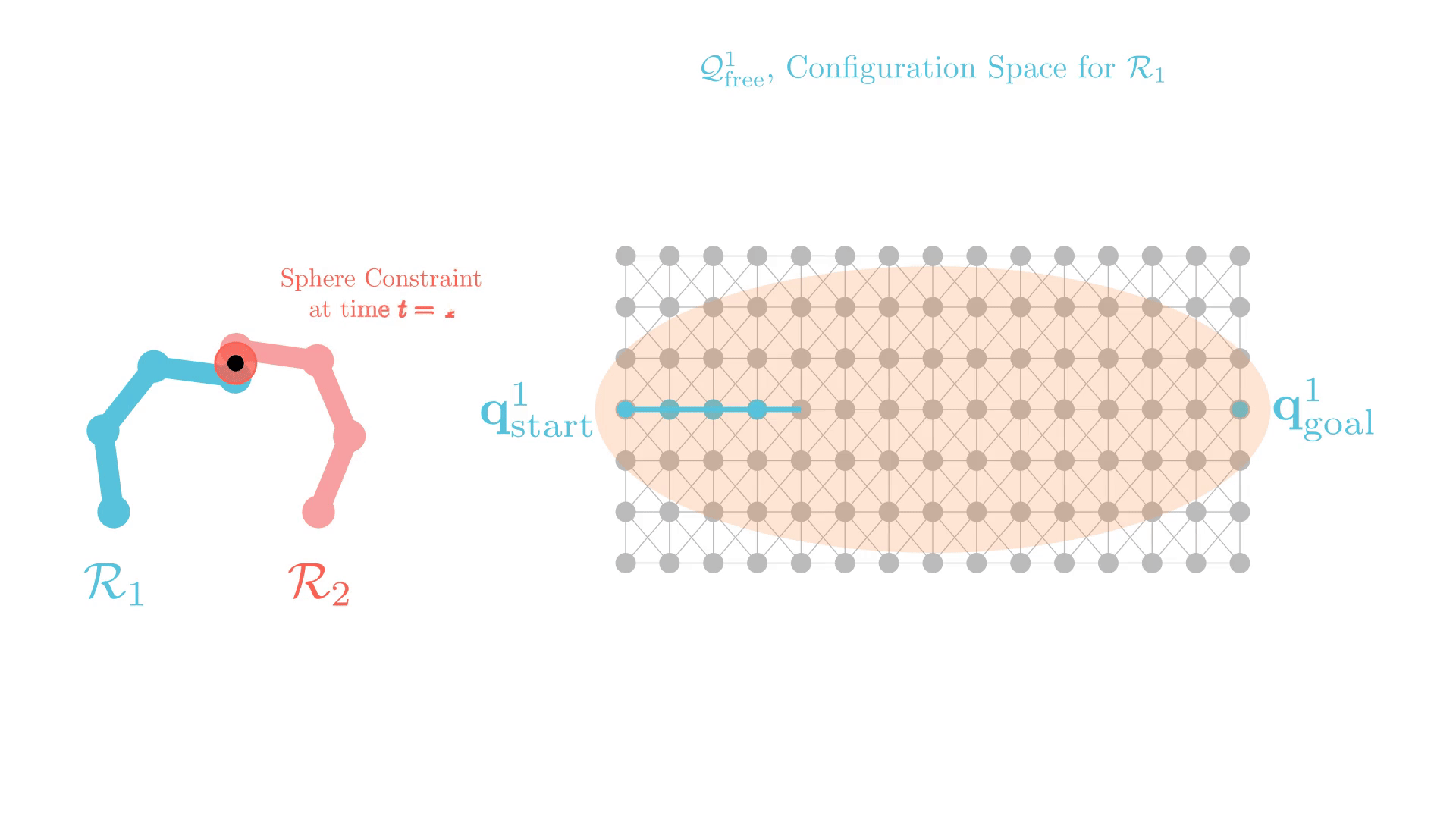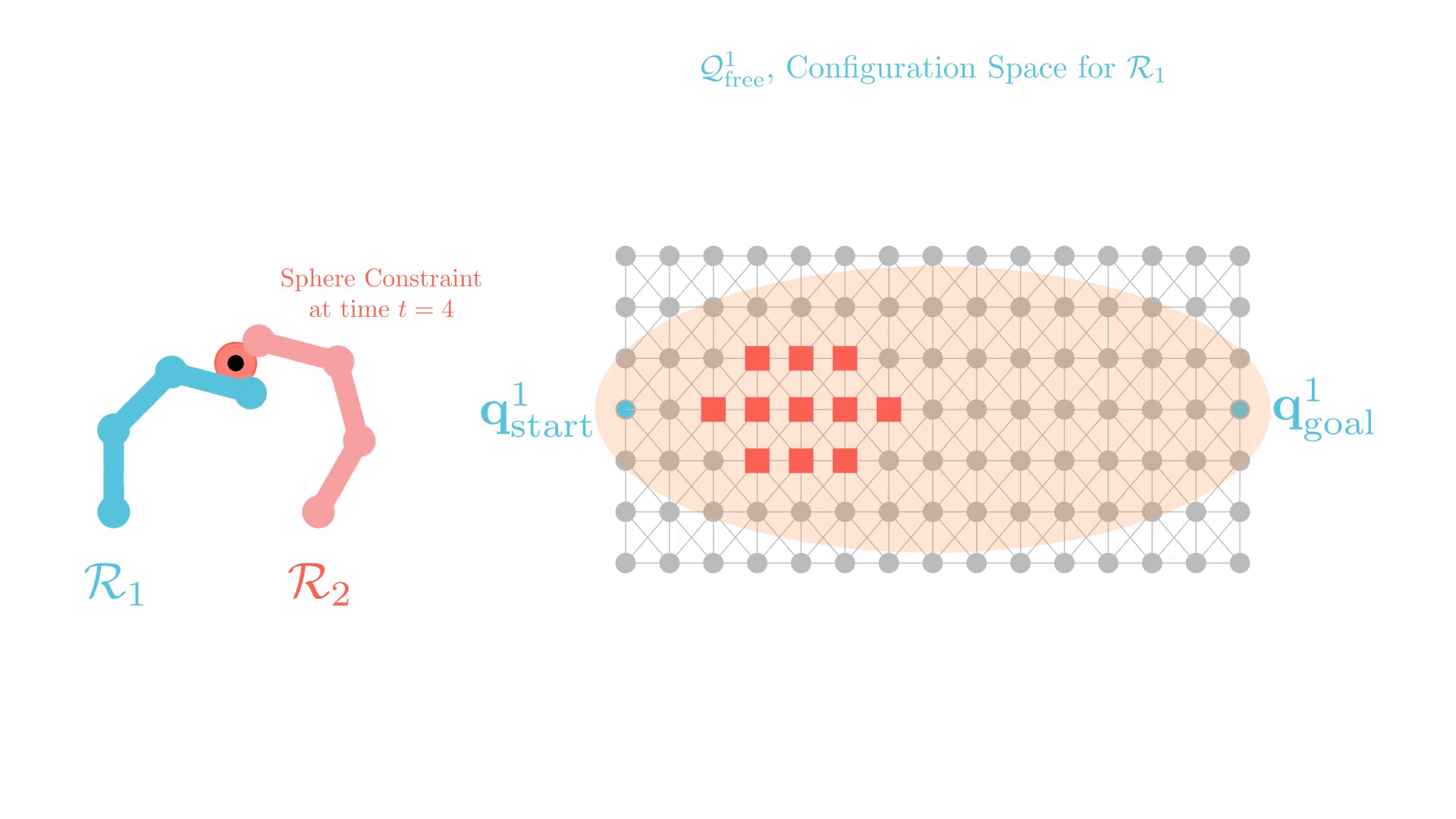
Experience-Accelerated CBS (xECBS)
xECBS with point constraints (spheres with small radii) maintains completeness and solves more problems.

Stronger Constraints in CBS
But some constraints can render problems unsolvable.
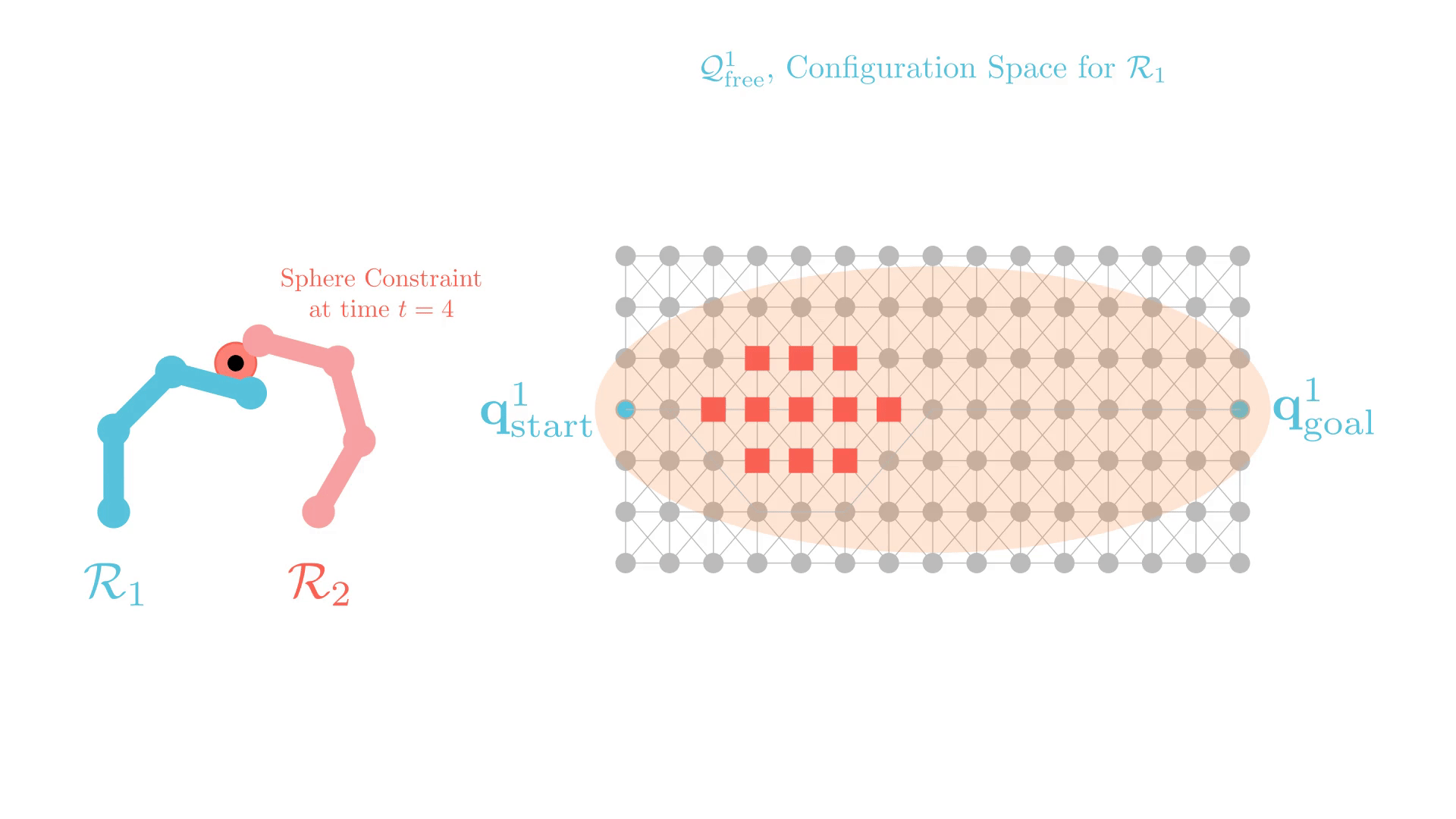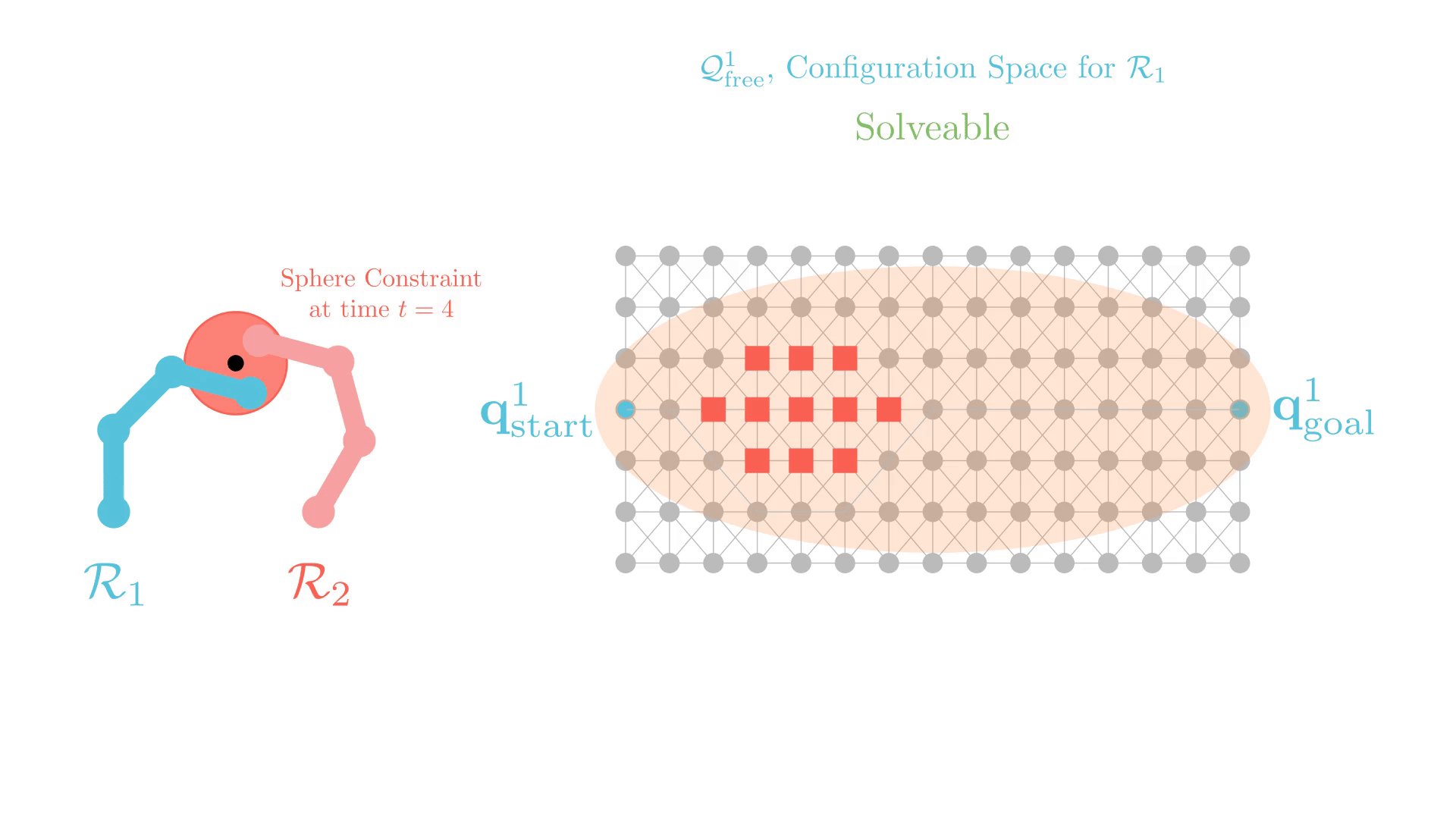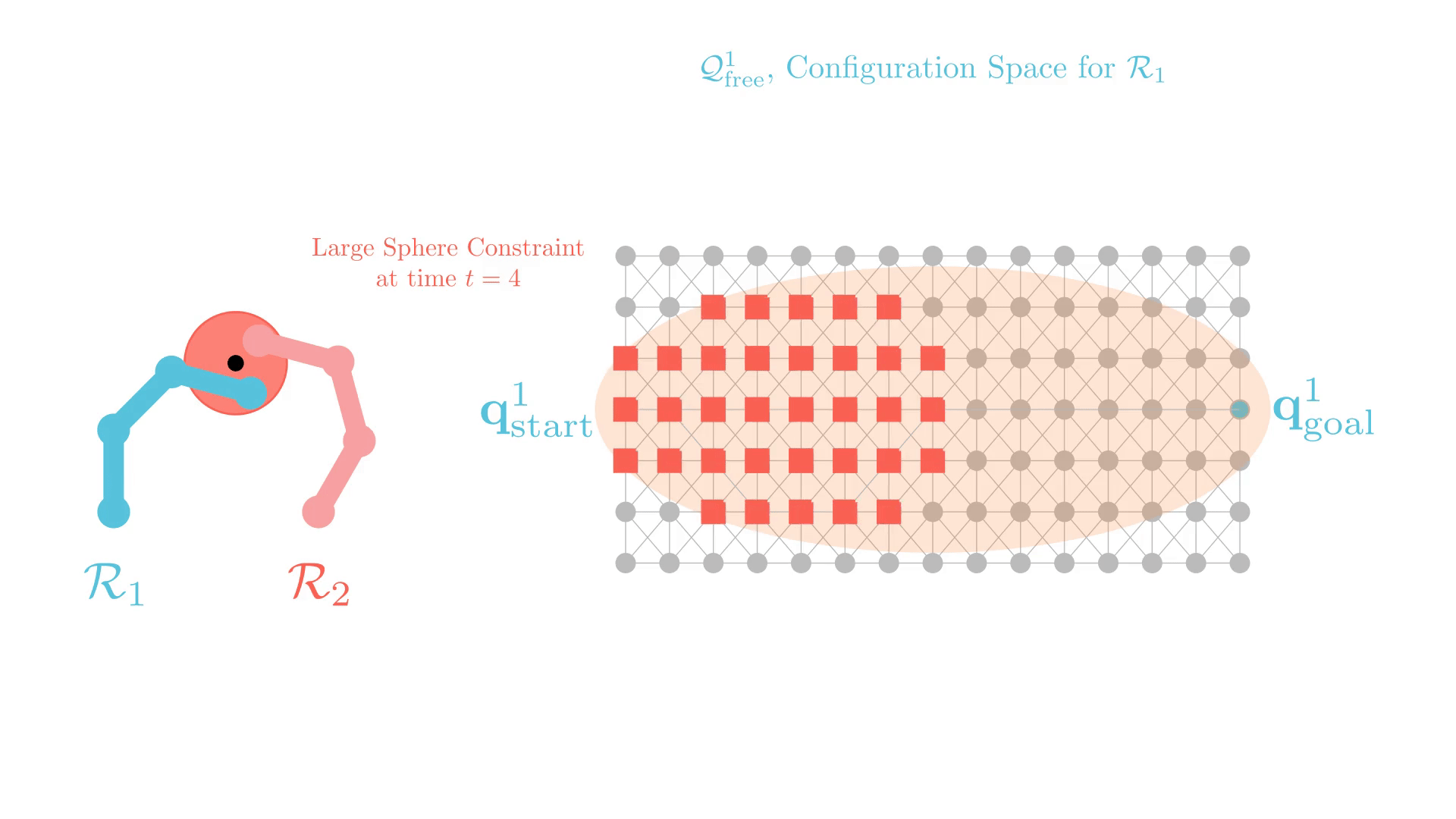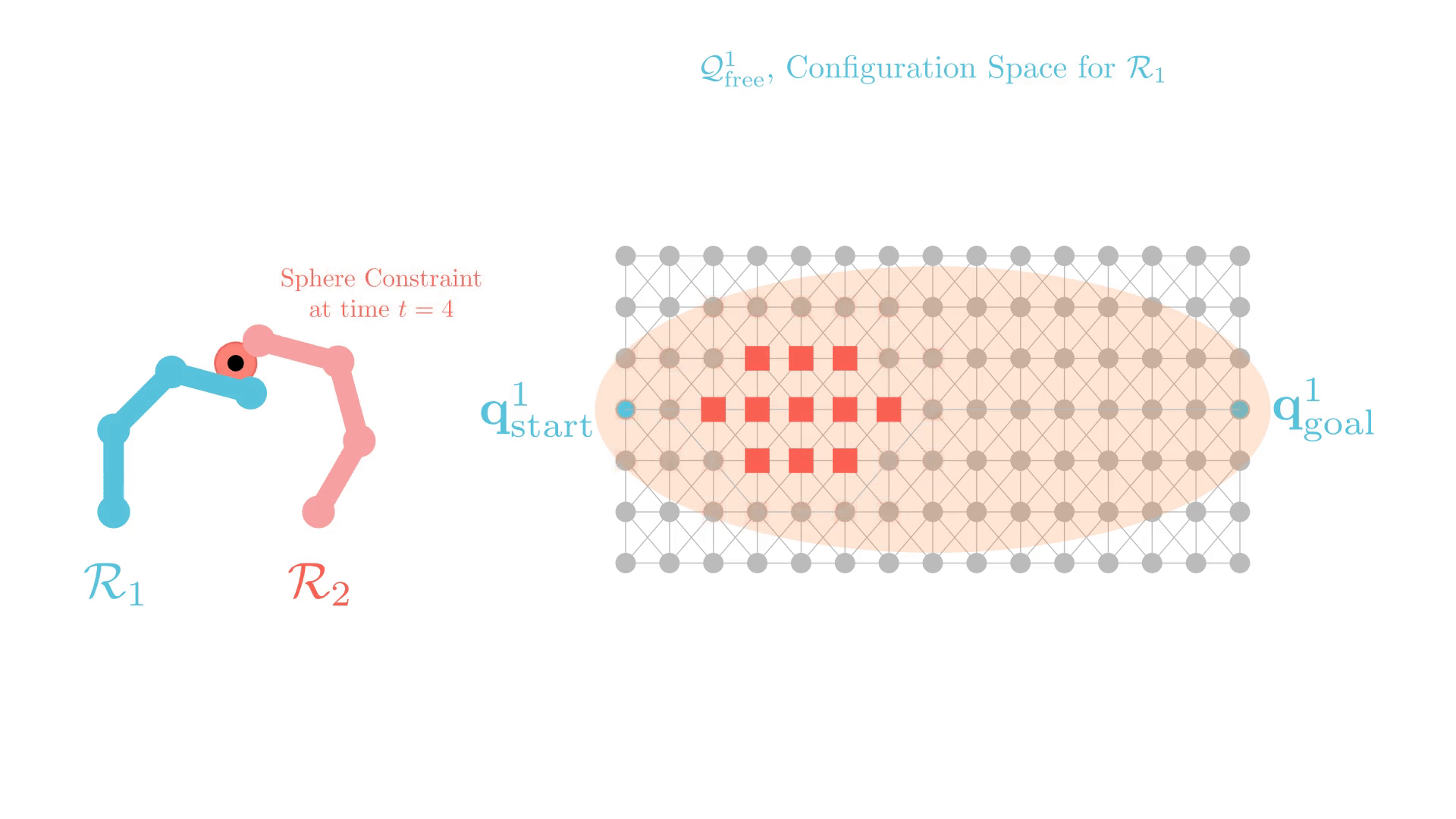
We develop Generalized-ECBS [SoCS-24], which allows for using any constraint in CBS without losing completeness guarantees.
Experience-Accelerated CBS (xECBS)
Check it out in SRMP! https://srmp.readthedocs.io/
Mishani, I.*, Shaoul, Y.*, Natarajan, R.*, Li, J. and Likhachev, M., 2025. SRMP: Search-Based Robot Motion Planning Library. arXiv 2025.

Takeaways
-
Conflict-Based Search is a powerful framework for negotiating space occupancy
-
Applying CBS to arms produces algorithms that are scalable, efficient, complete, and bound sub-optimality
- Two ideas contribute:
- Experience reuse
- "Stronger" constraints
Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation
Thesis Roadmap
Plan what we can, and learn what we must.
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation
Thesis Roadmap
Plan what we can, and learn what we must.
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
Search-based algorithms are effective for multi-arm motion planning
[ICAPS 24, SoCS 24]
Interleaving Planning and Learning on the Plane
Based on
- "Multi-robot motion planning with diffusion models,"
Shaoul*, Mishani*, Vats*, Li, and Likhachev, ICLR 2025 - "Collaborative Multi-Robot Non-Prehensile Manipulation via Flow-Matching Co-Generation,"
Shaoul, Chen*, Mohamed*, Pecora, Likhachev, and Li, In Review 2026
Coordination and Collaboration
In this part, we'll consider two types of problems:
Coordination
Robots have individual tasks and negotiate space
Collaboration
Robots have a shared objective and must work together
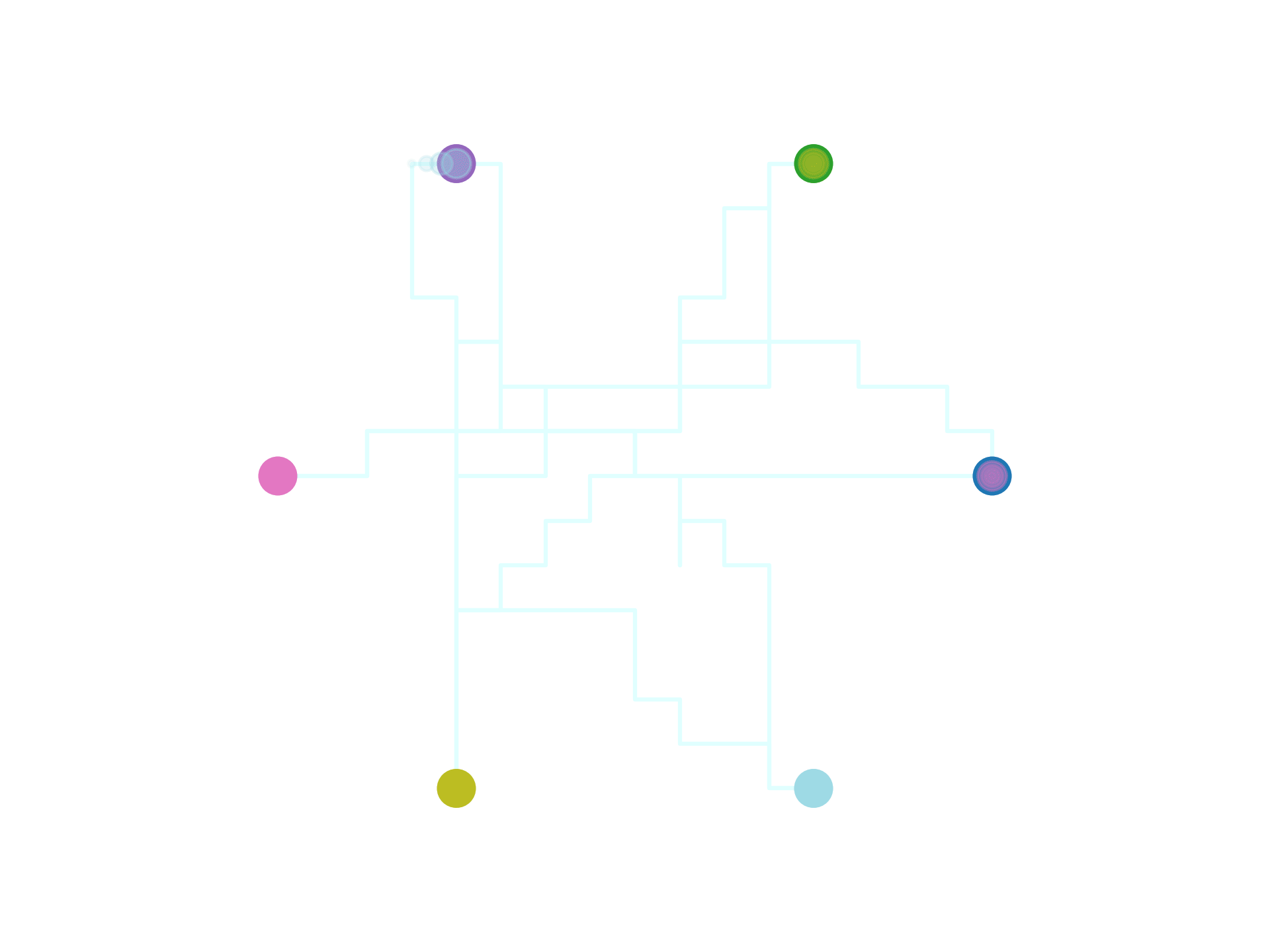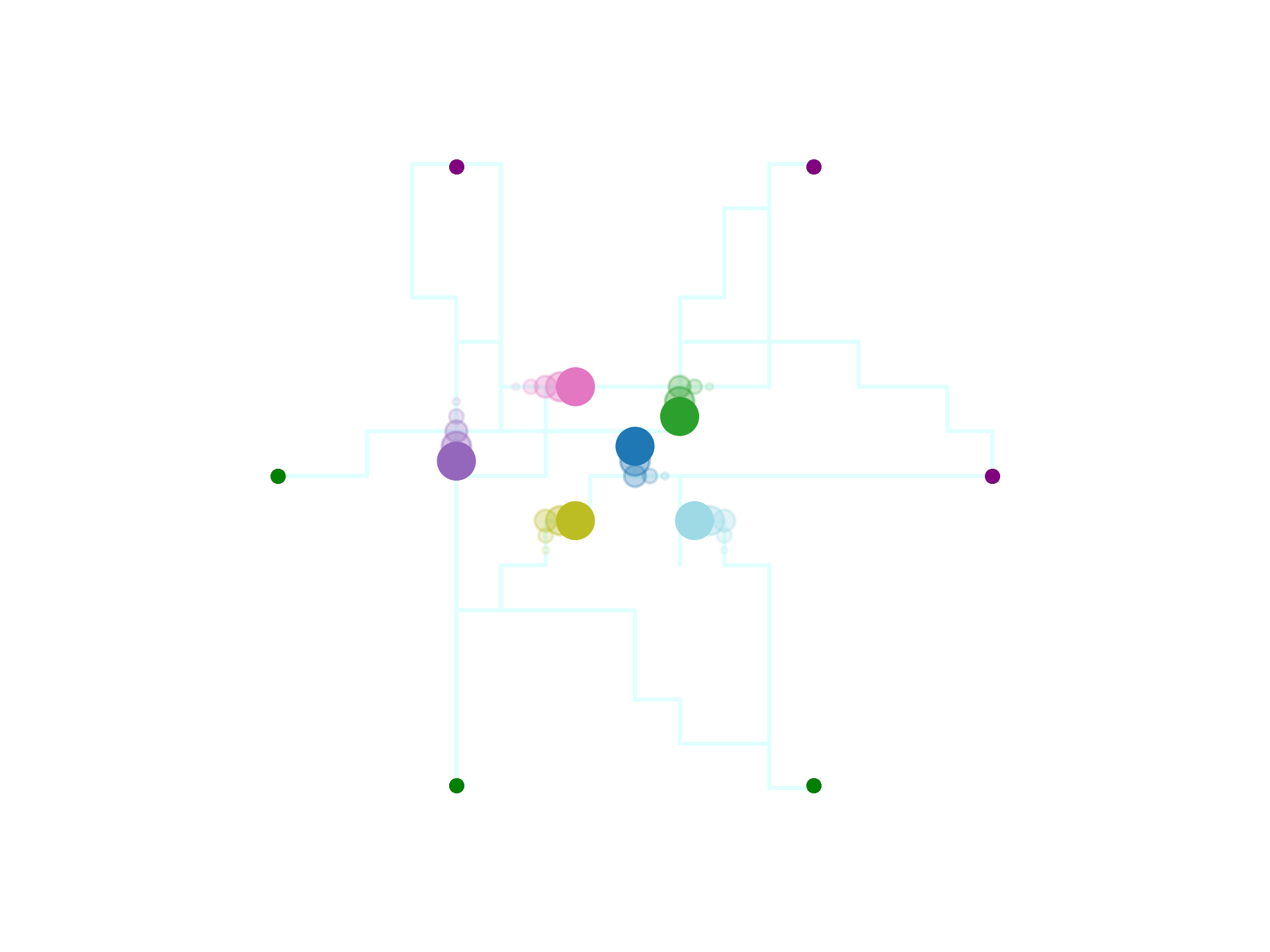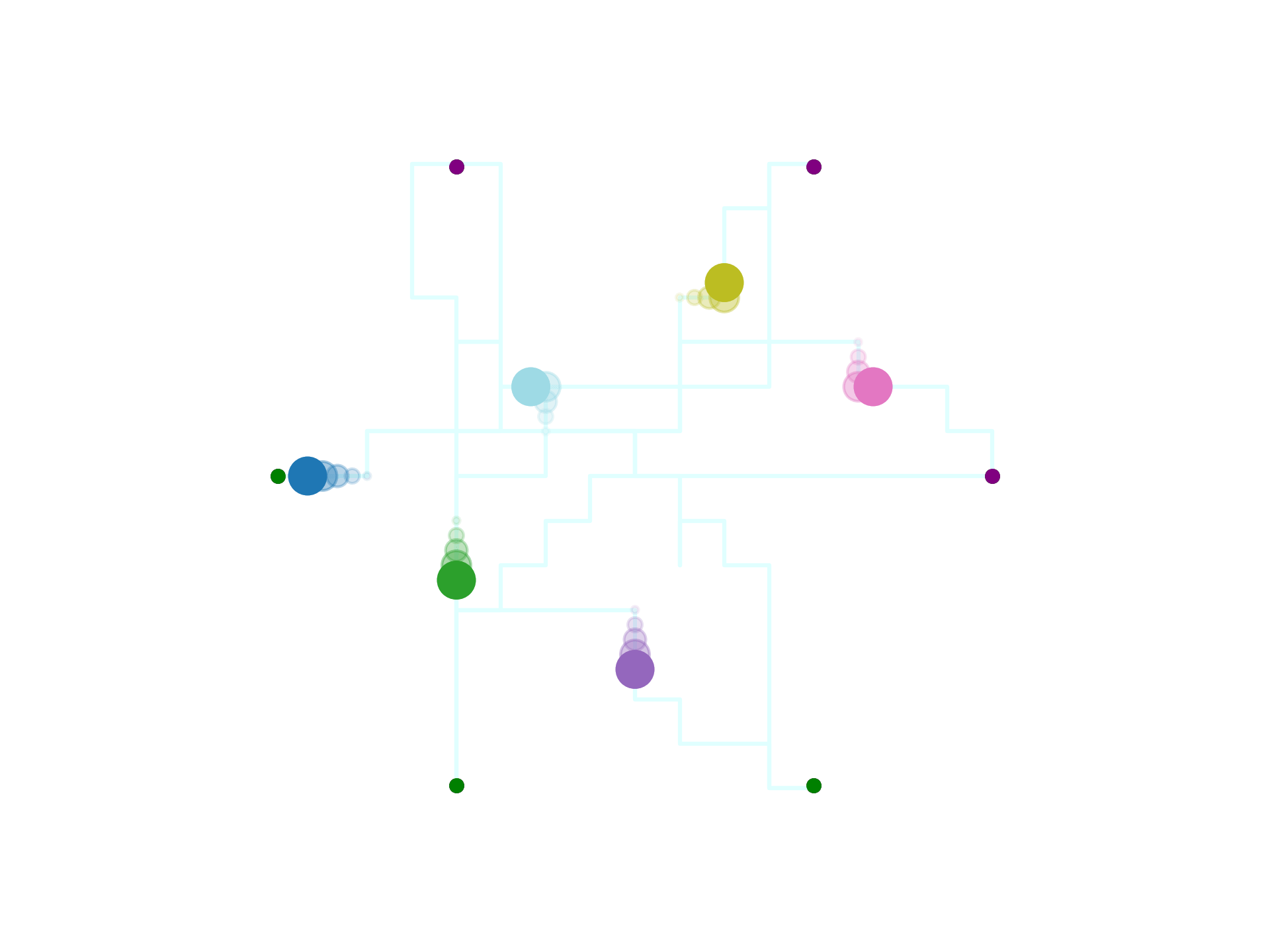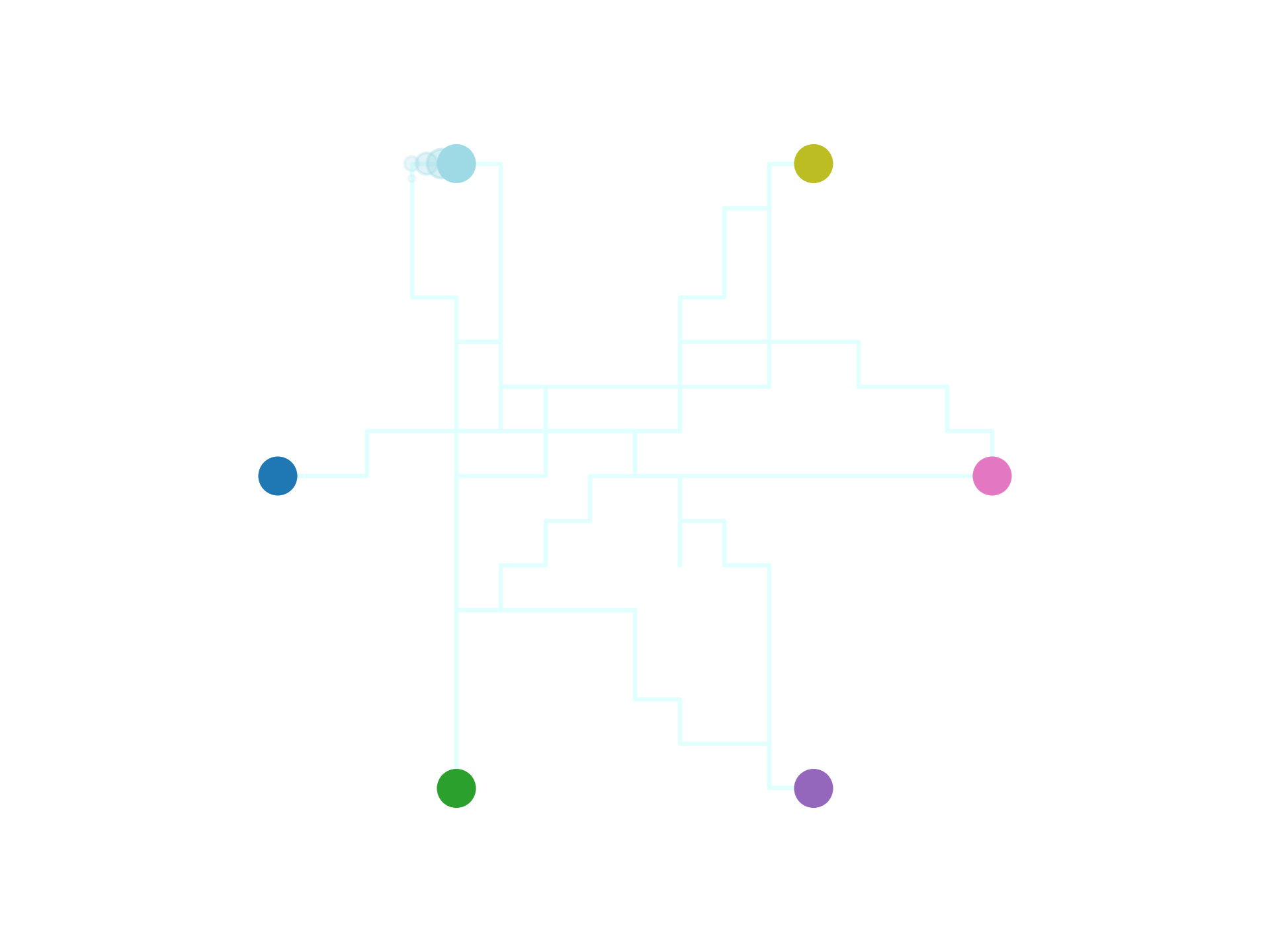
Multi-Robot Coordination
Motion Pattern
What we want to do
- Plan coordinated motions for multiple robots
- With robots following data-driven motion patterns
Formally, given
- a set of robots \(\{\mathcal{R}_i\}_{i=1}^n\)
sharing a workspace (\(\in\mathbb{R}^2\) or \(\in\mathbb{R}^3\) ) - a motion dataset
Compute
- A set of collision-free trajectories \(\{\boldsymbol{\tau}^i\}_{i=1}^n\)
that adhere to the motion patterns
exhibited by the dataset
Multi-Robot Coordination
Options to Tackle the Problem
Available
Data
Expressive Modeling
Scale with Agents
Scale to large environments
Learn directly [Carvalho et al. 2023]
Multi-Robot Coordination
Options to Tackle the Problem
Available
Data
Expressive Modeling
Scale with Agents
Scale to large environments
Learn directly [Carvalho et al. 2023]
Learn cost maps for
classical planning
Multi-Robot Coordination
Options to Tackle the Problem
What we want: Rely on local, single-robot data,
and model flexibly
Learn directly [Carvalho et al. 2023]
Available
Data
Expressive Modeling
Scale with Agents
Scale to large environments
Learn cost maps for
classical planning
Single-Robot Generative Modeling
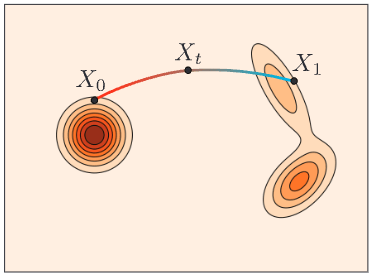
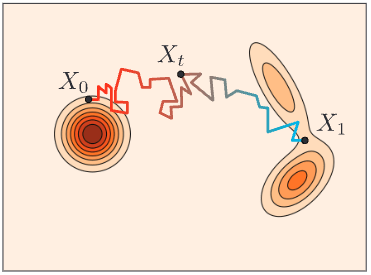
Motion planning diffusion models [Carvalho 2023, Janner 2022] have shown impressive performance for generating robot trajectories under implicit objectives.
Diffusion models generate trajectories from noisy trajectories.

Carvalho et al. 2023



Dataset
Generated
Single-Robot Generative Modeling
\underbrace{^K\boldsymbol{\tau}^i}_{\text{Pure noise}} \quad
\rightarrow ^{K-1}\boldsymbol{\tau}^i \quad
\rightarrow ^{K-2}\boldsymbol{\tau}^i \quad
\rightarrow \cdots
\rightarrow ^{1}\boldsymbol{\tau}^i \quad
\rightarrow \underbrace{^{0}\boldsymbol{\tau}^i}_\text{Denoised}

Denoising Process
Beginning from a pure noise trajectory \(^K\boldsymbol{\tau}^i\),
the model de-noises it incrementally for \(K\) denoising steps.
^{k-1}\boldsymbol{\tau}^i \sim \mathcal{N} \left( \mu^i_{k-1} , \beta_{k-1}
\right)
\mu^i_{k-1} \gets \mu^i_\theta(^{k}\boldsymbol{\tau}^i)
Single-Robot Generative Modeling
Motion Planning Diffusion models [Carvalho 2023, Janner 2022] generate trajectories from noisy trajectories.
\underbrace{^K\boldsymbol{\tau}^i}_{\text{Pure noise}} \quad
\rightarrow ^{K-1}\boldsymbol{\tau}^i \quad
\rightarrow ^{K-2}\boldsymbol{\tau}^i \quad
\rightarrow \cdots
\rightarrow ^{1}\boldsymbol{\tau}^i \quad
\rightarrow \underbrace{^{0}\boldsymbol{\tau}^i}_\text{Denoised}
Denoising Process
\mu^i_{k-1} \gets \mu^i_\theta(^{k}\boldsymbol{\tau}^i)
^{k-1}\boldsymbol{\tau}^i \sim \mathcal{N} \left( \mu^i_{k-1} + \underbrace{\eta \beta_{k-1} \nabla_{\boldsymbol{\tau}} \mathcal{J}(\mu^i_{k-1})}_{\text{Guidance}}, \beta_{k-1}
\right)
Single-Robot Generative Modeling
\mu^i_{k-1} \gets \mu^i_\theta(^{k}\boldsymbol{\tau}^i)
Denoising Process
^{k-1}\boldsymbol{\tau}^i \sim \mathcal{N} \left( \mu^i_{k-1} + \underbrace{\eta \beta_{k-1} \nabla_{\boldsymbol{\tau}} \mathcal{J}(\mu_{k-1})}_{\text{Guidance}}, \beta_{k-1}
\right)
Visualizing the guidance function gradient as a "force" applied to each trajectory point.
Single-Robot Generative Modeling
\mu^i_{k-1} \gets \mu^i_\theta(^{k}\boldsymbol{\tau}^i)
Denoising Process
^{k-1}\boldsymbol{\tau}^i \sim \mathcal{N} \left( \mu^i_{k-1} + \underbrace{\eta \beta_{k-1} \nabla_{\boldsymbol{\tau}} \mathcal{J}(\mu_{k-1})}_{\text{Guidance}}, \beta_{k-1}
\right)
Allows us to design "soft" spatio-temporal constraints via guidance functions.
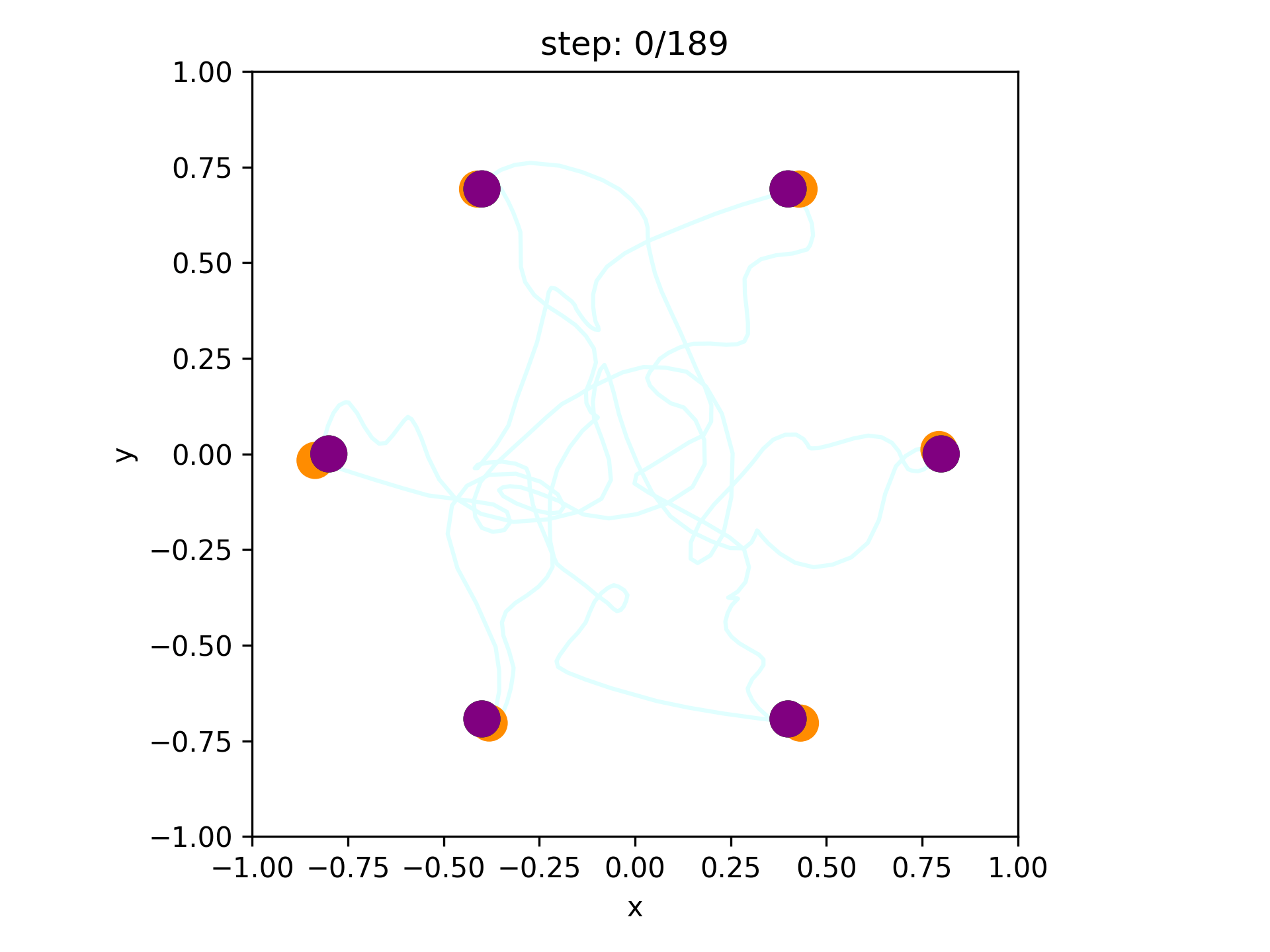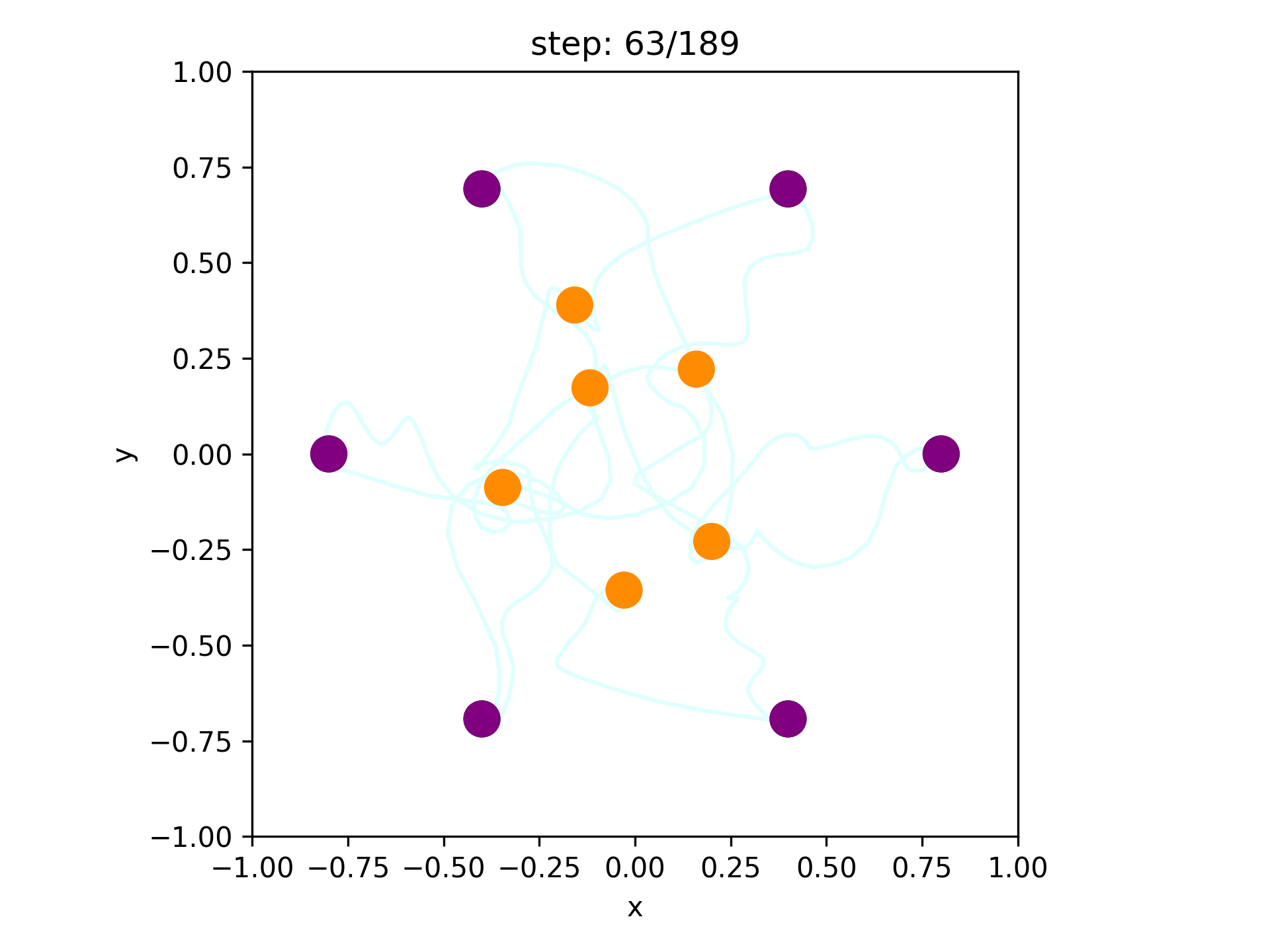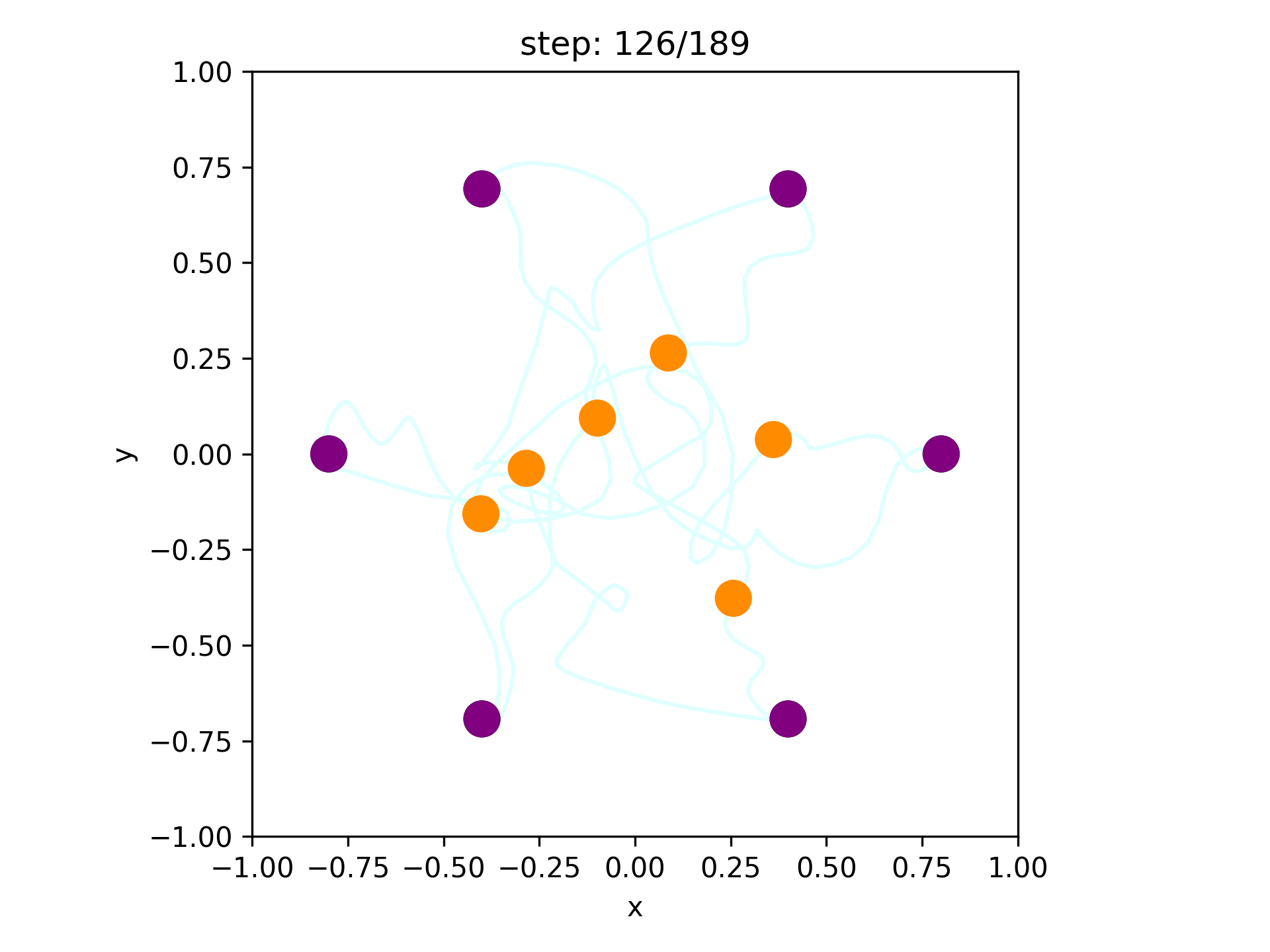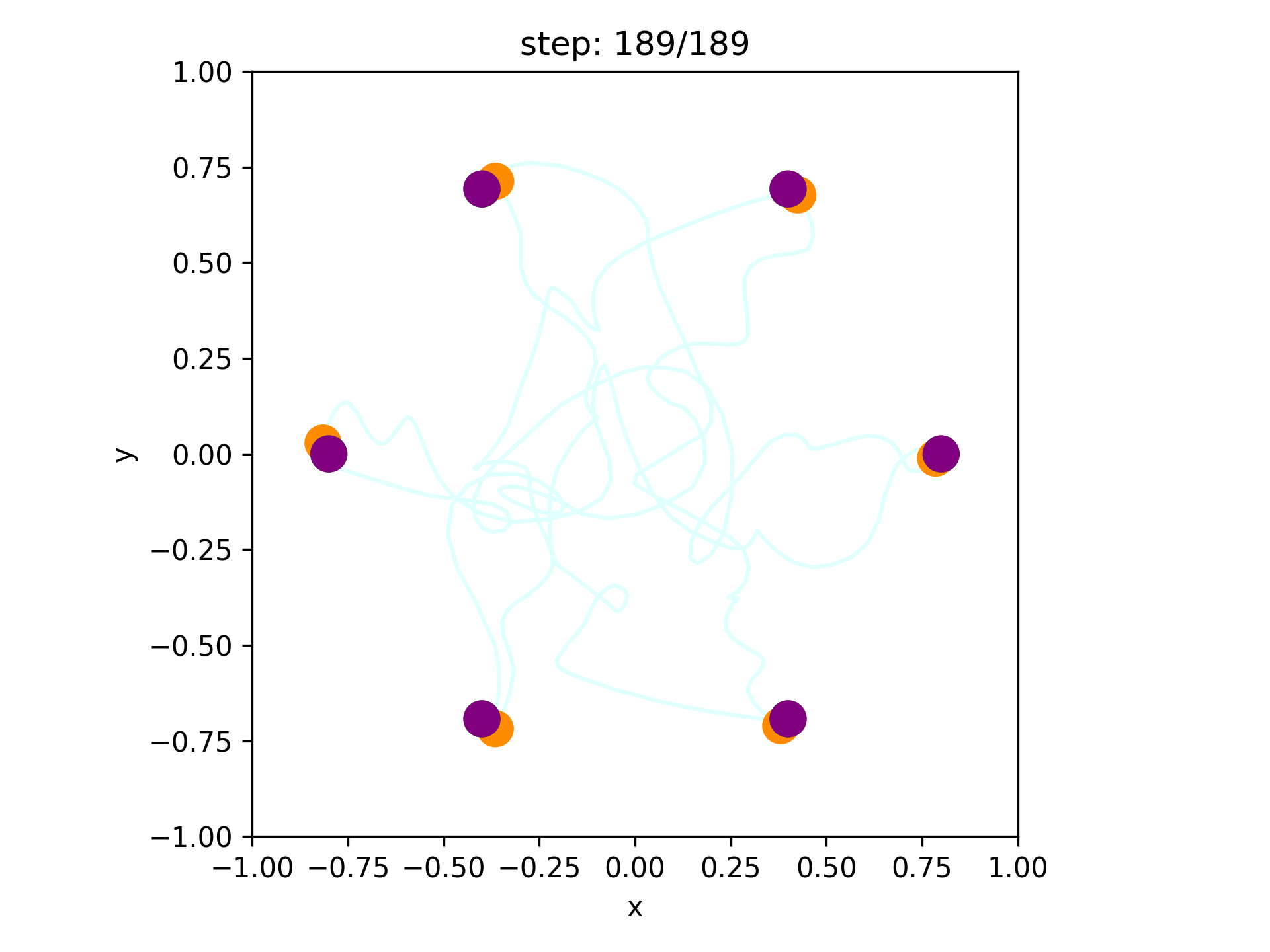
Multi-Robot Motion Planning with Diffusion Models (MMD)
Since single-robot diffusion models can admit constraints, we can use them within the CBS framework!
t=4
t=4
t=4
t=4
t=4
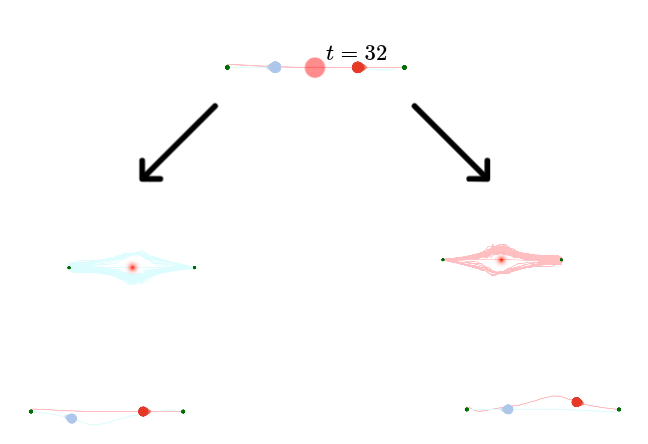
t=32
We must learn the motion patterns from data
And we can plan to coordinate the learned models
Multi-Robot Motion Planning with Diffusion Models (MMD)
Since single-robot diffusion models can admit constraints, we can use them within the CBS framework!
Motion Pattern
Learning single-robot trajectory generators and coordinating them with search proved to be an effective recipe.
MMD
"Conveyor"
"Highways"
Freespace
"Drop-Region"
Learning single-robot trajectory generators and coordinating them with search proved to be an effective recipe.
MMD
"Conveyor"
"Highways"
Freespace
"Drop-Region"
MMD-CBS
t=[5,7]
t=[2,4]
MMD-x(E)CBS
New Constraint
Previous Path
Noise a little.
Denoise.
PP
t=[1,2]
t=[2,3]
t=[3,4]
t=[4,5]
MMD-ECBS
t=[2,4]
t=1
t=2
t=3
t=4
"Weak
Constraints"
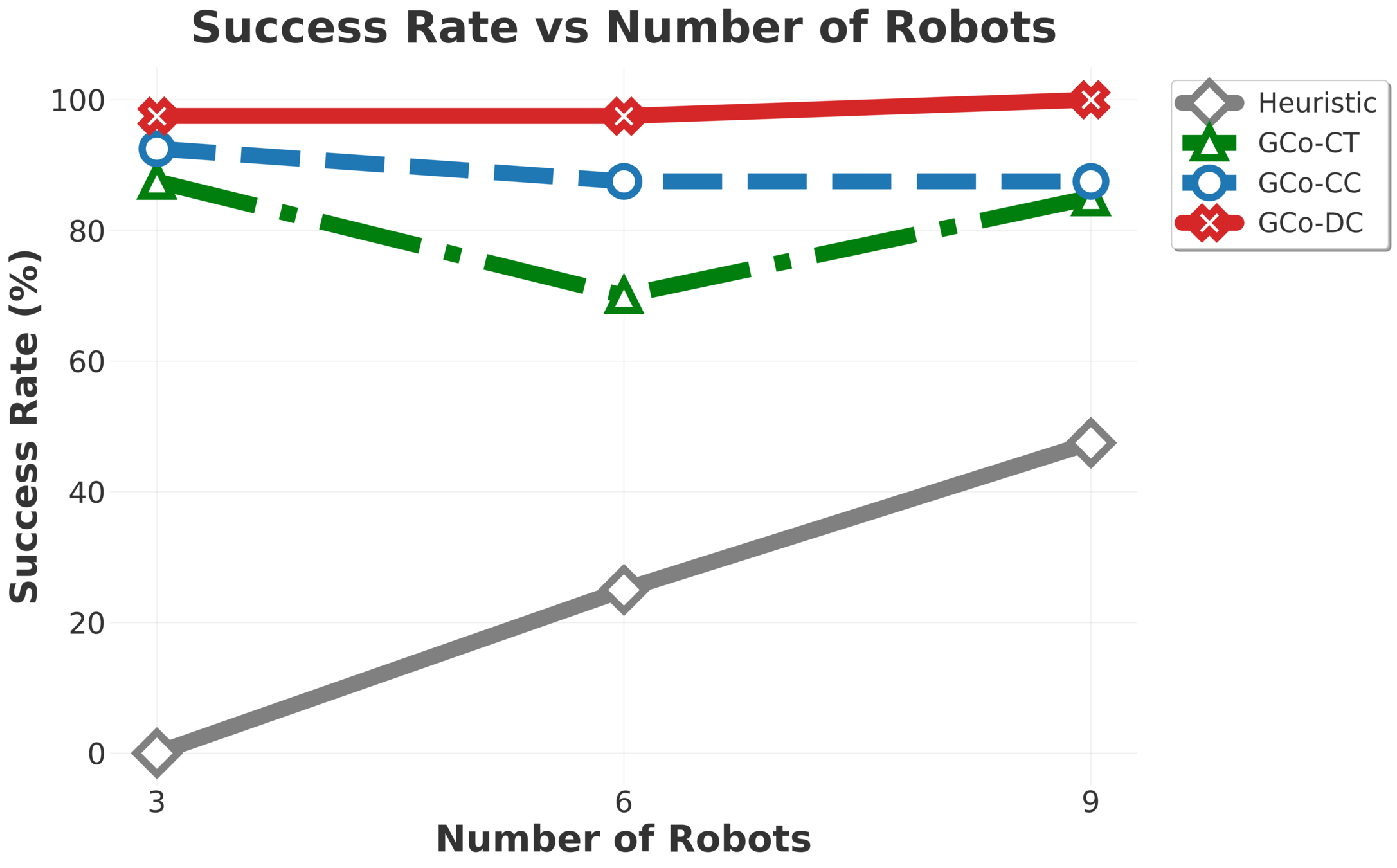
MMD: Experimental Evaluation
The higher success-rate, the better.
...without compromising data adherence.
Number of Agents
Success Rate
Number of Agents
Data Adherence
MMD: Experimental Evaluation
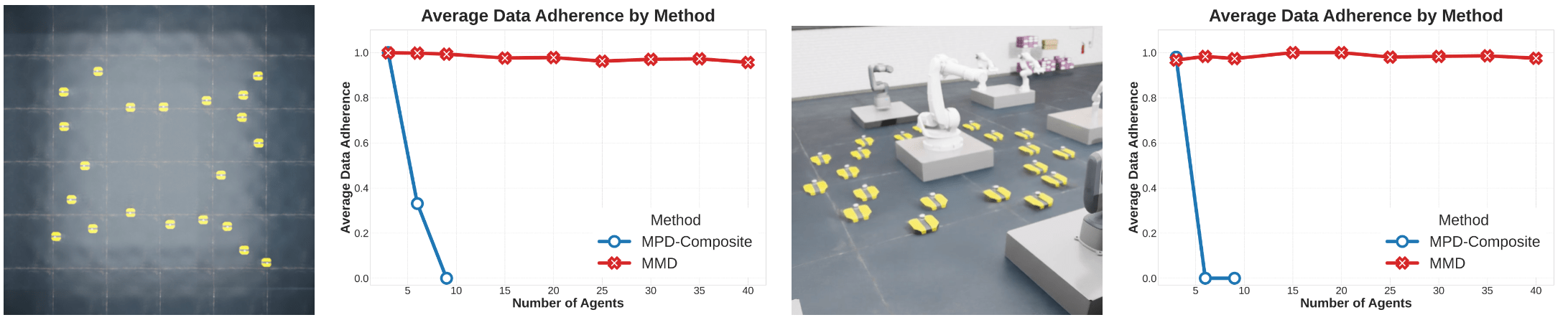
MMD scales much better than fixed-team-size models.
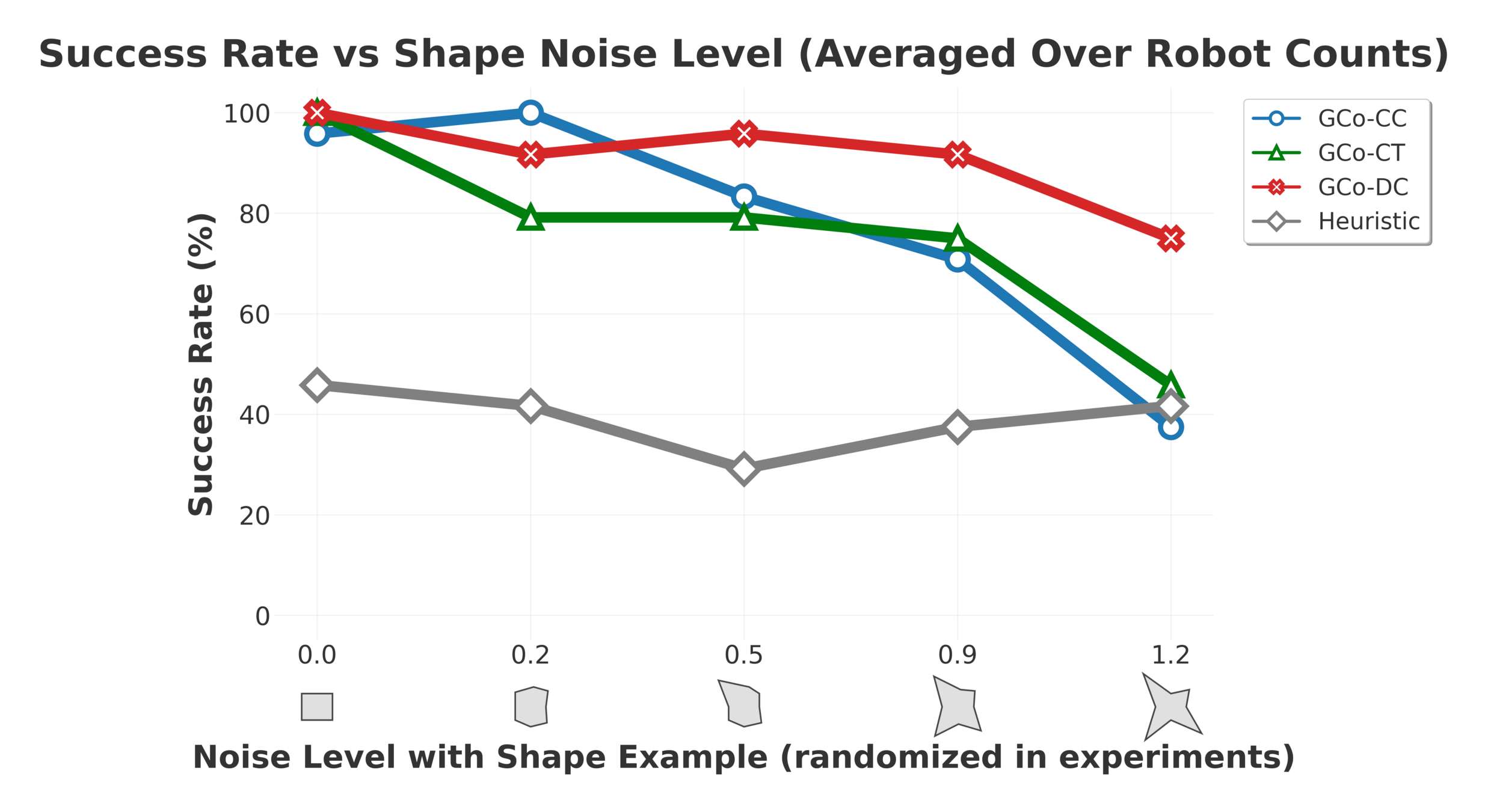
A familiar trend appears:
A naive application of CBS is insufficient, and ideas from improved algorithms help.
Easy
Hard
MMD: Experimental Evaluation

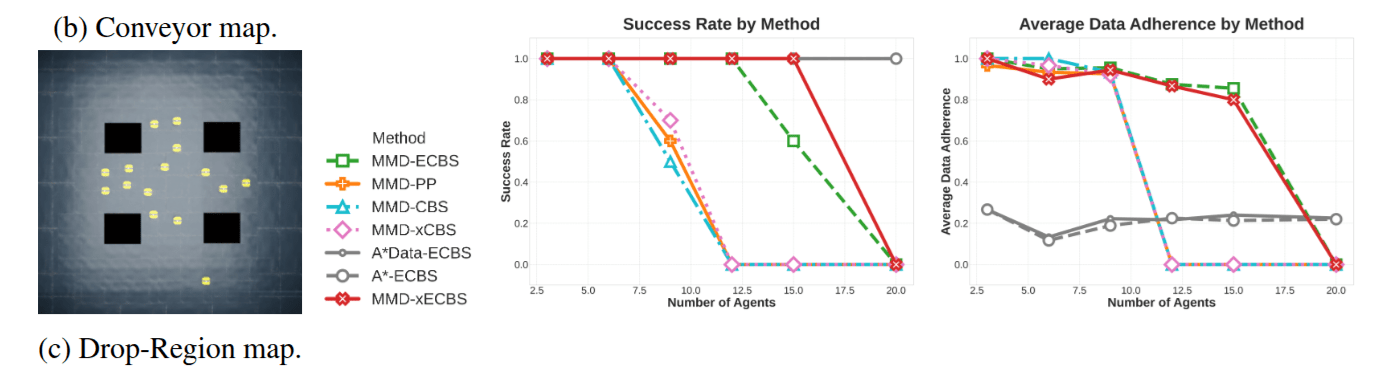
A familiar trend appears:
A naive application of CBS is insufficient, and ideas from improved algorithms help.
Easy
Hard
MMD: Experimental Evaluation
Takeaways
-
Learned models that admit constraints can be coordinated
with Conflict-Based Search (and other MAPF algorithms)
-
Negotiation through constraints does not destroy motion patterns
- Guidance functions allow for diffusion model constraint satisfaction
Coordination and Collaboration
In this part, we'll consider two types of problems:
Coordination
Robots have individual tasks and negoatiate space
Collaboration
Robots have a shared objective and must work together
The Collaborative Manipulation Problem
When robots work together, and depend on each other, to complete a global task, learning single-robot models becomes harder
Compute a set of robot motions
\(\Tau := \{\tau^i\}_{i=1}^N \) such that, upon execution, all objects arrive at their goals.
The Collaborative Manipulation Problem
(With multiple robots and multiple objects)
Our Approach: \(\text{G{\scriptsize CO}}\)
Plan Object Motions
Generate Manipulation Interactions
Plan Robot Motions
Input: object images and goals. Output: short horizon robot motions \(\Tau := \{\tau^i\}_{i=1}^N \).
Plan Object Motions
Generate Manipulation Interactions
Plan Robot Motions
Plan motions
to contact points
Learn physical
interactions
Plan motions
for objects
A new anonymous multi-robot motion planning algorithm.
The Components of \(\text{G{\scriptsize CO}}\)
A novel flow matching co-generation manipulation interaction generation model.
We fundamentally have two decisions to make here:
- Where to make contact
- How to move.
Flow Matching Co-Generation for Contact Modeling
Flow-Matching
\(\Phi(^0\mathcal{T})\)
Noise
~Data Distribution
Flow-Matching
Flow-matching generates new samples from noise by learning a velocity field and integrating it.
X_{t + \Delta t} \gets X_{t} + u_t^\theta(X_t) \cdot \Delta t
Learn
\(\mathcal{K}, \mathcal{T} \gets \pi_\theta( \mathcal{I}, T \in SE(2))\)
from simulated demonstrations
We fundamentally have two decisions to make here:
- Where to make contact
- How to move.
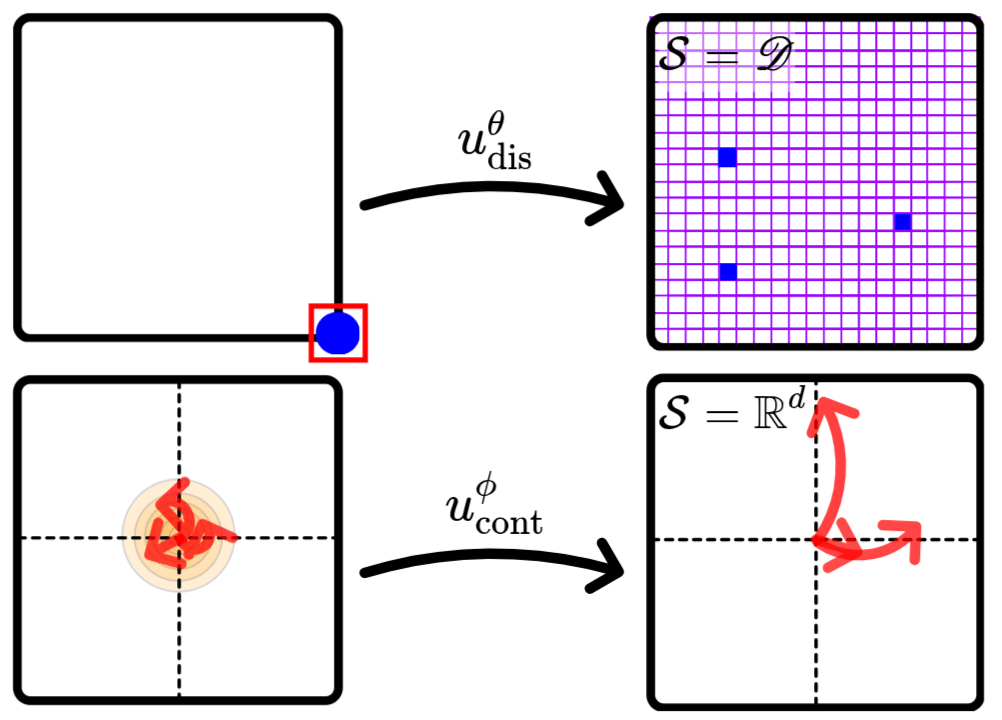
\(u^\theta_\text{dis}\)
\(u^\phi_\text{cont}\)
Flow Matching Co-Generation for Contact Modeling
Generate continuous manipulation trajectories.
We fundamentally have two decisions to make here:
- Where to make contact
- How to move.
\(u^\theta_\text{dis}\)
\(u^\phi_\text{cont}\)
Tie contact points to the
discrete observation-space.
Generate continuous manipulation trajectories.
\mathcal{S} = \mathbb{R}^d
\mathcal{S} = \mathscr{D}
Flow Matching Co-Generation for Contact Modeling
Contact Point Generation
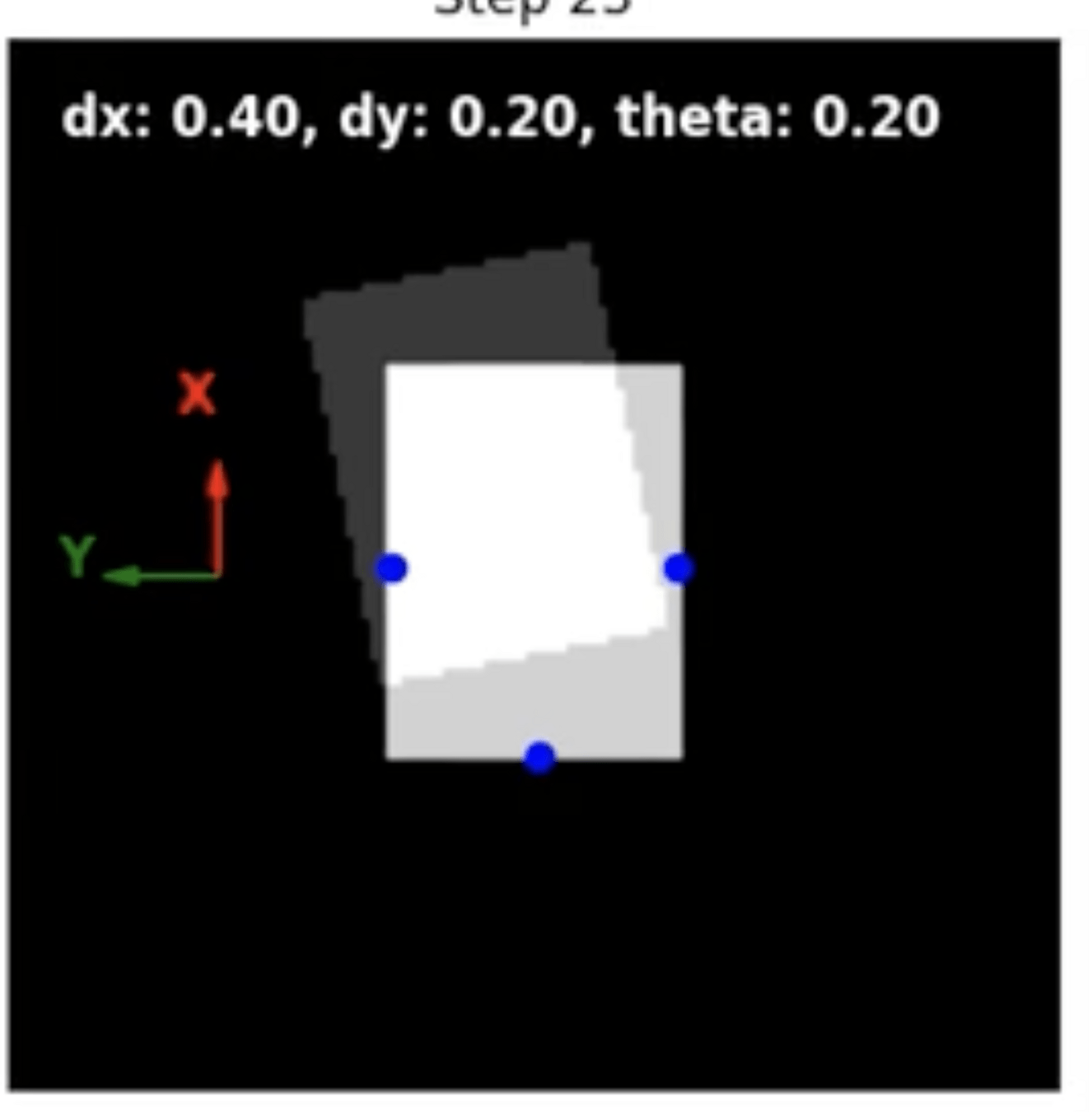
We can pose this as a discrete problem, asking
which pixels in our image observation should be used for contact points?

Discrete Flow Matching
Flow
Diffusion
\mathcal{S} = \mathbb{R}^d
\mathcal{S} = \mathbb{R}^d
\mathcal{S} = \mathscr{D}
Discrete Flow
Discrete Flow Matching
Let's look at this 2D state space for example:
- State space of token sequences \(\mathcal{S} = \mathscr{T}^d\).
- In our case \(d=2\), and a state is \(x = (x^1, x^2)\).
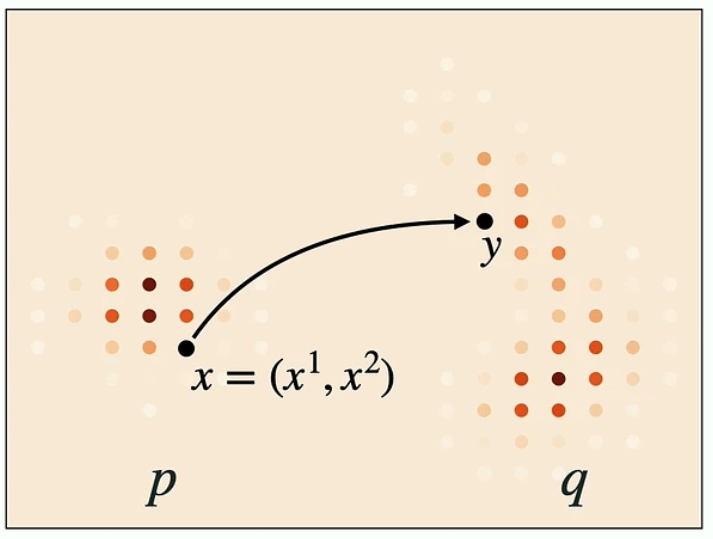
As before, we require two components:
- A velocity field \(u_t(y,x)\), and
- An initial value \(X_0\).
Getting an initial value is easy. We could
- Sample each token uniformly over the vocabulary
- Set all to a "mask" value \(X_0 = (\texttt{[M]}, \texttt{[M]}, \cdots)\)
Discrete Flow Matching: Velocity Field
For the velocity field, things are a bit different in the discrete case.
For some state \(x=(x^1, x^2)\), we want
- The probability of \(x^1\) transitioning to \(X^1_1\) should be \(1\), and
- The probability of \(x^2\) transitioning to \(X_1^2\) should be \(1\).
That is, we could define a factorized velocity \(u^i(\cdot, x) = \delta_{X^i_1}\).
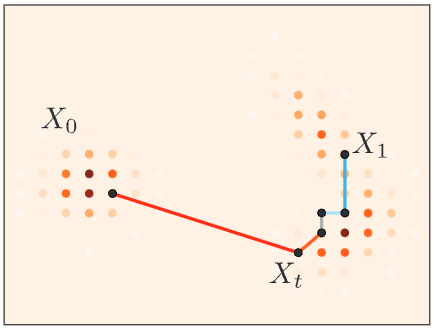
Discrete Flow Matching: Interpolation
In continuous flow matching, we asked a model to predict the velocity at some interpolated state \(x_t\).
Given \(X_0\) and \(X_1\), one way to obtain \(X_t\) in the discrete case is to have each element \(X_t^i\) as
- \(X_0^i\) with probability \((1-t)\)
- \(X_1^i\) with probability \(t\)
Discrete Flow Matching: Training
Similar to the continuous case
- Randomly choose \(X_0\) from the noise distribution \(p_0\) and \(X_1\) from the dataset.
- Sample \(t \sim U(0,1)\).
- Get \(X_t\) from "mixing" interpolation.
- Set target velocity \(u^i(\cdot, x) = \delta_{X^i_1}\).
- Supervise on the loss
\[ \mathcal{L}_\text{dis}:= \mathbb{E}_{t, X_1, X_t} \sum_{i} D_{X_t} \left( \dfrac{1}{1-t} \delta(\cdot, X_1^i), u_t^{\theta, i}(\cdot, X_t) \right) \\ \; \\ \theta^* = \arg \min_\theta \mathcal{L}_\text{dis}\]
Discrete Flow Matching: Generation
In essence, a similar process to the continuous case.
Starting with \(X_t = X_0\):
- Compute velocity (i.e., logits) \(u^\theta_t(\cdot, X_t)\)
- Obtain \(X_{t + \Delta t}\) by sampling from the categorical distribution defined by the logits \(u^\theta_t(\cdot, X_t)\)
We fundamentally have two decisions to make here:
- Where to make contact
- How to move.
\(u^\theta_\text{dis}\)
\(u^\phi_\text{cont}\)
\mathcal{S} = \mathbb{R}^d
\mathcal{S} = \mathscr{D}
Flow Matching Co-Generation for Contact Modeling
We fundamentally have two decisions to make here:
- Where to make contact
- How to move.
\(u^\theta_\text{dis}\)
\(u^\phi_\text{cont}\)
\mathcal{S} = \mathbb{R}^d
\mathcal{S} = \mathscr{D}
Flow Matching Co-Generation for Contact Modeling
The models flexibly select number of robots, given a budget.
Flow Matching Co-Generation for Contact Modeling
- For flow-matching co-generation [1, 2], operates on two state spaces:
- Discrete contact points: \(K \in \mathscr{D}^{B \times 2}\)
- Continuous trajectories: \(\mathcal{T} \in \mathbb{R}^{B \times H \times 2}\)
- Concurrently learn two velocity fields:
- a continuous velocity field \(u^{\theta}_{\text{cont},t}(^t\mathcal{T})\),
- and "discrete velocity" \(u^{\theta, i}_{\text{dis},t}(\cdot, ^{t\!}K^i)\).
- (Factorized discrete logits.)
- And generate by:
- Sampling \(^0\mathcal{T} \sim \mathcal{N}(\bm{0}, \bm{I})\) and \(^0K := \{(\text{M},\text{M})\}^B\)
- Integrating
\(u^\theta_\text{dis}\)
\(u^\phi_\text{cont}\)
\mathcal{S} = \mathbb{R}^d
\mathcal{S} = \mathscr{D}
\begin{pmatrix}
^{t+\Delta t}K\\[4pt]
^{t+\Delta t}\mathcal{T}
\end{pmatrix}
\gets
\begin{pmatrix}
\text{Categorical} \left( u^{\theta, i}_{\text{dis},t}(\cdot, ^tK^i) \right) \\[4pt]
^{t}\mathcal{T} +\;\Delta t\, u^{\theta, i}_{\text{cont},t}(^t\mathcal{T}^i)
\end{pmatrix}
Flow Matching Co-Generation for Contact Modeling
- For flow-matching co-generation [1, 2], operates on two state spaces:
- Discrete contact points: \(K \in \mathscr{D}^{B \times 2}\)
- Continuous trajectories: \(\mathcal{T} \in \mathbb{R}^{B \times H \times 2}\)
- Concurrently learn two velocity fields:
- a continuous velocity field \(u^{\theta}_{\text{cont},t}(^t\mathcal{T})\),
- and "discrete velocity" \(u^{\theta, i}_{\text{dis},t}(\cdot, ^{t\!}K^i)\).
- (Factorized discrete logits.)
- And generate by:
- Sampling \(^0\mathcal{T} \sim \mathcal{N}(\bm{0}, \bm{I})\) and \(^0K := \{(\text{M},\text{M})\}^B\)
- Integrating
\begin{pmatrix}
^{t+\Delta t}K\\[4pt]
^{t+\Delta t}\mathcal{T}
\end{pmatrix}
\gets
\begin{pmatrix}
\text{Categorical} \left( u^{\theta, i}_{\text{dis},t}(\cdot, ^tK^i) \right) \\[4pt]
^{t}\mathcal{T} +\;\Delta t\, u^{\theta, i}_{\text{cont},t}(^t\mathcal{T}^i)
\end{pmatrix}
Flow Matching Co-Generation for Contact Modeling
- Discrete-contnuous flow-matching proved to be more robust than alternatives.
- Continuous-continuous flow matching followed,
- Continuous "naive" flow matching was least stable.
\begin{pmatrix}
K_{t+\Delta t}\\[4pt]
X_{t+\Delta t}
\end{pmatrix}
\gets
\begin{pmatrix}
\text{Categorical} \left( u^{\theta, i}_\text{dis}(\cdot, K_t^i) \right) \\[4pt]
X_{t} +\;\Delta t\, u^{\theta, i}_\text{cont}(X_t^i)
\end{pmatrix}
Observation
Transform
\bm{T} \in SE(2)
Contacts
\(K_t \in \mathscr{D}^{2\cdot N}\)
Trajectories
\(X_t \in \mathbb{R}^{2\cdot N \cdot H} \)
u^{\theta}_{\text{cont},t}(X_t)
u^{\theta, i}_{\text{dis},t}(\cdot, K_t^i)
Flow Matching Co-Generation for Contact Modeling
Flow Matching Co-Generation for Contact Modeling
Plan Object Motions
Generate Manipulation Interactions
Plan Robot Motions
Plan motions
to contact points
Learn physical
interactions
Plan motions
for objects
- A novel flow matching co-generation manipulation interaction generation model.
- A new anonymous multi-robot motion planning algorithm.
The Components of \(\text{G{\scriptsize CO}}\)
Anonymous Multi-Robot Motion Planning
Object- and robot-planning fall under the same algorithmic umbrella.
- Given a set of goal configurations,
- Compute motions for all entities to
reach them.- Assignment is not fixed.
Plan compositions of short actions
Anonymous Multi-Robot Motion Planning
Object- and robot-planning fall under the same algorithmic umbrella.
- Given a set of goal configurations,
- Compute motions for all entities to
reach them.- Assignment is not fixed.
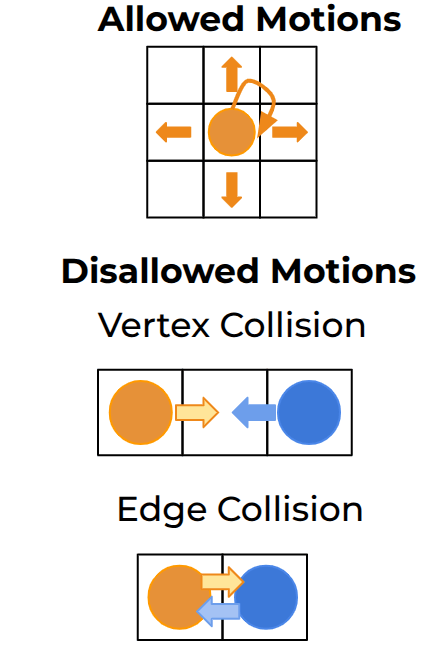
Anonymous Multi-Agent Path Finding (MAPF), traditionally, is solved on regular grids.
Some Background: Motion Primitives
Regular grid.
Motion primitives.

kei18.github.io
Anonymous Multi-Robot Motion Planning
What we want
Livelocks
(PIBT with motion primitives)
Deadlocks
(TSWAP with motion primitives)
What we get
(from naively applying existing AMAPF ideas)
To mitigate these issues, we developed the "\(\text{G\scriptsize SPI}\)" algorithm, a "continuous-space" hybrid adaptation of PIBT with goal-swapping inpired by TSWAP and C-UNAV.
Anonymous Multi-Robot Motion Planning
PIBT
+ Goal Swapping
= \(\text{G\scriptsize SPI}\) (Goal Swapping with Priority Inheritance)
Priority inheritance with backtracking adapted to non-point robots moving along motion primitives.
Goals and priorities are swapped when this benefits the higher priority robot and the system.
\(\text{{G\scriptsize SPI}}\) is efficient and scales to 300 robots in our experiments.
Results: \(\text{G{\scriptsize SPI}}\)
\(\text{{G\scriptsize SPI}}\) handles stress tests that often break algorithms:
- Extremely tight spaces and "following" concurrent movements.
\(\text{G{\scriptsize SPI}}\) Analysis
Some results
\(\text{G{\scriptsize SPI}}\) Analysis
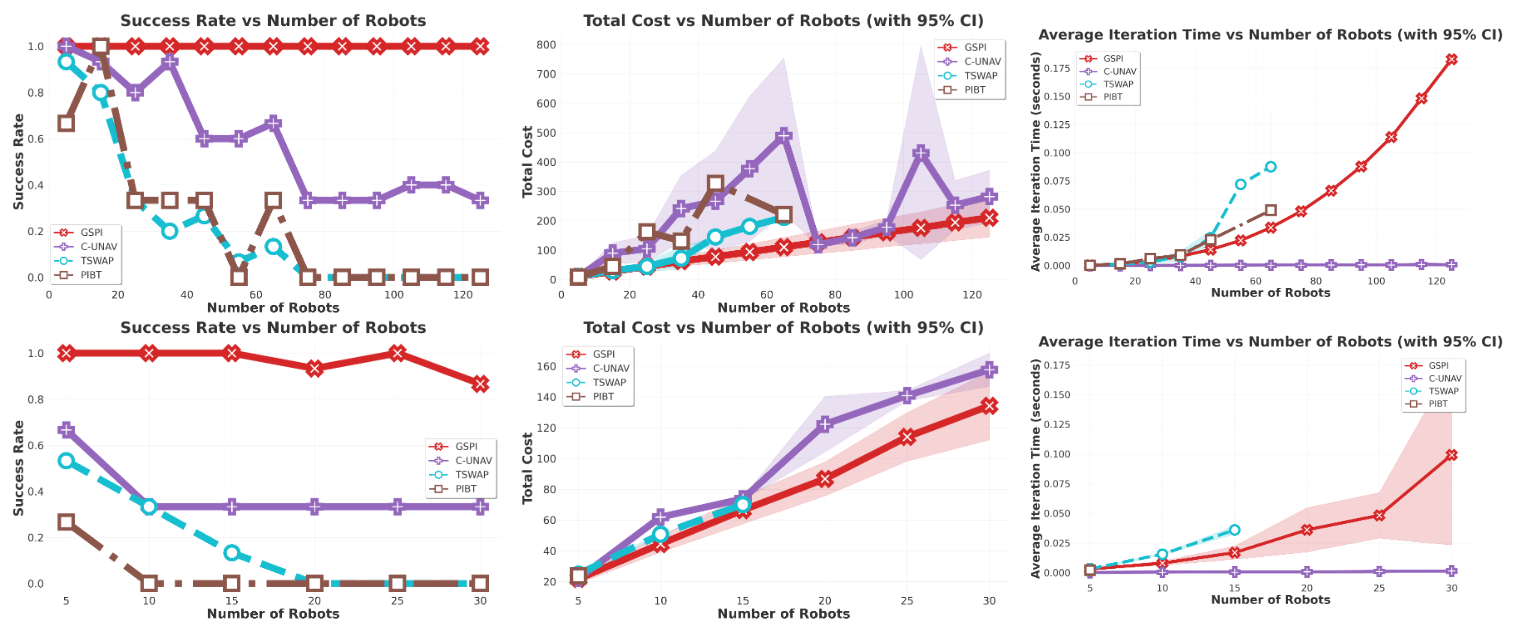
Results
\(\text{G{\scriptsize SPI}}\) Analysis
C-UNAV / ORCA
Failure cases for baselines
PIBT
TSWAP
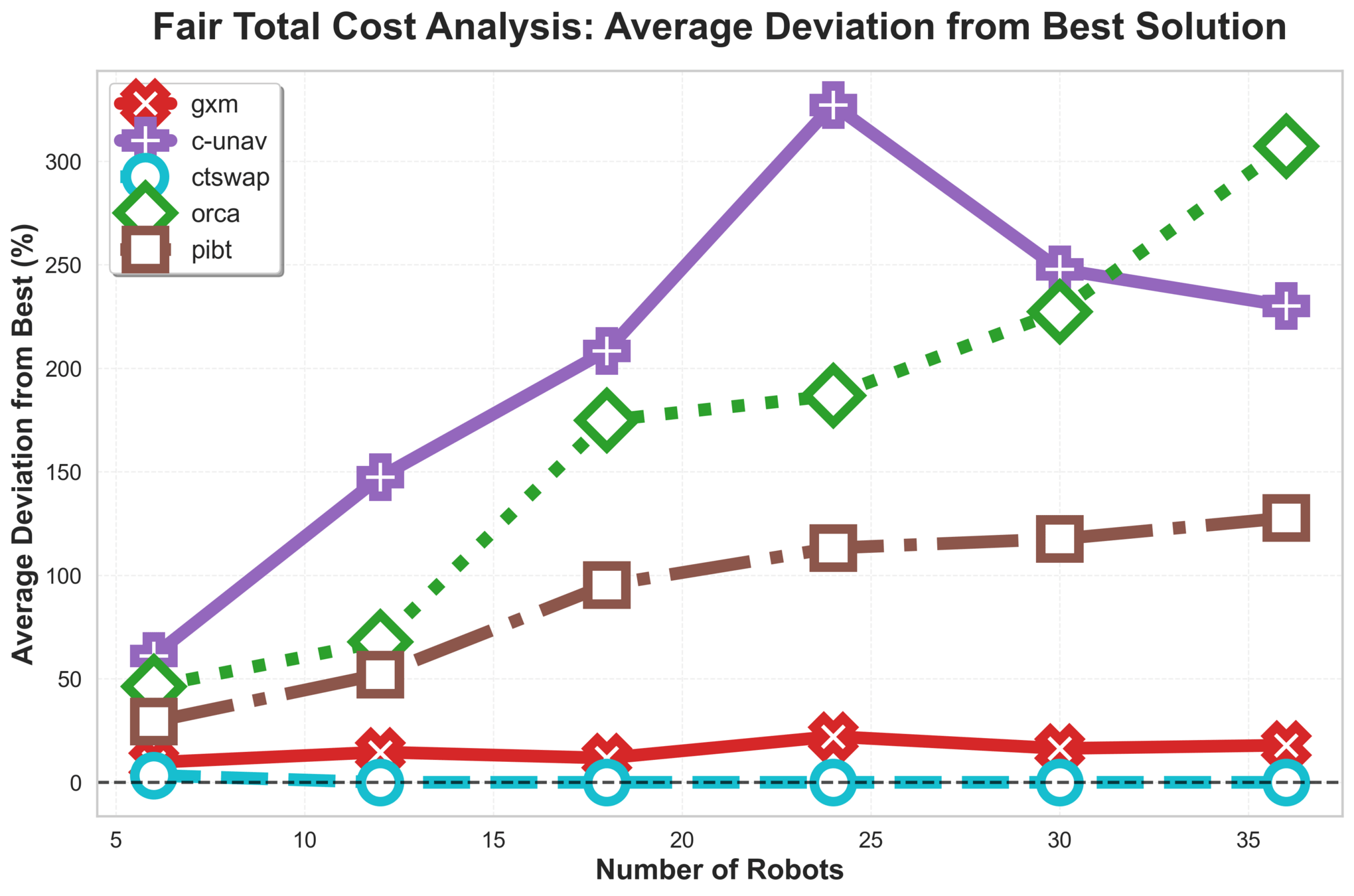
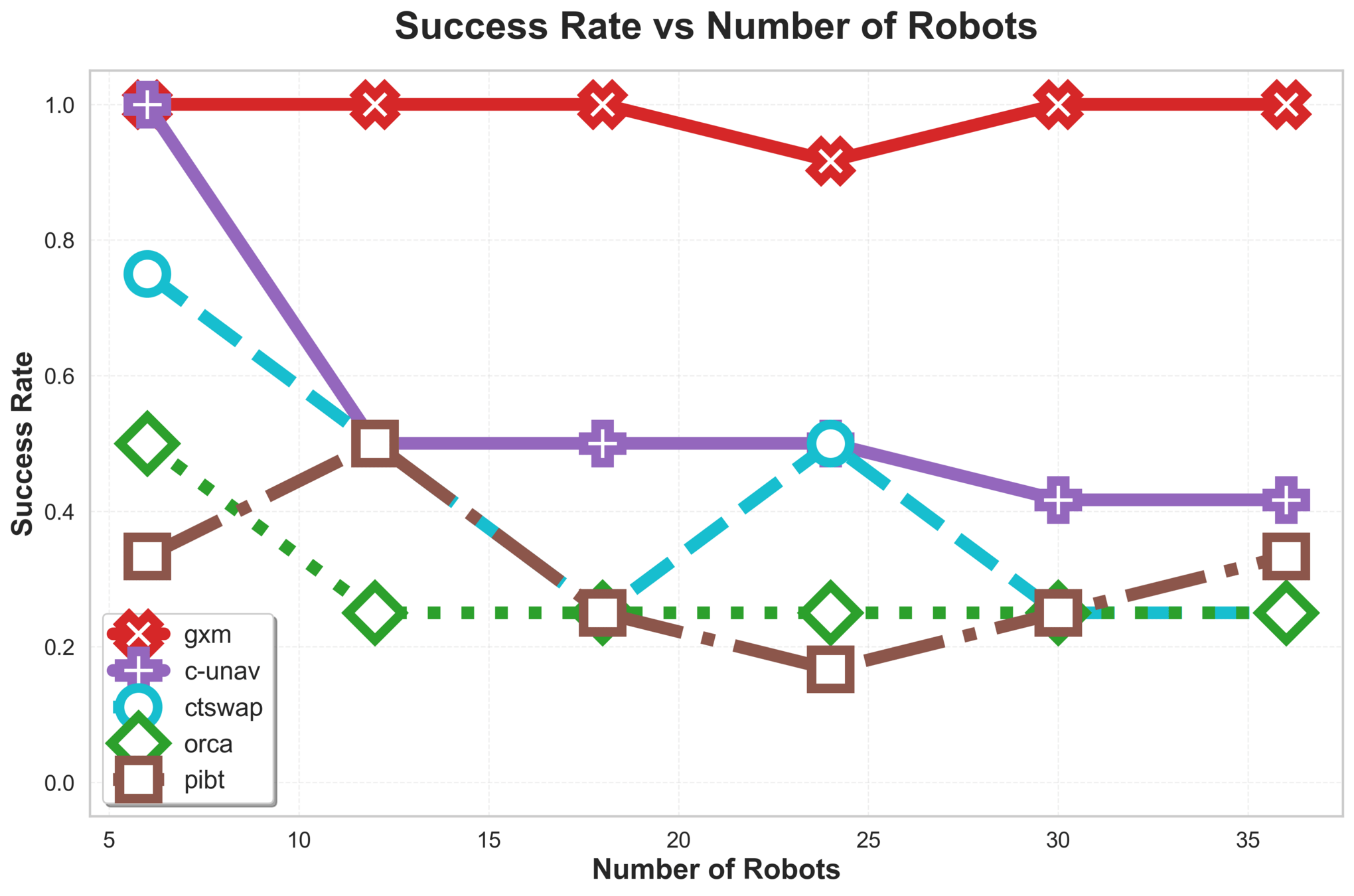
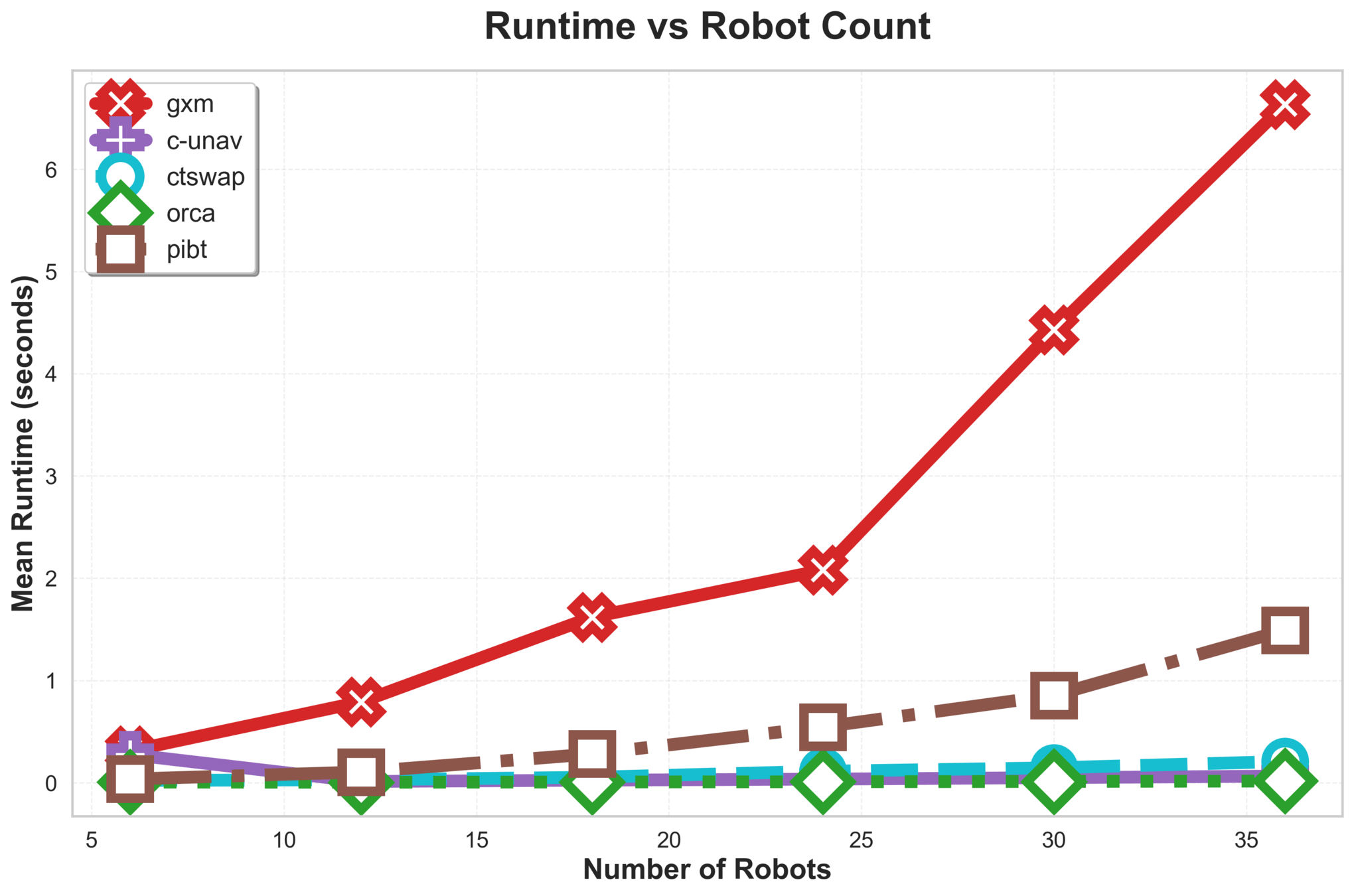
Anonymous Multi-Robot Motion Planning
Object- and robot-planning fall under the same algorithmic umbrella.
- Given a set of goal configurations,
- Compute motions for all entities to
reach them.- Assignment is not fixed.
Our Approach: \(\text{G{\scriptsize CO}}\)
Plan Object Motions
Generate Manipulation Interactions
Plan Robot Motions
Plan Robot Motions
\(\pi_\theta\)
Manipulation Policy
Anonymous Multi-Entity Motion Planner
Anonymous Multi-Entity Motion Planner
Input: object images. Output: short horizon robot motions \(\Tau := \{\tau^i\}_{i=1}^N \).
Collaborative Manipulation - Exprimental Evaluation
\(\text{GC}\scriptsize{\text{O}}\) composes per-object models, scaling to nine robots and five objects, including cases where objects outnumber robots.
Collaborative Manipulation - Brief Results
Gradually increasing test difficulty.
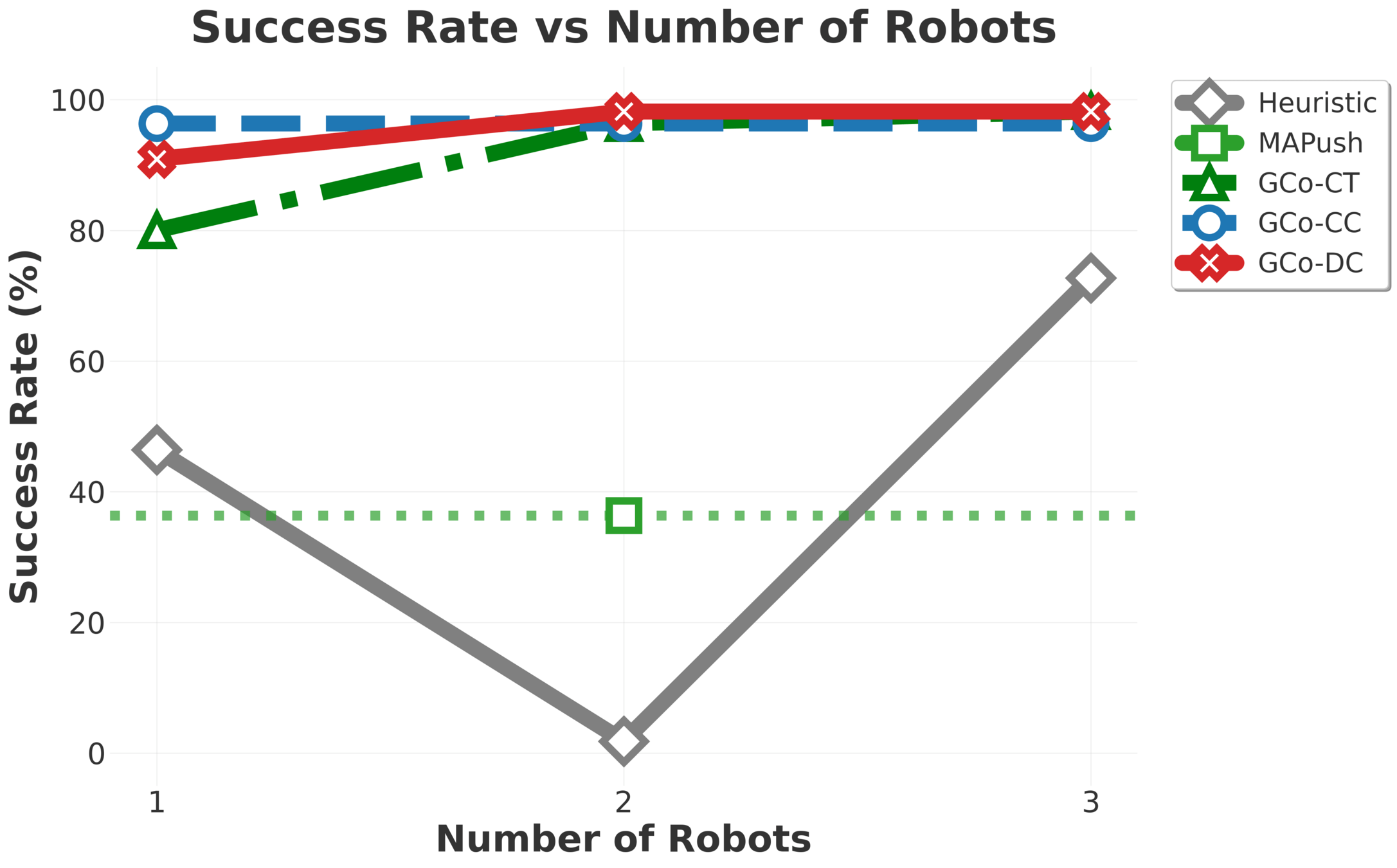
Collaborative Manipulation - Stress Testing
Despite being trained only on rectangles and circles, the models handle arbitrary polygons thanks to the flexibility in the observation medium.
\underbrace{ \qquad \qquad \qquad \qquad}
In distribution.
\underbrace{ \qquad \qquad \qquad \qquad \qquad\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;}
Out of distribution.
Collaborative Manipulation - Brief Results
Gradually increasing test difficulty.
Collaborative Manipulation - Exprimental Evaluation
\(\text{GC}\scriptsize{\text{O}}\) composes per-object models, scaling to nine robots and five objects, including cases where objects outnumber robots.
Takeaways
- We can plan freespace motions geometrically,
and learn contact interactions from demonstrations
- Scalability is achieved through planning single-objective model compositions

Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation
Thesis Roadmap
Plan what we can, and learn what we must.
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
Search-based algorithms are effective for multi-arm motion planning
[ICAPS 24, SoCS 24]
Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation
Thesis Roadmap
Plan what we can, and learn what we must.
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
Search-based algorithms are effective for multi-arm motion planning
[ICAPS 24, SoCS 24]
Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation
\underbrace{\qquad \qquad \qquad \quad \;}{}
Single-robot and single-objective model composition scales to larger problems
[ICLR 25, In Review 2026]
Thesis Roadmap
Plan what we can, and learn what we must.
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
Search-based algorithms are effective for multi-arm motion planning
[ICAPS 24, SoCS 24]
Thesis Roadmap
The building blocks we have developed:
- Enable efficient and safe multi-robot motion in shared space
- Coordinate policies without exponential data needs
- Interleave planning and learning for collaboration
What we want, is to enable flexible multi-arm manipulation systems.
AI Generated, Grok
Interleaving Planning and Learning for Multi-Arm Manipulation
Proposed work
Proposed Areas of Research
AI Generated, Grok
Collaborative Multi-Arm Manipulation
- Current ideas
- Research questions
- Expected focus
Coordinated Multi-Arm Manipulation
- Current ideas
- Research questions
- Expected focus
Our main goal:
- Perform long horizon collaborative manipulation with
- Large (rigid) 3D objects
- Multiple arms
- Contact-rich dynamics
AI Generated, Grok
Collaborative Multi-Arm Manipulation
Plan Object Motions
Generate Manipulation Interactions
Plan Robot Motions
Collaborative Multi-Arm Manipulation: Current Ideas
Follow the GCo framework, and create new methods for scaling to manipulators.
Plan Object Motions
Generate
Manipulation Interactions
Embody
Manipulation Interactions
Plan Robot
Motions
- How should we plan for objects?
- What is a good object representation for policy learning?
- How should we learn these interactions?
- How to transfer from "hands" to arms?
- How to compute freespace motions?
Collaborative Multi-Arm Manipulation: Research Questions
Plan Object Motions
Generate
Manipulation Interactions
Embody
Manipulation Interactions
Plan Robot
Motions
- How should we plan for objects?
- What is a good object representation for policy learning?
- How should we learn these interactions?
- How to transfer from "hands" to arms?
- How to compute freespace motions?
A*
Search
Collaborative Multi-Arm Manipulation: Research Questions
Plan Object Motions
Generate
Manipulation Interactions
Embody
Manipulation Interactions
Plan Robot
Motions
- What is a good object representation for policy learning?
- How should we learn these interactions?
- How to transfer from "hands" to arms?
- How to compute freespace motions?
A*
Search
xECBS
Collaborative Multi-Arm Manipulation: Research Questions
- How should we plan for objects?
Plan Object Motions
Generate
Manipulation Interactions
Embody
Manipulation Interactions
Plan Robot
Motions
- What is a good object representation for policy learning?
- How should we learn these interactions?
- How to transfer from "hands" to arms?
- How to compute freespace motions?
A*
Search
xECBS
?
Collaborative Multi-Arm Manipulation: Research Questions
- How should we plan for objects?
Follow a similar approach as \(\text{G\scriptsize{CO}}\). Generating demonstration data in simulation.
- Where to make contact
- How to move.
Generating Manipulation Interactions for General Objects
Collaborative Multi-Arm Manipulation: Current Ideas
Plan Object Motions
Generate
Manipulation Interactions
Embody
Manipulation Interactions
Plan Robot
Motions
- What are feasible motion primitives?
- How do we determine which contacts can be safely removed without compromising balance?
- What is a good object representation for policy learning?
- How should we learn these interactions?
- How to transfer from "hands" to arms?
- How to compute freespace motions?
A*
Search
xECBS
?
Collaborative Multi-Arm Manipulation: Current Ideas
Plan Object Motions
Generate
Manipulation Interactions
Embody
Manipulation Interactions
Plan Robot
Motions
- What are feasible motion primitives?
- How do we determine which contacts can be safely removed without compromising balance?
- What is a good object representation for policy learning?
- How should we learn these interactions?
- How to transfer from "hands" to arms?
- How to compute freespace motions?
A*
Search
xECBS
?
?
Collaborative Multi-Arm Manipulation: Current Ideas

We need a method that reasons over
-
Assignments
Most modern manipulation policies output
motions for hands, and not arms. Embodying them is not trivial.
Embodying Multi-Hand Manipulation Interactions
Collaborative Multi-Arm Manipulation: Current Ideas
We need a method that reasons over
-
Assignments
-
Redundant motions
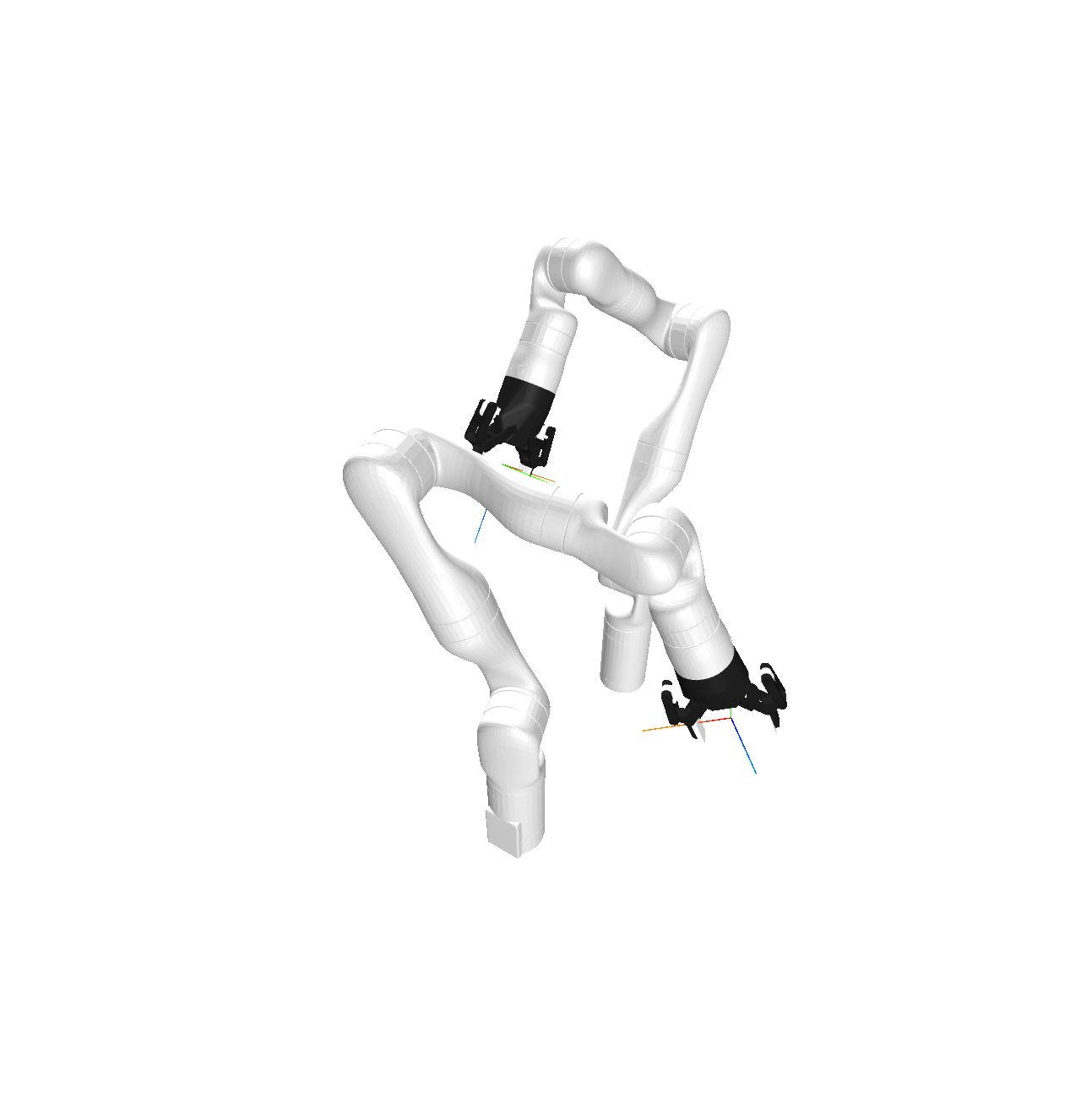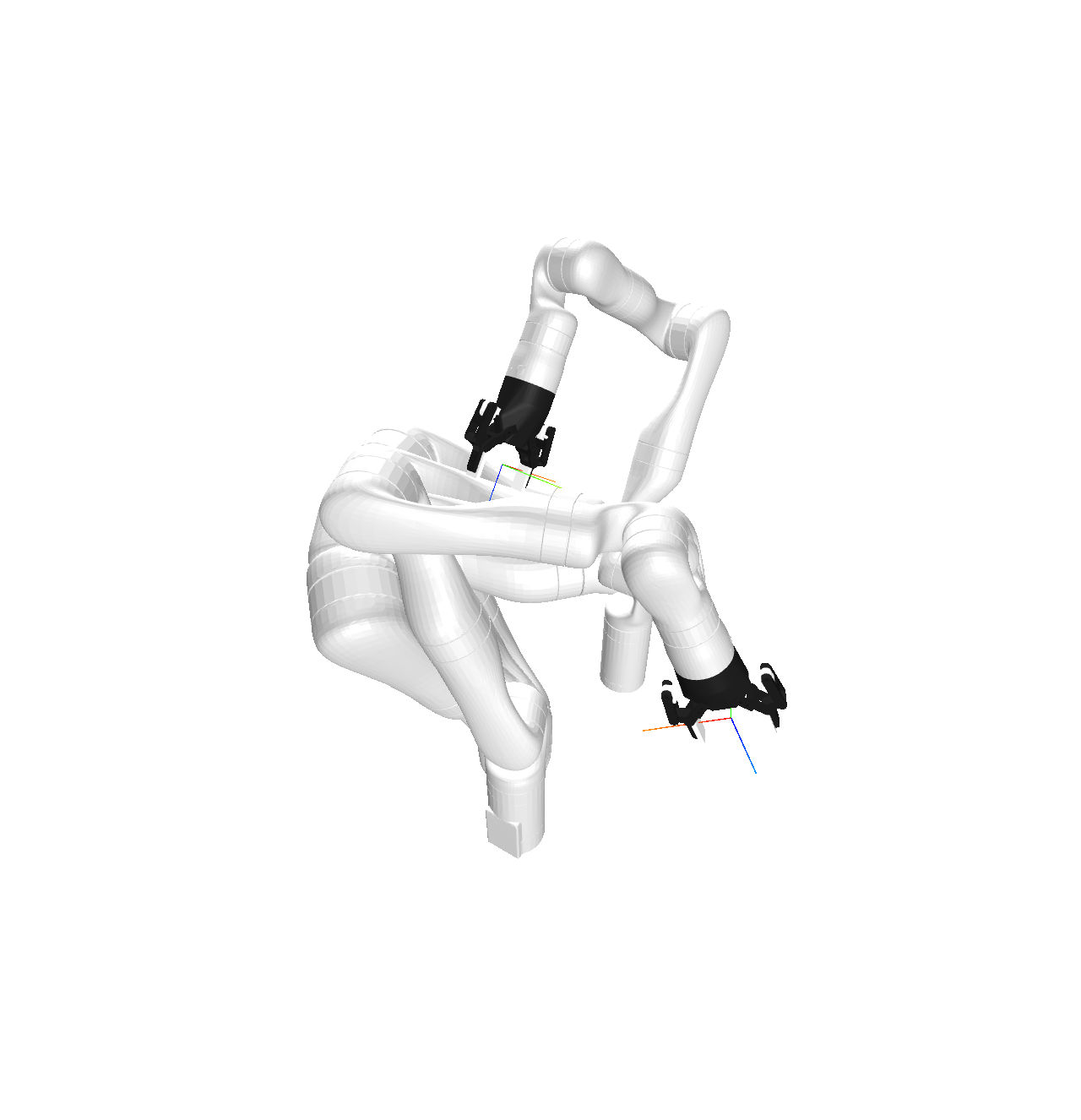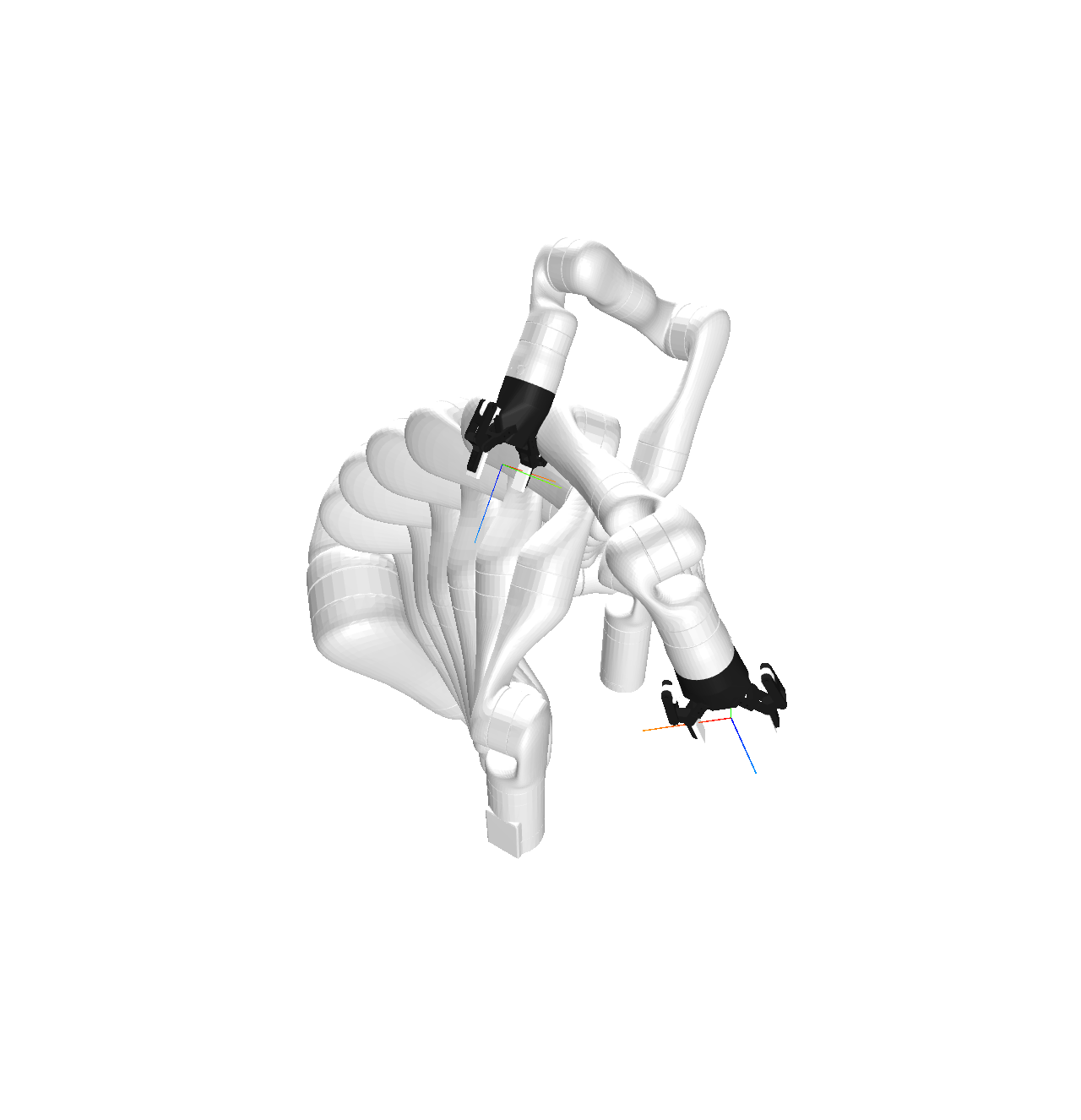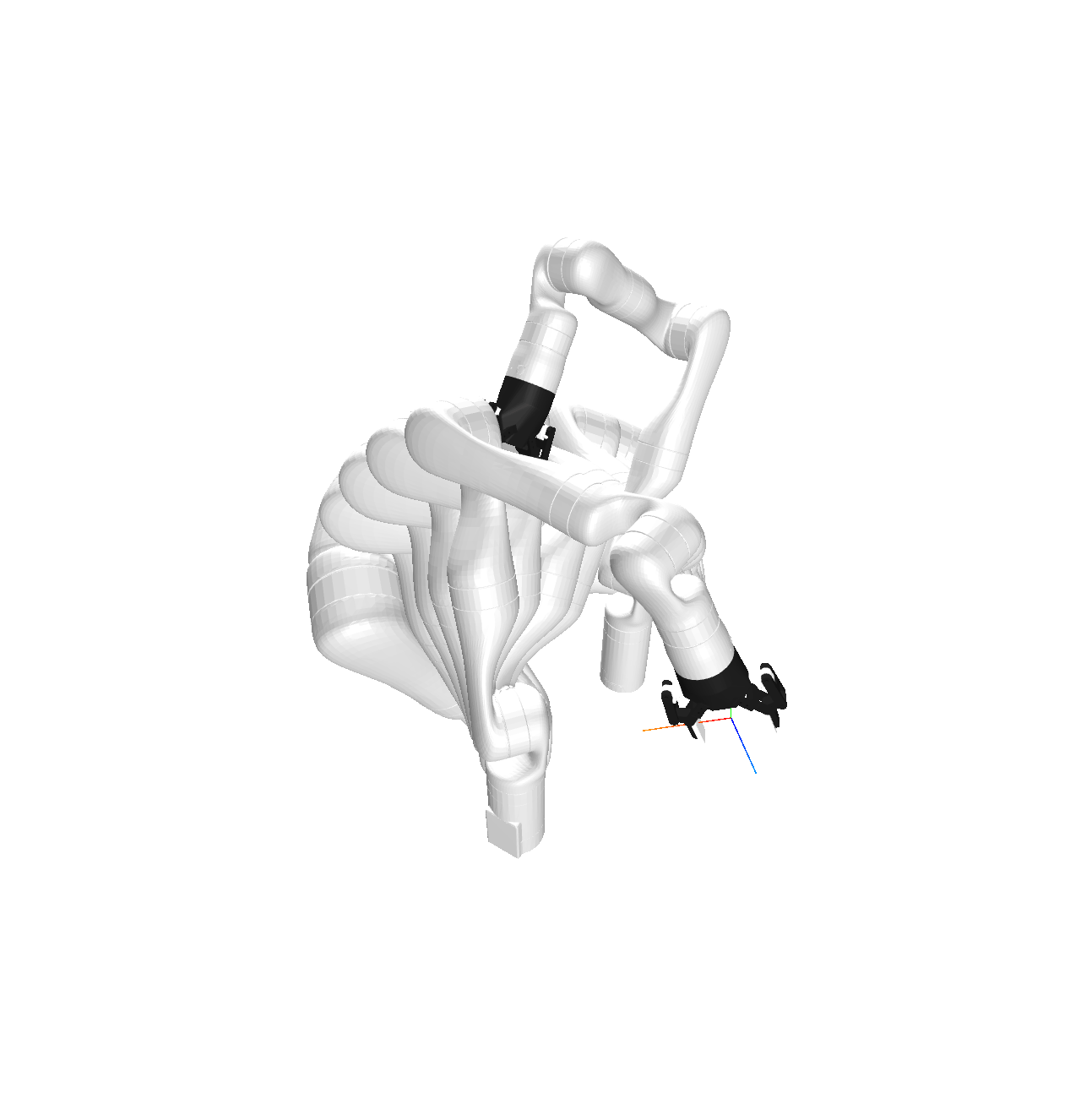
x \in SE(3)
\mathcal{M} = \{q \in \mathcal{Q} \mid FK(q) = x\}
Embodying Multi-Hand Manipulation Interactions
Collaborative Multi-Arm Manipulation: Current Ideas
We need a method that reasons over
-
Assignments
-
Redundant motions
Embodying Multi-Hand Manipulation Interactions
Collaborative Multi-Arm Manipulation: Current Ideas
We need a method that reasons over
-
Assignments
-
Redundant motions
Embodying Multi-Hand Manipulation Interactions
Collaborative Multi-Arm Manipulation: Current Ideas
We propose \(\text{OM-CBSA}\), a multi-arm embodiment approach.
-
\(\text{OM-A}^\star\): a single-robot planner that jointly reasons over redundancy and assignments.
-
\(\text{OM-CBSA}\): a multi-robot conflict-based
coordination module for negotiating
volumetric occupation and assignments.
Embodying Multi-Hand Manipulation Interactions
Collaborative Multi-Arm Manipulation: Current Ideas
Plan Object Motions
Generate
Manipulation Interactions
Embody
Manipulation Interactions
Plan Robot
Motions
- What are feasible motion primitives?
- How do we determine which contacts can be safely removed without compromising balance?
- How to compute freespace motions?
A*
Search
xECBS
- What is a good object representation for policy learning?
- How should we learn these interactions?
- How to transfer from "hands" to arms?
?
?
Collaborative Multi-Arm Manipulation: Current Ideas
Plan Object Motions
Generate
Manipulation Interactions
Embody
Manipulation Interactions
Plan Robot
Motions
- What are feasible motion primitives?
- How do we determine which contacts can be safely removed without compromising balance?
- How to compute freespace motions?
A*
Search
xECBS
- What is a good object representation for policy learning?
- How should we learn these interactions?
- How to transfer from "hands" to arms?
?
OM-CBSA
Collaborative Multi-Arm Manipulation: Current Ideas
Proposed Areas of Research
AI Generated, Grok
Collaborative Multi-Arm Manipulation
- Current ideas
- xECBS and A* for freespace planning
- OM-CBSA for policy embodiment
-
GCo as the collaboration framework.
- Expected focus
- Learning robust, flexible, and composable manipulation policies.
Coordinated Multi-Arm Manipulation
- Current ideas
- Research questions
- Expected focus
Our main goal:
-
Allow for multiple robots, each with their own visuomotor manipulation policy, to operate in a shared workspace.
- Ongoing collaboration with Abhishek Iyer
AI Generated, Grok
Coordinated Multi-Arm Manipulation
Draw on:
-
Successful Lifelong-MAPF algorithms
- In particular Rolling-Horizon Collision Resolution (RHCR).
- MMD
AI Generated, Grok
Coordinated Multi-Arm Manipulation: Current Ideas
Li, J., Tinka, A., Kiesel, S., Durham, J.W., Kumar, T.S. and Koenig, S. Lifelong multi-agent path finding in large-scale warehouses. AAAI 2021.
\mathcal{R}_1
\mathcal{R}_2
Constraint
"Action chunk"
\underbrace{\qquad \qquad \qquad}{}
Draw on:
-
Successful Lifelong-MAPF algorithms
- In particular Rolling-Horizon Collision Resolution (RHCR).
- MMD
AI Generated, Grok
Coordinated Multi-Arm Manipulation: Current Ideas
Li, J., Tinka, A., Kiesel, S., Durham, J.W., Kumar, T.S. and Koenig, S. Lifelong multi-agent path finding in large-scale warehouses. AAAI 2021.
\mathcal{R}_1
\mathcal{R}_2
"Action chunk"
\underbrace{\qquad \qquad \qquad}{}
MMD Repair
- Would space-time constraints destroy learned skills?
- What is the right scene representation?
-
So that confounders, like robots in the frame, are ignored?
-
So that confounders, like robots in the frame, are ignored?
- Could we guide models towards kinematically feasible regions of the configuration space?
AI Generated, Grok
Coordinated Multi-Arm Manipulation: Research Questions
Li, J., Tinka, A., Kiesel, S., Durham, J.W., Kumar, T.S. and Koenig, S. Lifelong multi-agent path finding in large-scale warehouses. AAAI 2021.
\mathcal{R}_1
\mathcal{R}_2
"Action chunk"
\underbrace{\qquad \qquad \qquad}{}
MMD Repair
Proposed Areas of Research
AI Generated, Grok
Collaborative Multi-Arm Manipulation
- Current ideas
- xECBS and A* for freespace planning
- OM-CBSA for policy embodiment
-
GCo as the collaboration framework.
- Expected focus
- Learning robust, flexible, and composable manipulation policies.
Coordinated Multi-Arm Manipulation
- Current ideas
- Produce action-chunks from visuomotor policies.
-
Deconflict action-chunks using MMD in a
rolling-horizon fashion.
- Expected focus
- Adapting MMD to manipulators in a way that maintains skill efficacy.
Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation
\underbrace{\qquad \qquad \qquad \quad \;}{}
Single-robot and single-objective model composition scales to larger problems
[ICLR 25, In Review 2026]
Thesis Roadmap
Plan what we can, and learn what we must.
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
Search-based algorithms are effective for multi-arm motion planning
[ICAPS 24, SoCS 24]
Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation
\underbrace{\qquad \qquad \qquad \quad \;}{}
Single-robot and single-objective model composition scales to larger problems
[ICLR 25, In Review 2026]
\underbrace{\qquad \qquad \qquad \quad \;}{}
Utilize established planning algorithms with new composable learned models for effective multi-arm manipulation.
Thesis Roadmap
Plan what we can, and learn what we must.
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
\underbrace{\qquad \qquad \qquad}{}
Search-based algorithms are effective for multi-arm motion planning
[ICAPS 24, SoCS 24]
Timeline
Multi-Arm Policy Embodiment
~2 months
Paper writing, completing experiments, and deeper analysis.
~3 months
Work on (and support for) policy learning and coordination mechanisms.
Multi-Arm Coordination
Multi-Arm Collaboration
~3 months
Develop interaction models in simulation.
~2 months
Set up real-world robot system.
~3 months
Creating algorithmic planning+learning framework, and writing.
\mathcal{I}
a
Thank Yous
Max
Jiaoyang
Itamar
Shivam
Rishi
Ram
Federico
Philip
Zhe
Naveed










Thesis Roadmap
Thank you for your attention! Questions?
Multi-Robot-Arm Motion Planning
Interleaving Planning and Learning on the Plane
Interleaving Planning and Learning for
Multi-Arm Manipulation

[Thesis Proposal] Planning and Learning
By yorai
